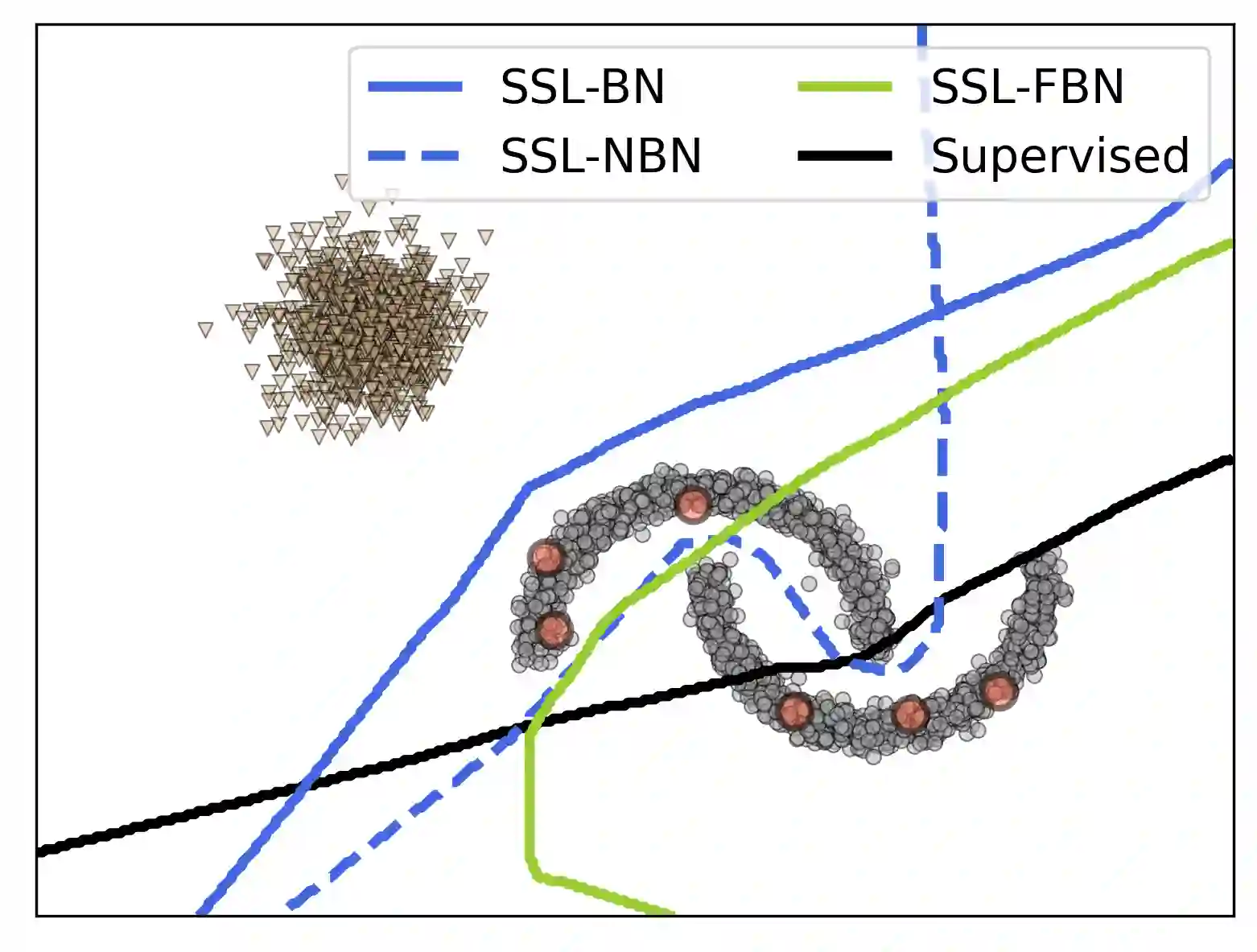
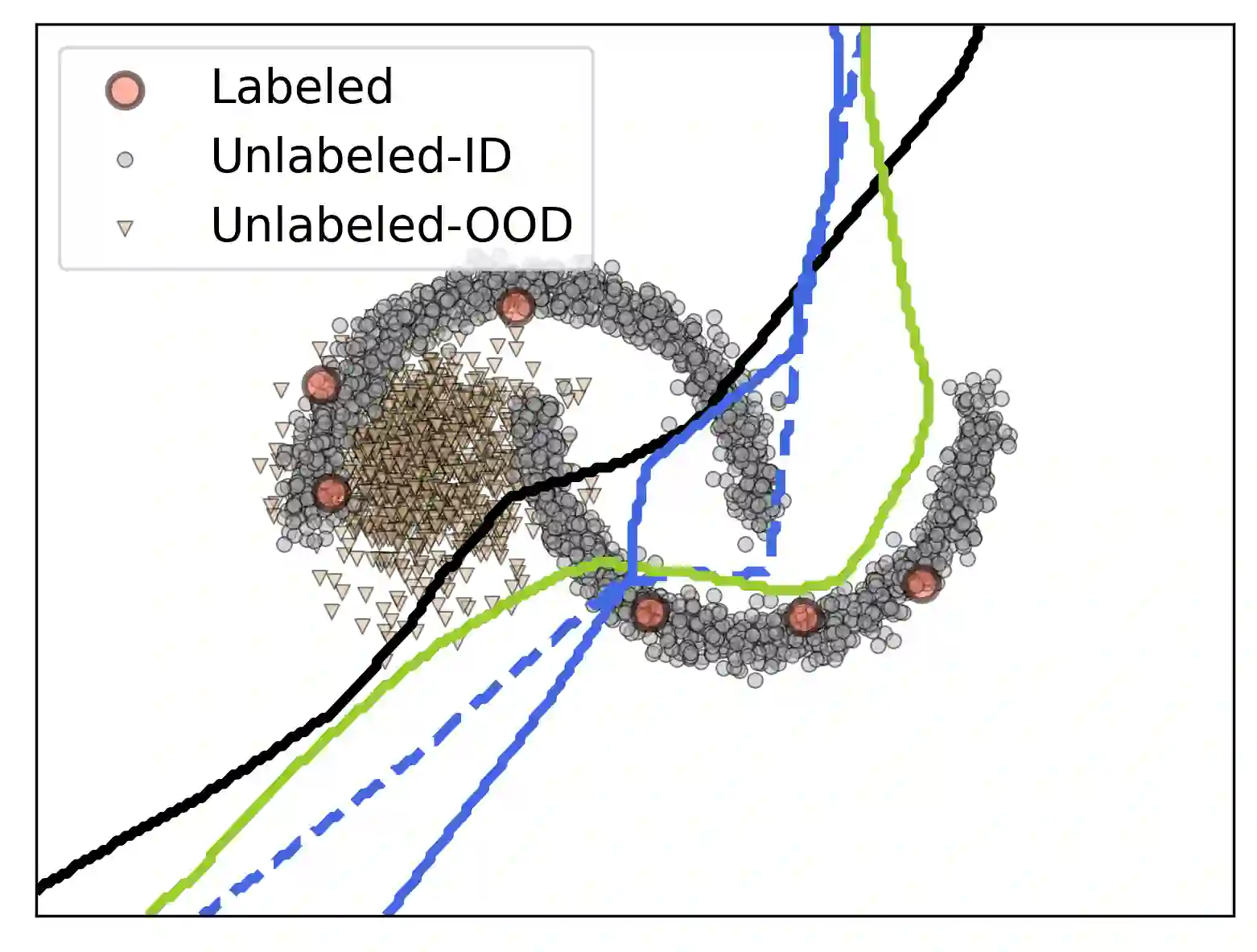
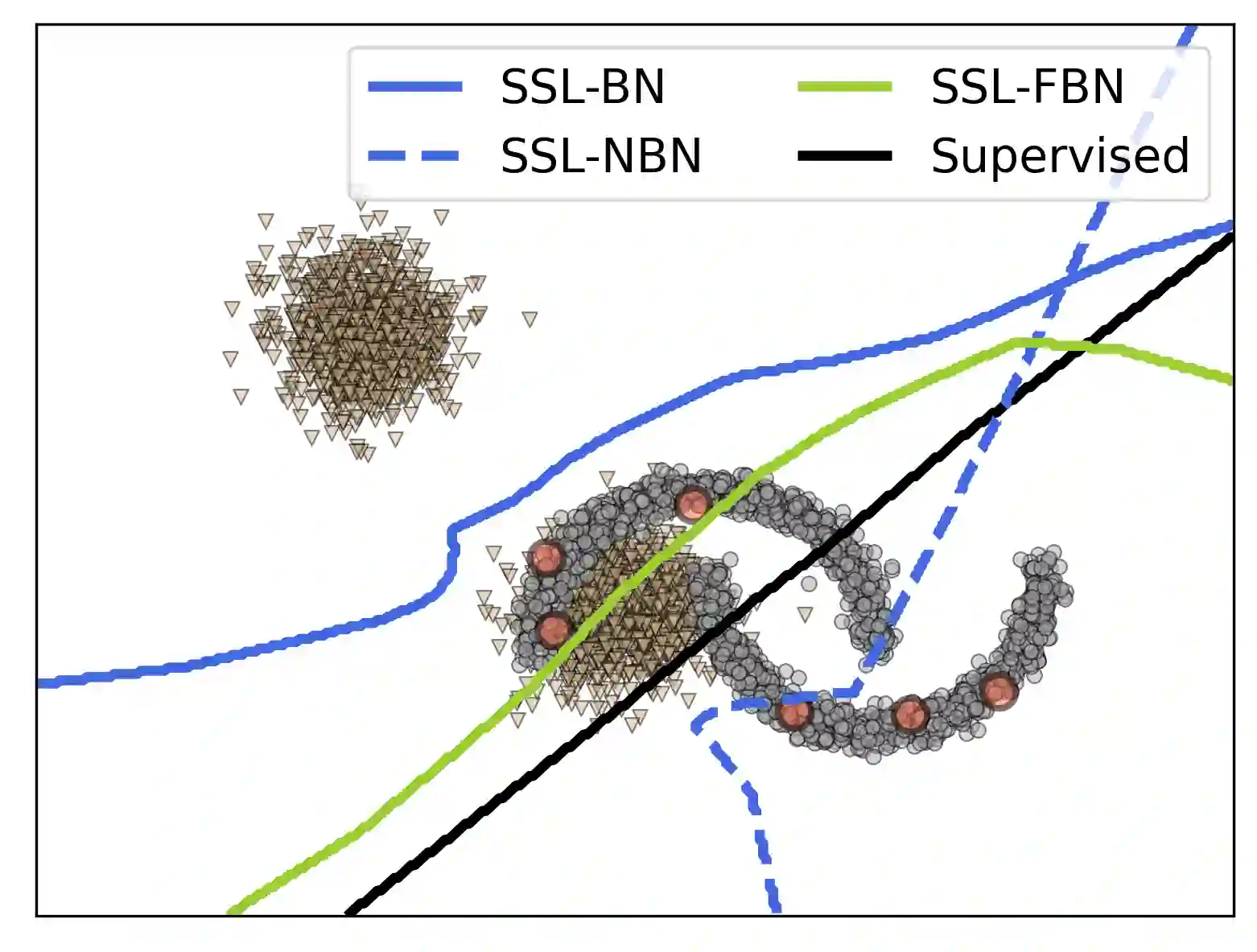
Recent semi-supervised learning algorithms have demonstrated greater success with higher overall performance due to better-unlabeled data representations. Nonetheless, recent research suggests that the performance of the SSL algorithm can be degraded when the unlabeled set contains out-of-distribution examples (OODs). This work addresses the following question: How do out-of-distribution (OOD) data adversely affect semi-supervised learning algorithms? To answer this question, we investigate the critical causes of OOD's negative effect on SSL algorithms. In particular, we found that 1) certain kinds of OOD data instances that are close to the decision boundary have a more significant impact on performance than those that are further away, and 2) Batch Normalization (BN), a popular module, may degrade rather than improve performance when the unlabeled set contains OODs. In this context, we developed a unified weighted robust SSL framework that can be easily extended to many existing SSL algorithms and improve their robustness against OODs. More specifically, we developed an efficient bi-level optimization algorithm that could accommodate high-order approximations of the objective and scale to multiple inner optimization steps to learn a massive number of weight parameters while outperforming existing low-order approximations of bi-level optimization. Further, we conduct a theoretical study of the impact of faraway OODs in the BN step and propose a weighted batch normalization (WBN) procedure for improved performance. Finally, we discuss the connection between our approach and low-order approximation techniques. Our experiments on synthetic and real-world datasets demonstrate that our proposed approach significantly enhances the robustness of four representative SSL algorithms against OODs compared to four state-of-the-art robust SSL strategies.
翻译:近期,半监督学习算法因对未标注数据表示能力的提升而展现出更高的整体性能。然而,最新研究表明,当未标注数据集包含分布外样本时,半监督学习算法的性能可能下降。本研究旨在探讨以下问题:分布外数据如何对半监督学习算法产生不利影响?为回答该问题,我们深入分析了分布外数据对半监督学习算法负面效应的关键成因。具体而言,我们发现:1)决策边界附近的特定类型分布外数据实例对性能的影响显著大于远离边界的实例;2)当未标注集包含分布外样本时,批归一化这一流行模块可能反而降低性能而非提升性能。在此背景下,我们提出了一种统一加权鲁棒半监督学习框架,该框架可便捷地扩展到现有多种半监督学习算法中,并增强其对分布外数据的鲁棒性。具体地,我们开发了一种高效的双层优化算法,该算法能够适应目标函数的高阶近似,支持多步内层优化以学习海量权重参数,其性能优于现有双层优化的低阶近似方法。此外,我们理论分析了远离边界分布外样本对批归一化步骤的影响,并提出加权批归一化方案以提升性能。最后,我们探讨了所提方法与低阶近似技术之间的关联。在合成数据集与真实数据集上的实验表明,与四种前沿鲁棒半监督学习策略相比,我们的方法显著提升了四种代表性半监督学习算法对分布外数据的鲁棒性。