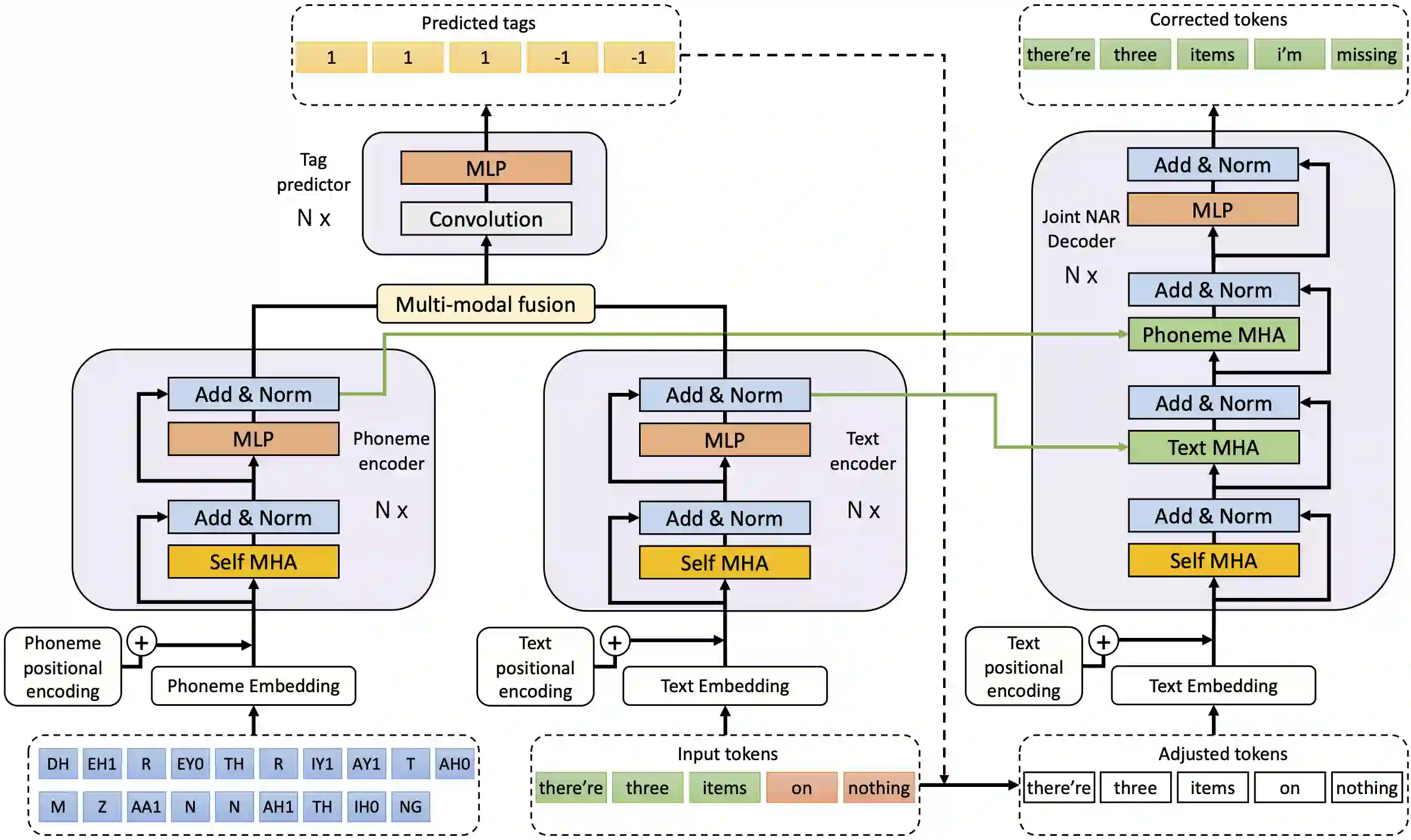
Speech-to-text errors made by automatic speech recognition (ASR) systems negatively impact downstream models. Error correction models as a post-processing text editing method have been recently developed for refining the ASR outputs. However, efficient models that meet the low latency requirements of industrial grade production systems have not been well studied. We propose PATCorrect-a novel non-autoregressive (NAR) approach based on multi-modal fusion leveraging representations from both text and phoneme modalities, to reduce word error rate (WER) and perform robustly with varying input transcription quality. We demonstrate that PATCorrect consistently outperforms state-of-the-art NAR method on English corpus across different upstream ASR systems, with an overall 11.62% WER reduction (WERR) compared to 9.46% WERR achieved by other methods using text only modality. Besides, its inference latency is at tens of milliseconds, making it ideal for systems with low latency requirements.
翻译:自动语音识别(ASR)系统产生的语音转文本错误会对下游模型产生负面影响。错误纠正模型作为一种后处理文本编辑方法,近年来已被开发用于优化ASR输出。然而,能够满足工业级生产系统低延迟需求的高效模型尚未得到充分研究。我们提出PATCorrect——一种基于多模态融合的新型非自回归(NAR)方法,利用文本和音素两种模态的表示来降低词错误率(WER),并在不同输入转录质量下实现稳健性能。我们证明,在不同上游ASR系统的英文语料上,PATCorrect始终优于最先进的NAR方法,整体词错误率降低(WERR)达11.62%,而仅使用文本模态的其他方法仅实现9.46%的WERR。此外,其推理延迟仅为数十毫秒,使其成为低延迟需求系统的理想选择。