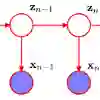
Time-series models typically assume untainted and legitimate streams of data. However, a self-interested adversary may have incentive to corrupt this data, thereby altering a decision maker's inference. Within the broader field of adversarial machine learning, this research provides a novel, probabilistic perspective toward the manipulation of hidden Markov model inferences via corrupted data. In particular, we provision a suite of corruption problems for filtering, smoothing, and decoding inferences leveraging an adversarial risk analysis approach. Multiple stochastic programming models are set forth that incorporate realistic uncertainties and varied attacker objectives. Three general solution methods are developed by alternatively viewing the problem from frequentist and Bayesian perspectives. The efficacy of each method is illustrated via extensive, empirical testing. The developed methods are characterized by their solution quality and computational effort, resulting in a stratification of techniques across varying problem-instance architectures. This research highlights the weaknesses of hidden Markov models under adversarial activity, thereby motivating the need for robustification techniques to ensure their security.
翻译:时间序列模型通常假设数据流未被污染且来源合法。然而,出于自身利益考虑的攻击者可能有意污染这些数据,从而改变决策者的推断。在对抗性机器学习的更广泛领域中,本研究提供了一种新颖的概率视角,探讨如何通过受污染数据操纵隐马尔可夫模型推断。具体而言,我们利用对抗风险分析方法,针对滤波、平滑和译码推断设计了一系列污染问题。提出了多个随机规划模型,这些模型融合了现实中的不确定性及多样化的攻击者目标。通过从频率学派和贝叶斯学派视角交替审视问题,开发了三种通用求解方法。大量实证测试展示了每种方法的有效性。所开发的方法根据其求解质量与计算成本进行了特征化,从而形成了针对不同问题实例架构的技术分层。本研究揭示了隐马尔可夫模型在对抗性活动下的脆弱性,进而凸显了采用鲁棒化技术以确保其安全性的必要性。