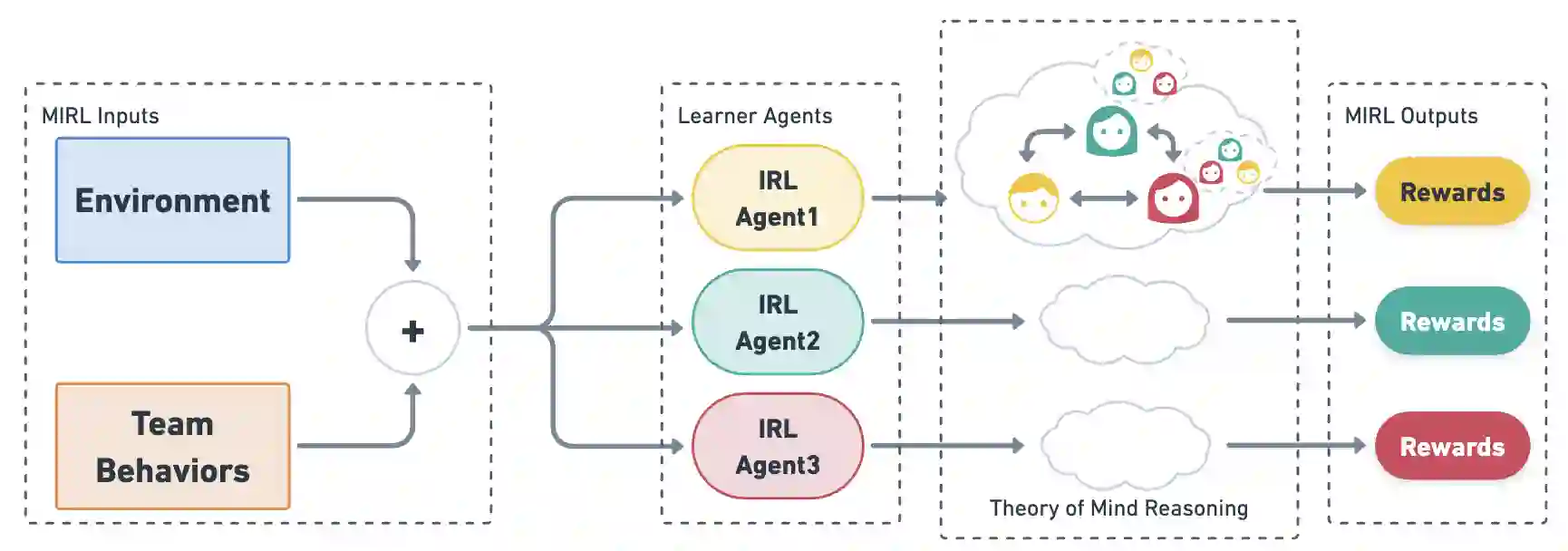
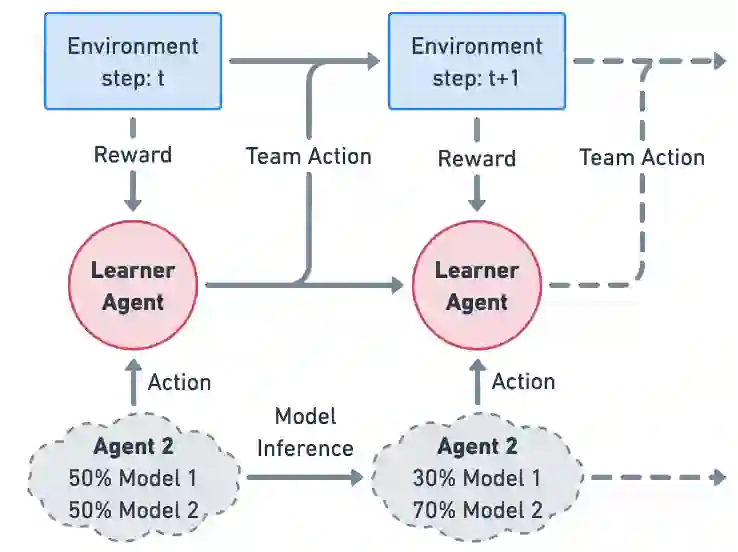
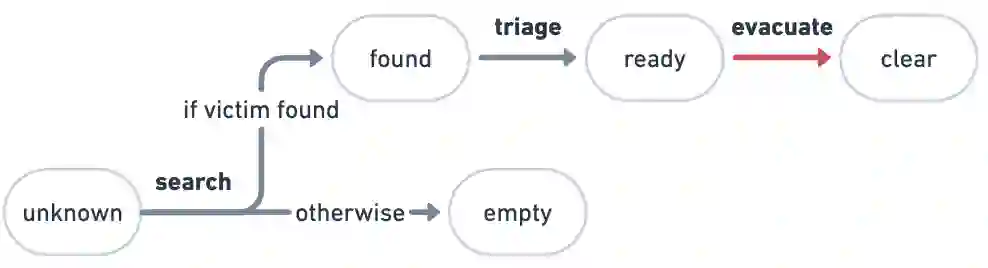
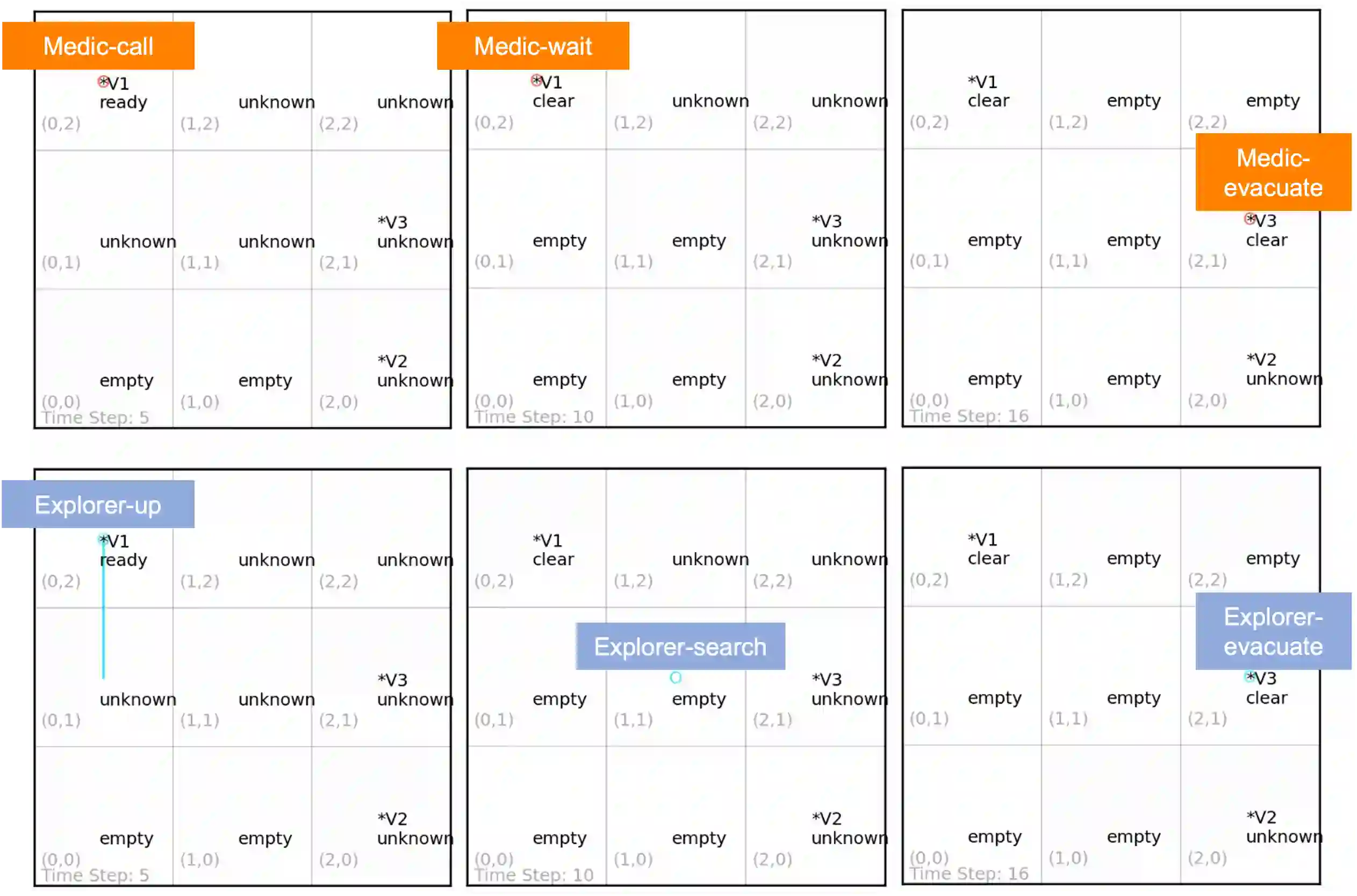
We approach the problem of understanding how people interact with each other in collaborative settings, especially when individuals know little about their teammates, via Multiagent Inverse Reinforcement Learning (MIRL), where the goal is to infer the reward functions guiding the behavior of each individual given trajectories of a team's behavior during some task. Unlike current MIRL approaches, we do not assume that team members know each other's goals a priori; rather, that they collaborate by adapting to the goals of others perceived by observing their behavior, all while jointly performing a task. To address this problem, we propose a novel approach to MIRL via Theory of Mind (MIRL-ToM). For each agent, we first use ToM reasoning to estimate a posterior distribution over baseline reward profiles given their demonstrated behavior. We then perform MIRL via decentralized equilibrium by employing single-agent Maximum Entropy IRL to infer a reward function for each agent, where we simulate the behavior of other teammates according to the time-varying distribution over profiles. We evaluate our approach in a simulated 2-player search-and-rescue operation where the goal of the agents, playing different roles, is to search for and evacuate victims in the environment. Our results show that the choice of baseline profiles is paramount to the recovery of the ground-truth rewards, and that MIRL-ToM is able to recover the rewards used by agents interacting both with known and unknown teammates.
翻译:我们通过多智能体逆强化学习(MIRL)研究个体在协作场景中如何相互理解的问题,尤其是在个体对队友了解有限的情况下。该任务的目标是根据团队在某一任务中表现出的行为轨迹,推断指导每个个体行为的奖励函数。与现有MIRL方法不同,我们未假设团队成员事先了解彼此的目标;相反,他们通过观察他人行为感知其目标并相互适应,同时共同执行任务。针对这一问题,我们提出了一种基于心智理论(Theory of Mind, ToM)的MIRL新方法(MIRL-ToM)。首先,对每个智能体,我们利用ToM推理,根据其展现的行为估计其基础奖励配置的后验分布;随后,通过分散均衡进行MIRL:采用单智能体最大熵逆强化学习(Maximum Entropy IRL)推断每个智能体的奖励函数,并基于随时间变化的配置分布模拟其他队友的行为。我们在一个模拟的双人搜索与救援任务中评估该方法,其中扮演不同角色的智能体需在环境中搜寻并疏散受害者。结果表明,基础奖励配置的选择对恢复真实奖励至关重要,且MIRL-ToM能够成功恢复与已知及未知队友交互的智能体所采用的奖励函数。