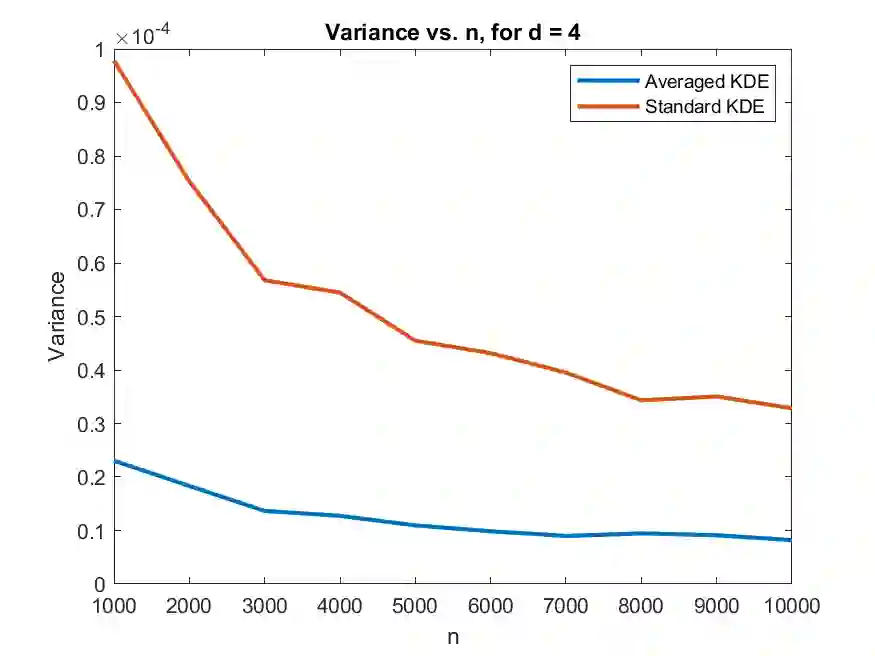
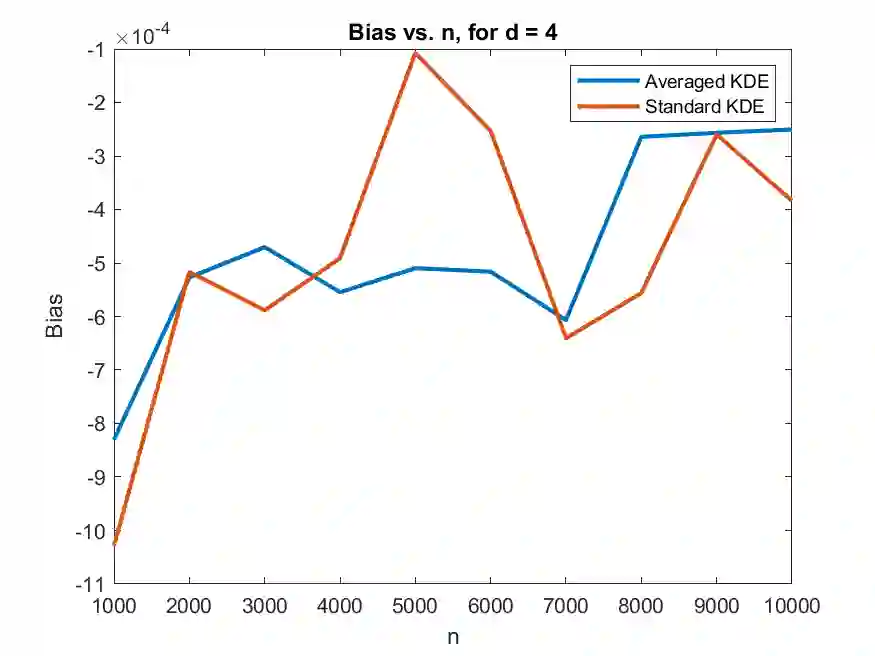
Permutation invariance is among the most common symmetry that can be exploited to simplify complex problems in machine learning (ML). There has been a tremendous surge of research activities in building permutation invariant ML architectures. However, less attention is given to: (1) how to statistically test for permutation invariance of coordinates in a random vector where the dimension is allowed to grow with the sample size; (2) how to leverage permutation invariance in estimation problems and how does it help reduce dimensions. In this paper, we take a step back and examine these questions in several fundamental problems: (i) testing the assumption of permutation invariance of multivariate distributions; (ii) estimating permutation invariant densities; (iii) analyzing the metric entropy of permutation invariant function classes and compare them with their counterparts without imposing permutation invariance; (iv) deriving an embedding of permutation invariant reproducing kernel Hilbert spaces for efficient computation. In particular, our methods for (i) and (iv) are based on a sorting trick and (ii) is based on an averaging trick. These tricks substantially simplify the exploitation of permutation invariance.
翻译:置换不变性是机器学习中可利用的最常见对称性之一,近年来构建置换不变性机器学习架构的研究活动激增。然而,以下问题受到的关注较少:(1) 如何对随机向量中坐标的置换不变性进行统计检验(允许维度随样本量增长);(2) 如何在估计问题中利用置换不变性及其降维机制。本文从基础视角审视了这些关键问题:(i) 多元分布置换不变性假设的检验;(ii) 置换不变密度估计;(iii) 置换不变函数类的度量熵分析及其与未施加置换不变性的函数类对比;(iv) 面向高效计算的置换不变再生核希尔伯特空间嵌入推导。特别地,问题(i)与(iv)的方法基于排序技巧,问题(ii)基于平均化技巧,这些技巧显著简化了置换不变性的利用过程。