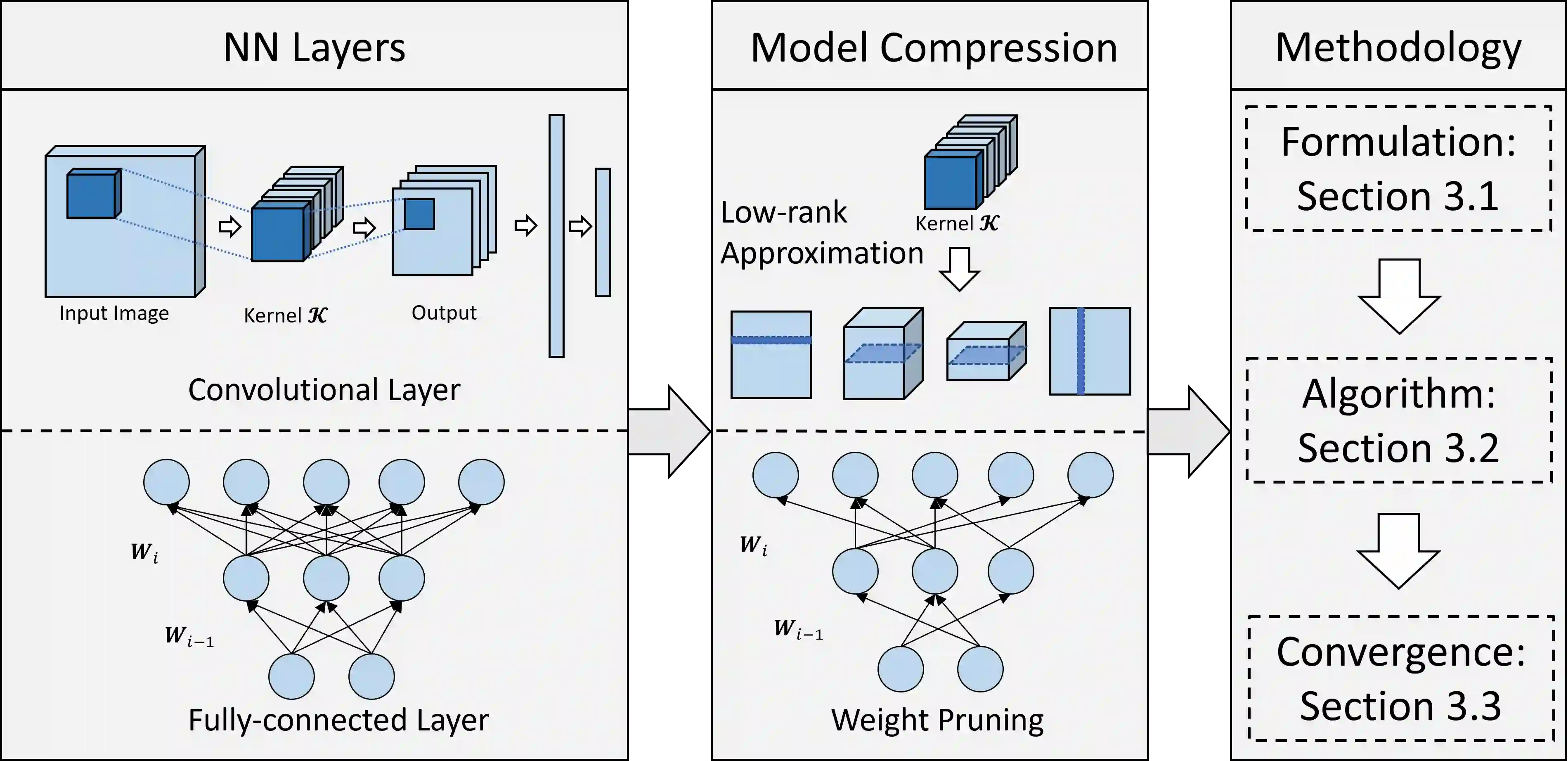
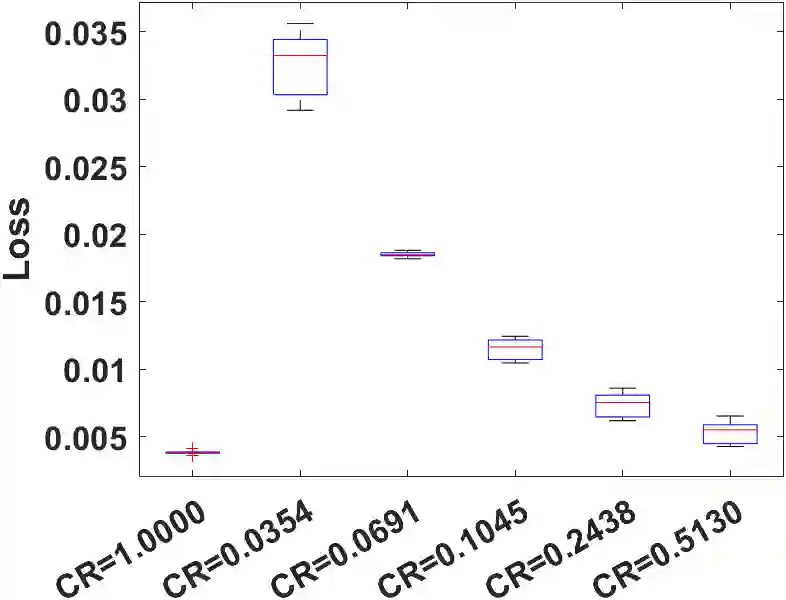
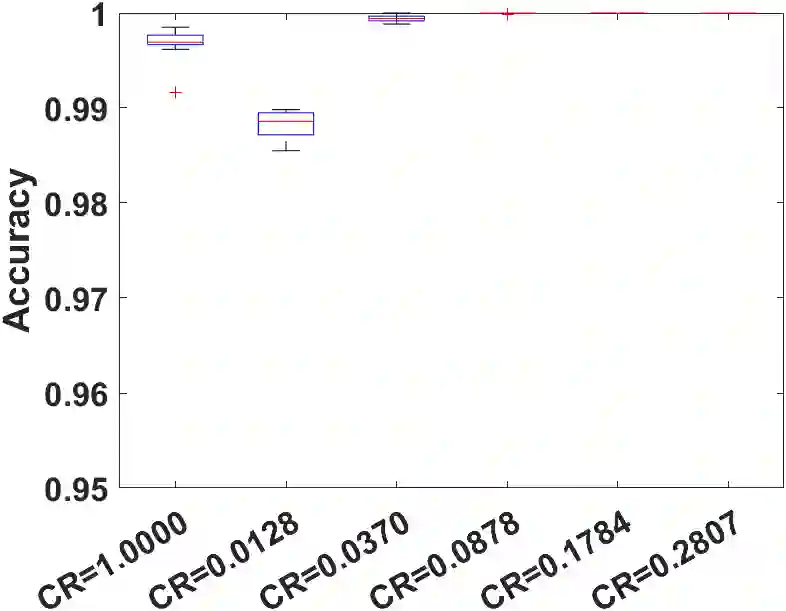
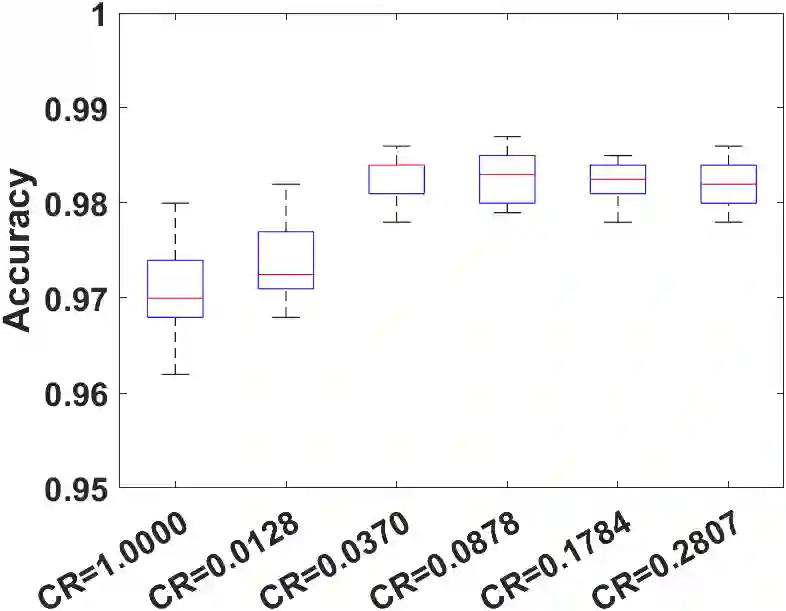
Model compression is a crucial part of deploying neural networks (NNs), especially when the memory and storage of computing devices are limited in many applications. This paper focuses on two model compression techniques: low-rank approximation and weight pruning in neural networks, which are very popular nowadays. However, training NN with low-rank approximation and weight pruning always suffers significant accuracy loss and convergence issues. In this paper, a holistic framework is proposed for model compression from a novel perspective of nonconvex optimization by designing an appropriate objective function. Then, we introduce NN-BCD, a block coordinate descent (BCD) algorithm to solve the nonconvex optimization. One advantage of our algorithm is that an efficient iteration scheme can be derived with closed-form, which is gradient-free. Therefore, our algorithm will not suffer from vanishing/exploding gradient problems. Furthermore, with the Kurdyka-{\L}ojasiewicz (K{\L}) property of our objective function, we show that our algorithm globally converges to a critical point at the rate of O(1/k), where k denotes the number of iterations. Lastly, extensive experiments with tensor train decomposition and weight pruning demonstrate the efficiency and superior performance of the proposed framework. Our code implementation is available at https://github.com/ChenyangLi-97/NN-BCD
翻译:模型压缩是部署神经网络的关键环节,尤其在计算设备存储与内存受限的应用场景中。本文聚焦于两类主流模型压缩技术:低秩近似与权重剪枝。然而,采用低秩近似与权重剪枝训练的神经网络常面临显著的精度损失与收敛问题。为此,本文从非凸优化的新颖视角出发,通过设计恰当的目标函数,提出一种整体性模型压缩框架。随后引入NN-BCD算法——一种基于块坐标下降(BCD)的非凸优化求解方法。该算法的优势在于可通过闭式解实现高效迭代格式,且无需计算梯度,从而避免梯度消失/爆炸问题。进一步,基于目标函数的Kurdyka-Łojasiewicz(KŁ)性质,我们证明算法以O(1/k)的速率全局收敛至临界点(k为迭代次数)。最后,通过张量列车分解与权重剪枝的广泛实验,验证了所提框架的高效性与优越性能。代码实现已发布于https://github.com/ChenyangLi-97/NN-BCD