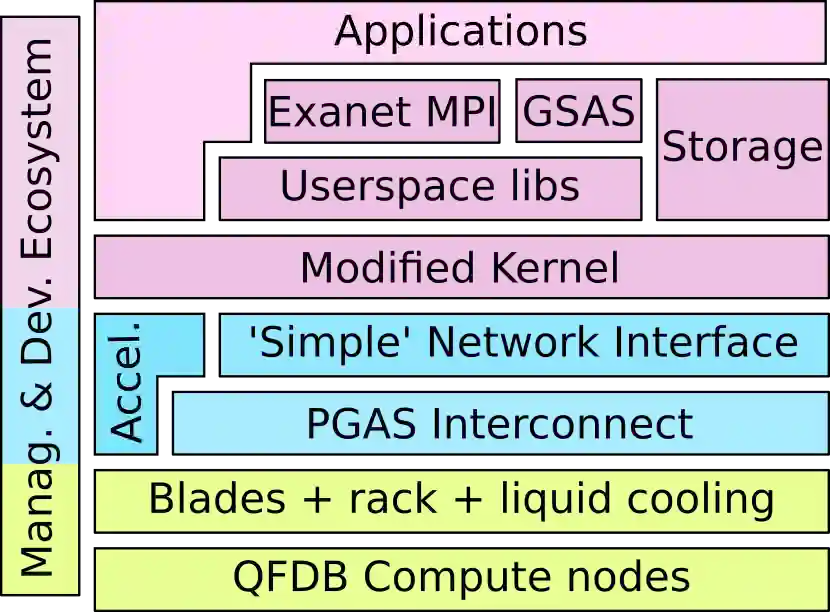
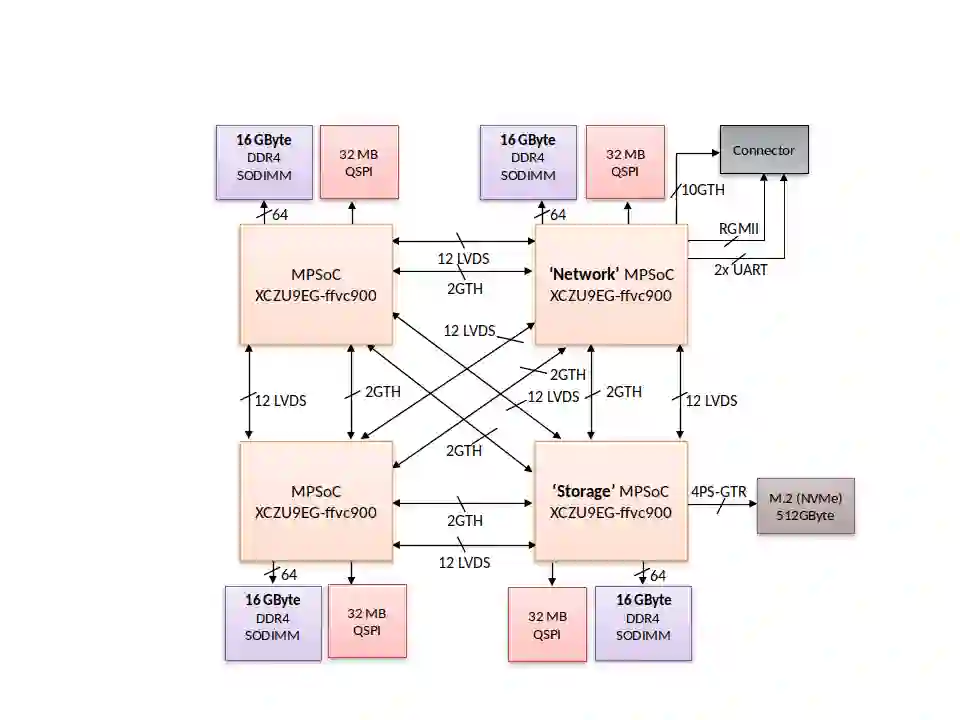
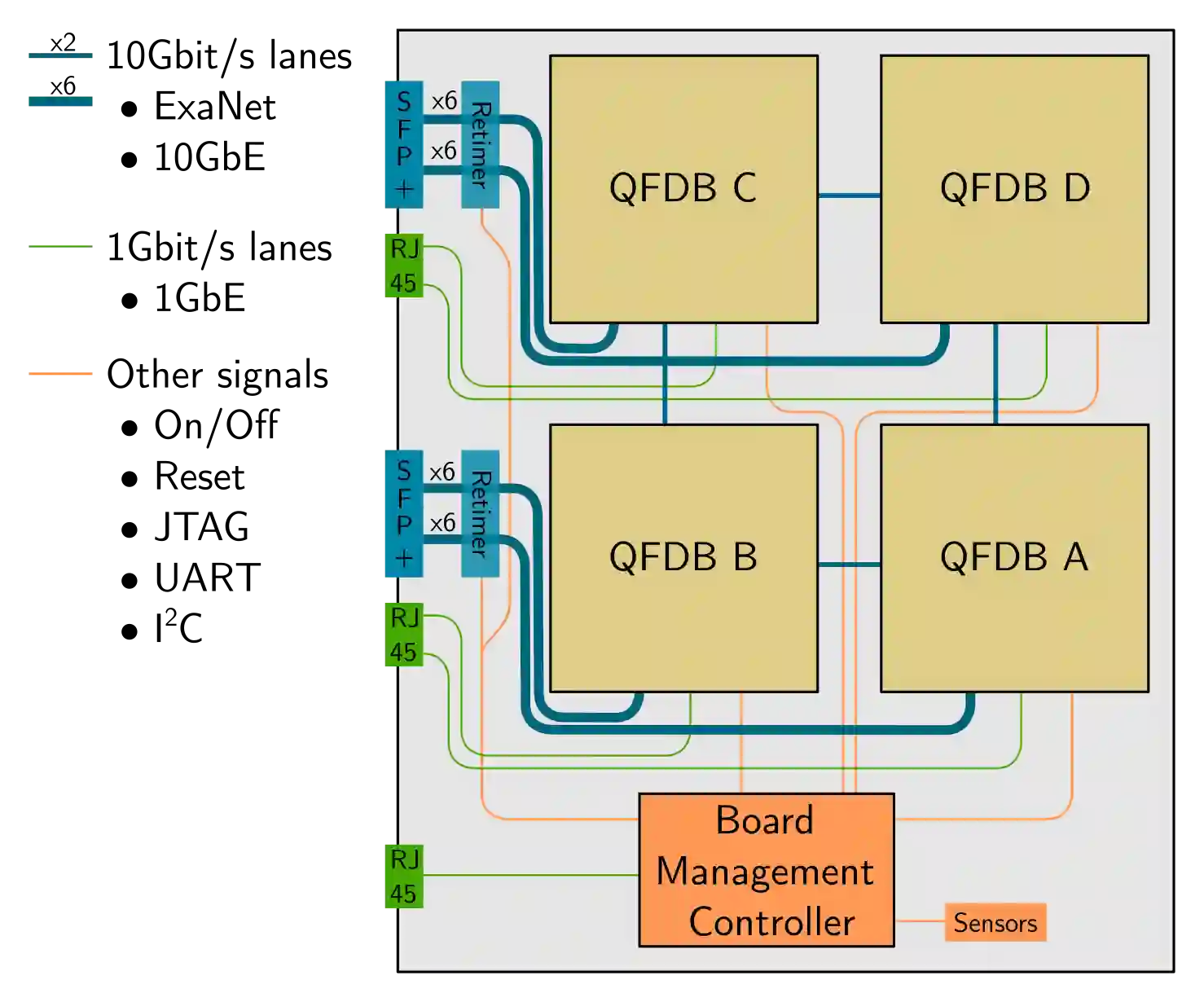
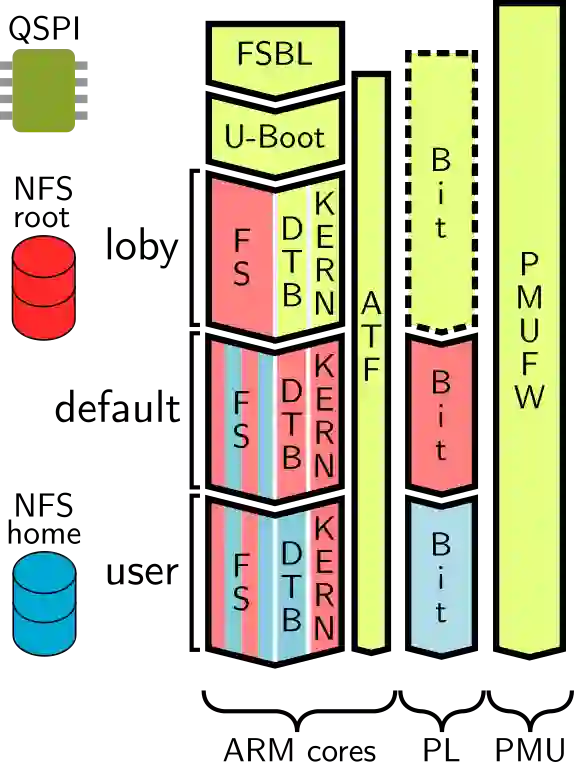
We present and evaluate the ExaNeSt Prototype, a liquid-cooled rack prototype consisting of 256 Xilinx ZU9EG MPSoCs, 4 TBytes of DRAM, 16 TBytes of SSD, and configurable interconnection 10-Gbps hardware. We developed this testbed in 2016-2019 to validate the flexibility of FPGAs for experimenting with efficient hardware support for HPC communication among tens of thousands of processors and accelerators in the quest towards Exascale systems and beyond. We present our key design choices reagrding overall system architecture, PCBs and runtime software, and summarize insights resulting from measurement and analysis. Of particular note, our custom interconnect includes a low-cost low-latency network interface, offering user-level zero-copy RDMA, which we have tightly coupled with the ARMv8 processors in the MPSoCs. We have developed a system software runtime on top of these features, and have been able to run MPI. We have evaluated our testbed through MPI microbenchmarks, mini, and full MPI applications. Single hop, one way latency is $1.3$~$\mu$s; approximately $0.47$~$\mu$s out of these are attributed to network interface and the user-space library that exposes its functionality to the runtime. Latency over longer paths increases as expected, reaching $2.55$~$\mu$s for a five-hop path. Bandwidth tests show that, for a single hop, link utilization reaches $82\%$ of the theoretical capacity. Microbenchmarks based on MPI collectives reveal that broadcast latency scales as expected when the number of participating ranks increases. We also implemented a custom Allreduce accelerator in the network interface, which reduces the latency of such collectives by up to $88\%$. We assess performance scaling through weak and strong scaling tests for HPCG, LAMMPS, and the miniFE mini application; for all these tests, parallelization efficiency is at least $69\%$, or better.
翻译:我们介绍并评估了ExaNeSt原型——一款液冷机架原型,包含256个赛灵思ZU9EG MPSoC、4 TB DRAM、16 TB固态硬盘及可配置的10 Gbps互连硬件。该测试平台于2016-2019年间开发,旨在验证FPGA在支持高效HPC通信硬件方面的灵活性,以探索由数万处理器和加速器组成的百亿亿次及更高性能系统。我们阐述了整体系统架构、PCB及运行时软件的关键设计决策,并总结了测量与分析所得的关键洞见。特别指出,我们的定制互连包含低成本低延迟网络接口,提供用户级零拷贝RDMA功能,且已与MPSoC中的ARMv8处理器紧密耦合。基于这些特性,我们开发了系统软件运行时,并成功运行了MPI。通过MPI微基准测试、迷你应用及完整MPI应用对测试平台进行了评估。单跳单向延迟为1.3微秒,其中约0.47微秒来自网络接口及其功能暴露给运行时的用户空间库。更长路径的延迟按预期增长,五跳路径延迟达2.55微秒。带宽测试显示,单跳链路利用率可达理论容量的82%。基于MPI集合通信的微基准测试表明,随着参与层级增加,广播延迟呈预期增长。我们还在网络接口中实现了自定义Allreduce加速器,使此类集合延迟降低高达88%。通过HPCG、LAMMPS及miniFE迷你应用的弱扩展与强扩展测试评估性能缩放:所有测试中并行化效率至少达到69%或更高。