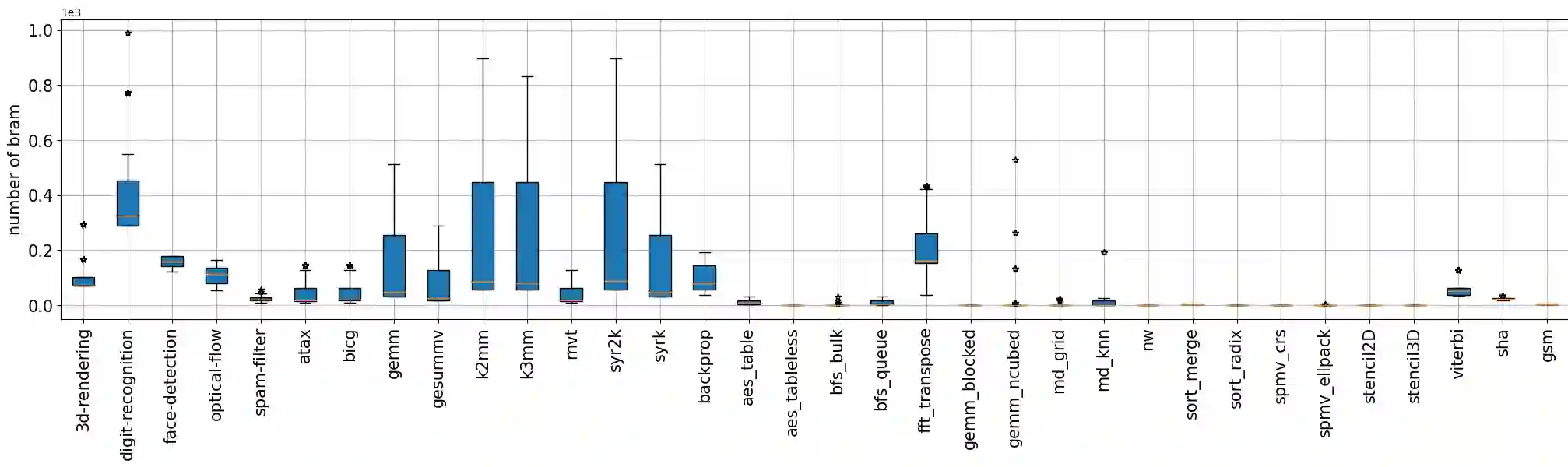
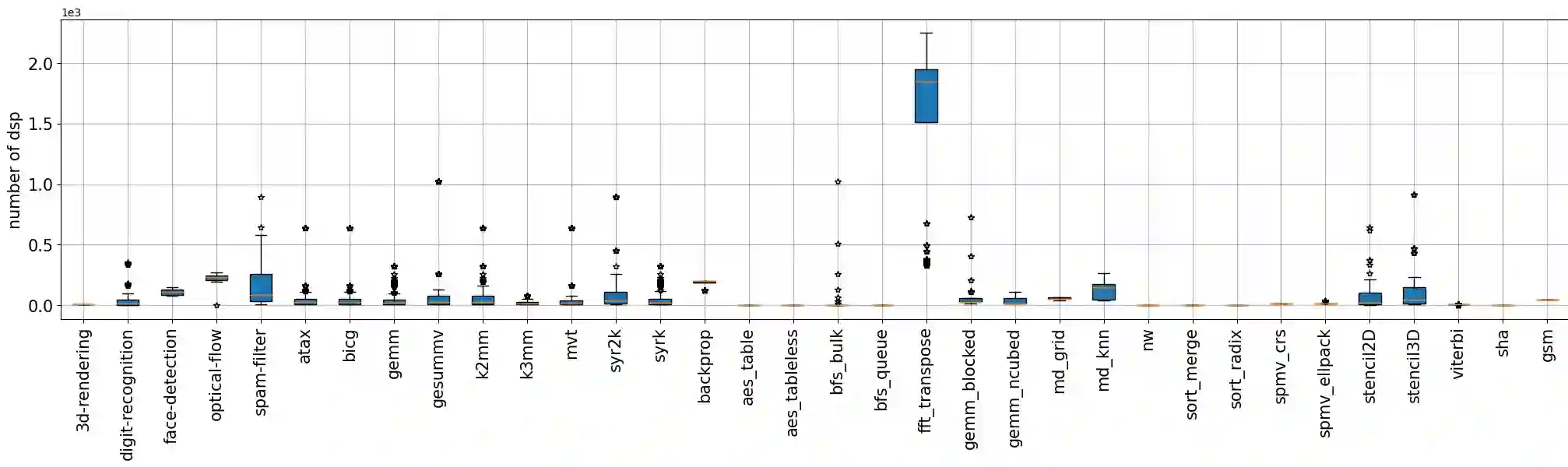
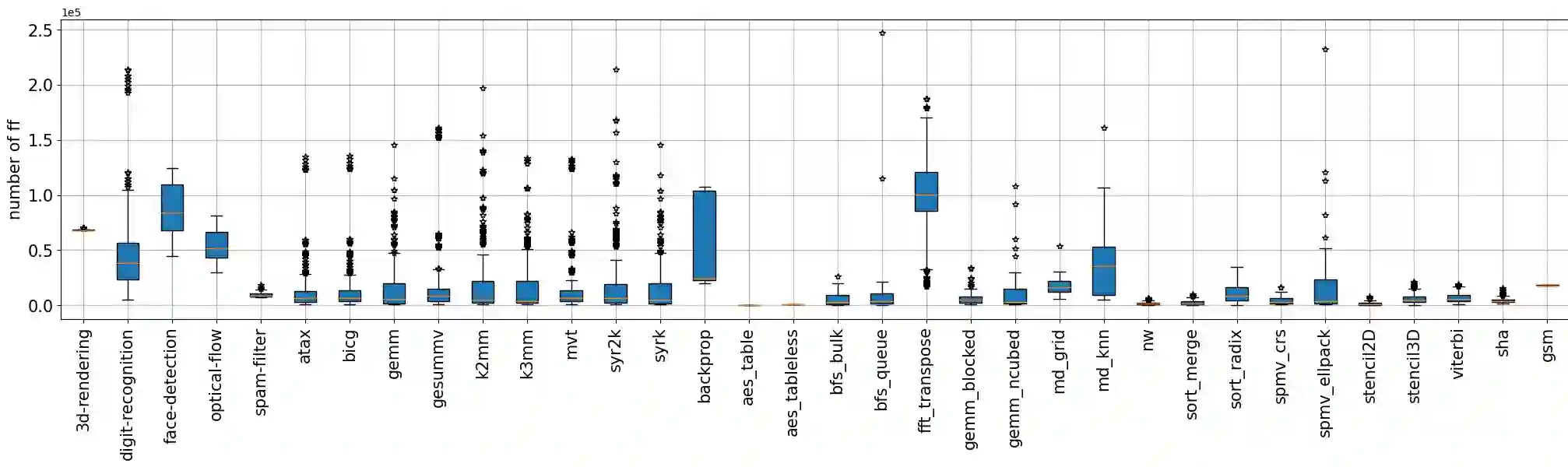
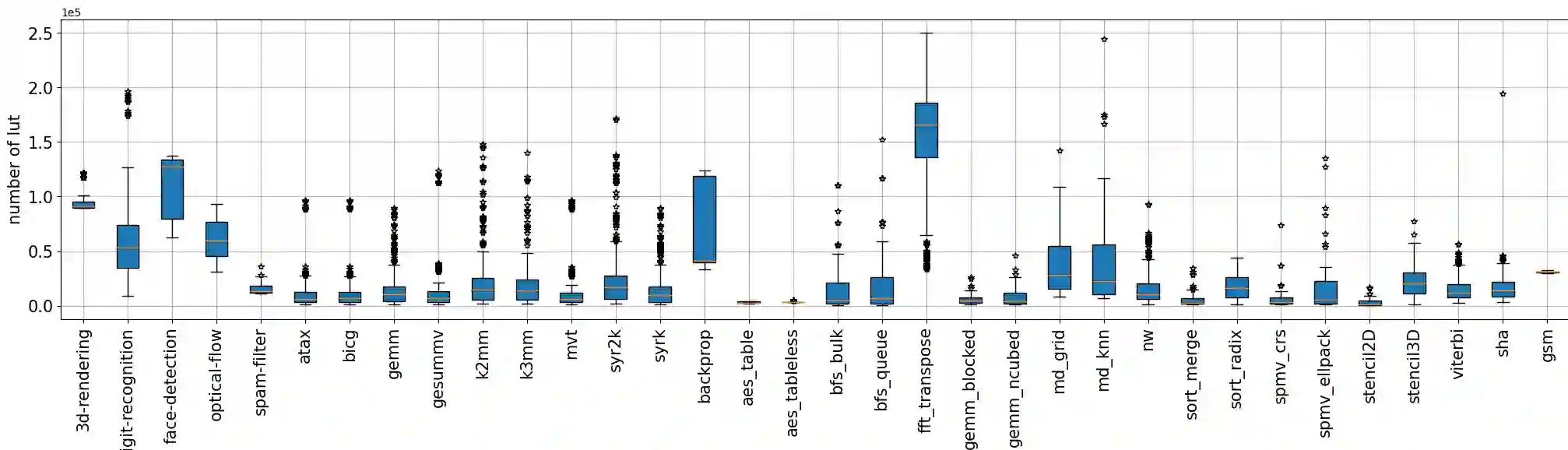
Machine Learning (ML) has been widely adopted in design exploration using high level synthesis (HLS) to give a better and faster performance, and resource and power estimation at very early stages for FPGA-based design. To perform prediction accurately, high-quality and large-volume datasets are required for training ML models.This paper presents a dataset for ML-assisted FPGA design using HLS, called HLSDataset. The dataset is generated from widely used HLS C benchmarks including Polybench, Machsuite, CHStone and Rossetta. The Verilog samples are generated with a variety of directives including loop unroll, loop pipeline and array partition to make sure optimized and realistic designs are covered. The total number of generated Verilog samples is nearly 9,000 per FPGA type. To demonstrate the effectiveness of our dataset, we undertake case studies to perform power estimation and resource usage estimation with ML models trained with our dataset. All the codes and dataset are public at the github repo.We believe that HLSDataset can save valuable time for researchers by avoiding the tedious process of running tools, scripting and parsing files to generate the dataset, and enable them to spend more time where it counts, that is, in training ML models.
翻译:机器学习(ML)已被广泛用于基于高级综合(HLS)的设计空间探索中,以在FPGA设计的早期阶段实现更优、更快的性能以及资源和功耗估计。为进行准确预测,需要高质量、大规模的数据集来训练ML模型。本文提出一个面向ML辅助FPGA设计的数据集,名为HLSDataset。该数据集源自广泛使用的HLS C语言基准测试集,包括Polybench、Machsuite、CHStone和Rossetta。通过应用循环展开、循环流水线和数组划分等多种编译指令生成Verilog样本,以确保覆盖优化且现实的设计。每种FPGA类型生成的Verilog样本总数近9000个。为展示该数据集的有效性,我们开展案例研究,使用基于该数据集训练的ML模型进行功耗估计和资源使用估计。所有代码和数据集已公开于GitHub仓库。我们相信,HLSDataset能帮助研究人员省去运行工具、编写脚本和解析文件以生成数据集的繁琐流程,从而节省宝贵时间,使其能将更多精力投入到关键环节——即训练ML模型上。