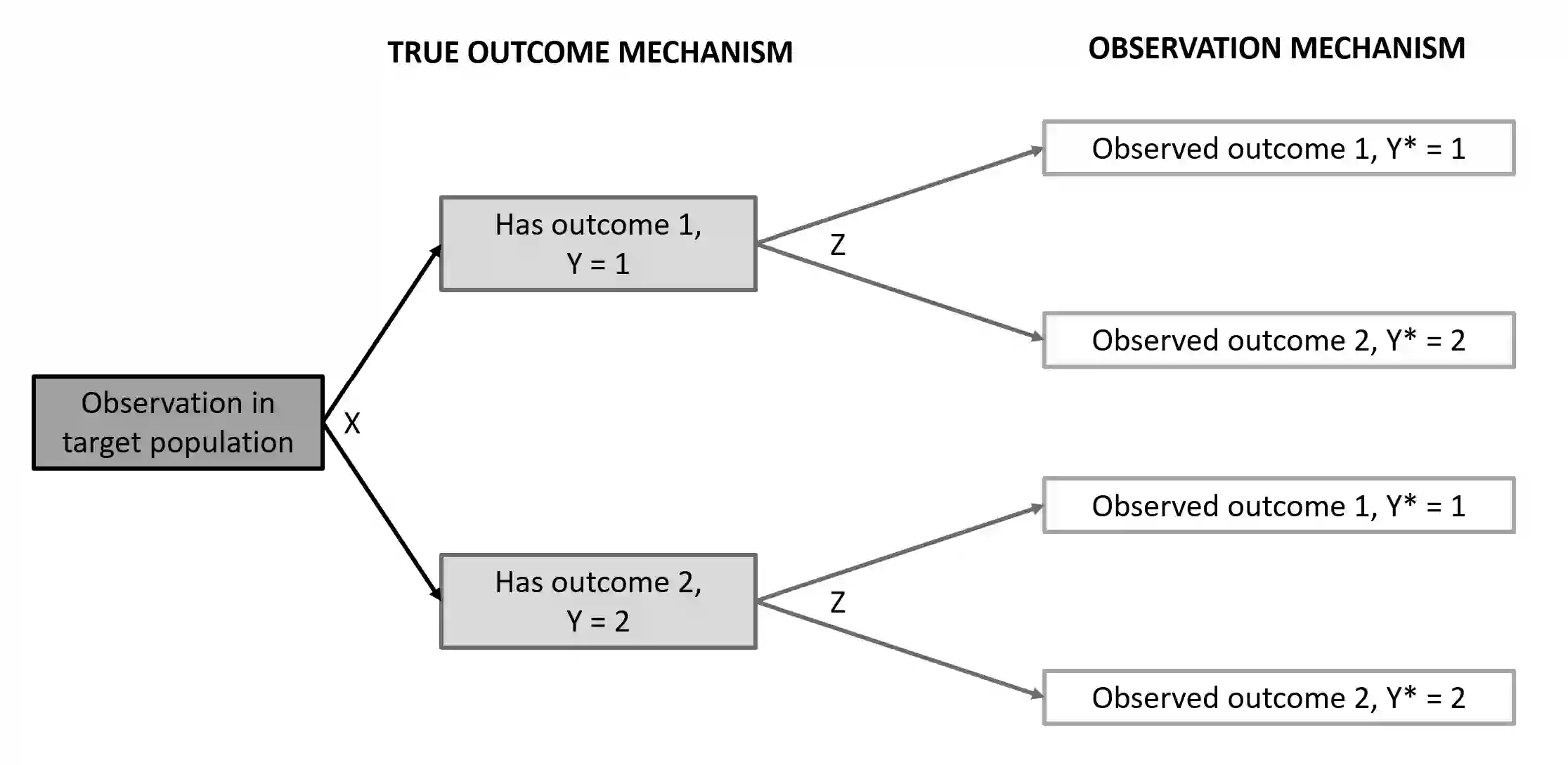
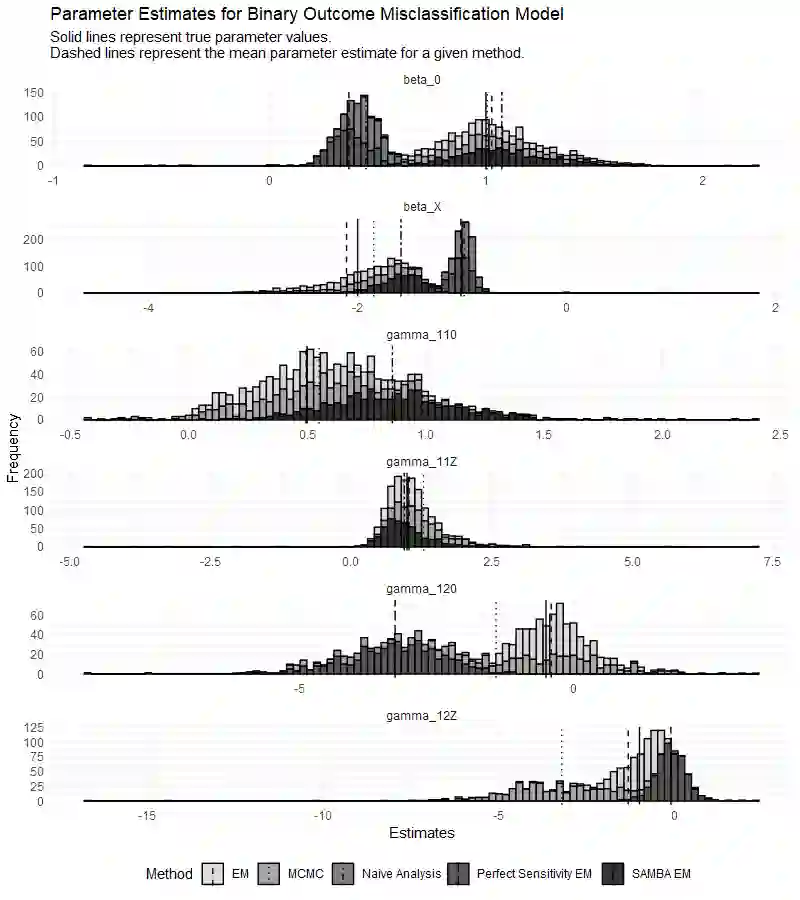
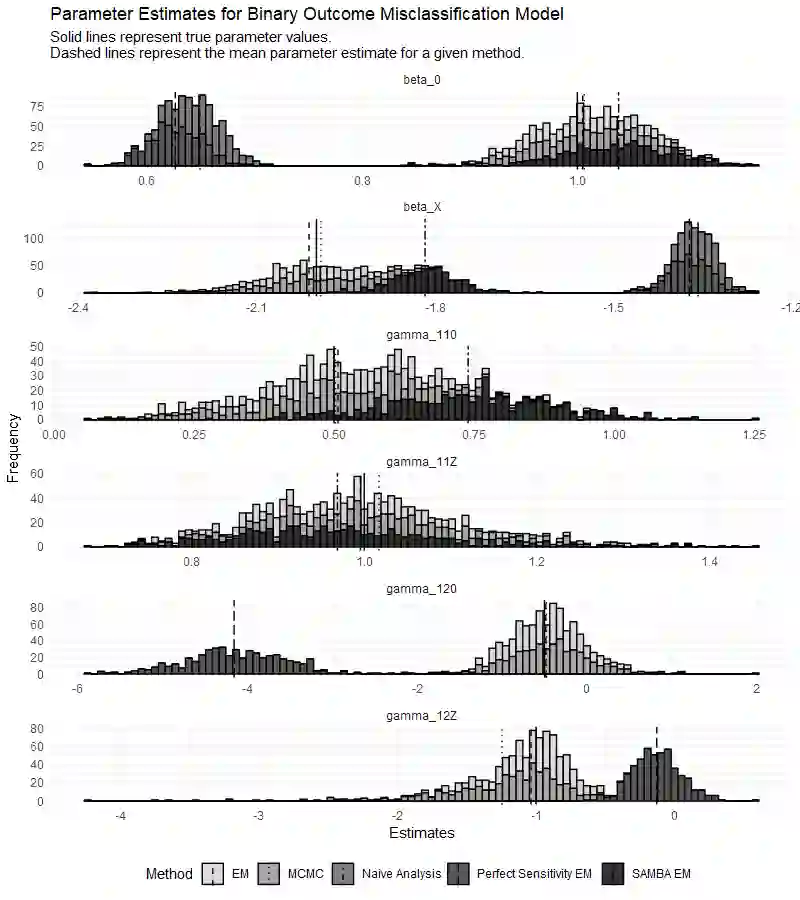
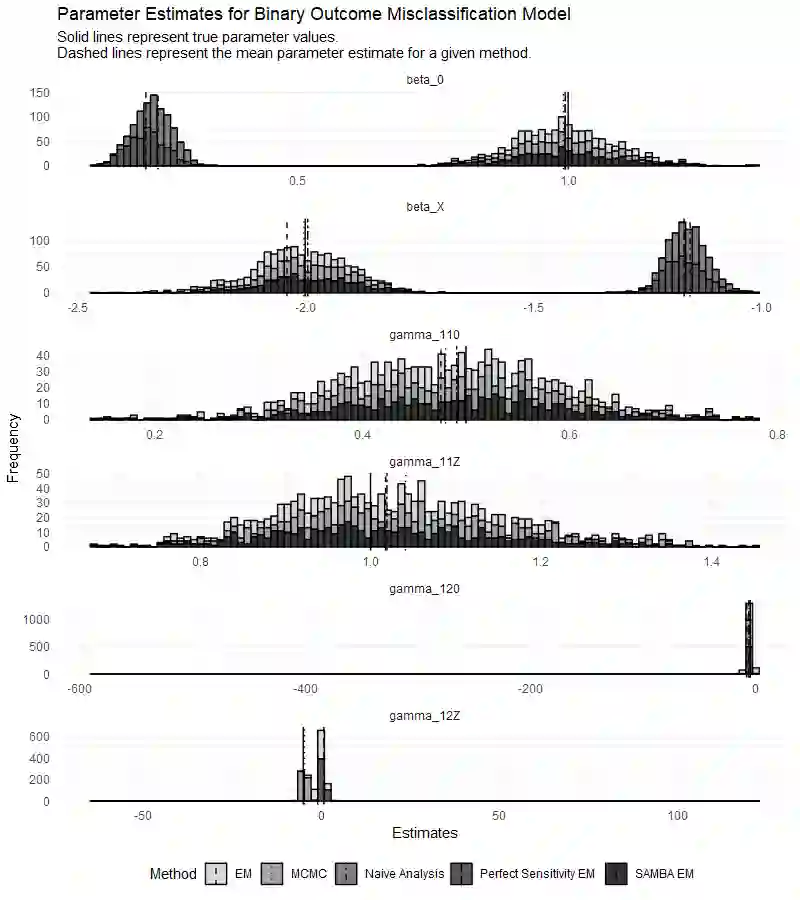
In biomedical and public health association studies, binary outcome variables may be subject to misclassification, resulting in substantial bias in effect estimates. The feasibility of addressing binary outcome misclassification in regression models is often hindered by model identifiability issues. In this paper, we characterize the identifiability problems in this class of models as a specific case of "label switching" and leverage a pattern in the resulting parameter estimates to solve the permutation invariance of the complete data log-likelihood. Our proposed algorithm in binary outcome misclassification models does not require gold standard labels and relies only on the assumption that outcomes are correctly classified at least 50% of the time. A label switching correction is applied within estimation methods to recover unbiased effect estimates and to estimate misclassification rates. Open source software is provided to implement the proposed methods. We give a detailed simulation study for our proposed methodology and apply these methods to data from the 2020 Medical Expenditure Panel Survey (MEPS).
翻译:在生物医学与公共卫生关联研究中,二分类结局变量可能存在分类错误,导致效应估计出现显著偏倚。回归模型中处理二分类结局错分的可行性常受限于模型可识别性问题。本文将该类模型中的可识别性问题刻画为"标签交换"的特殊情形,并利用参数估计结果中的特定模式,解决完全数据对数似然的置换不变性。我们提出的二分类结局错分模型算法无需金标准标签,仅依赖于"结局正确分类概率至少为50%"的假设。通过在估计方法中应用标签交换校正,可恢复无偏效应估计并估计错分率。我们提供开源软件实现所提方法,并开展详细的模拟研究验证方法性能。最后,将所提方法应用于2020年医疗支出面板调查(MEPS)数据。