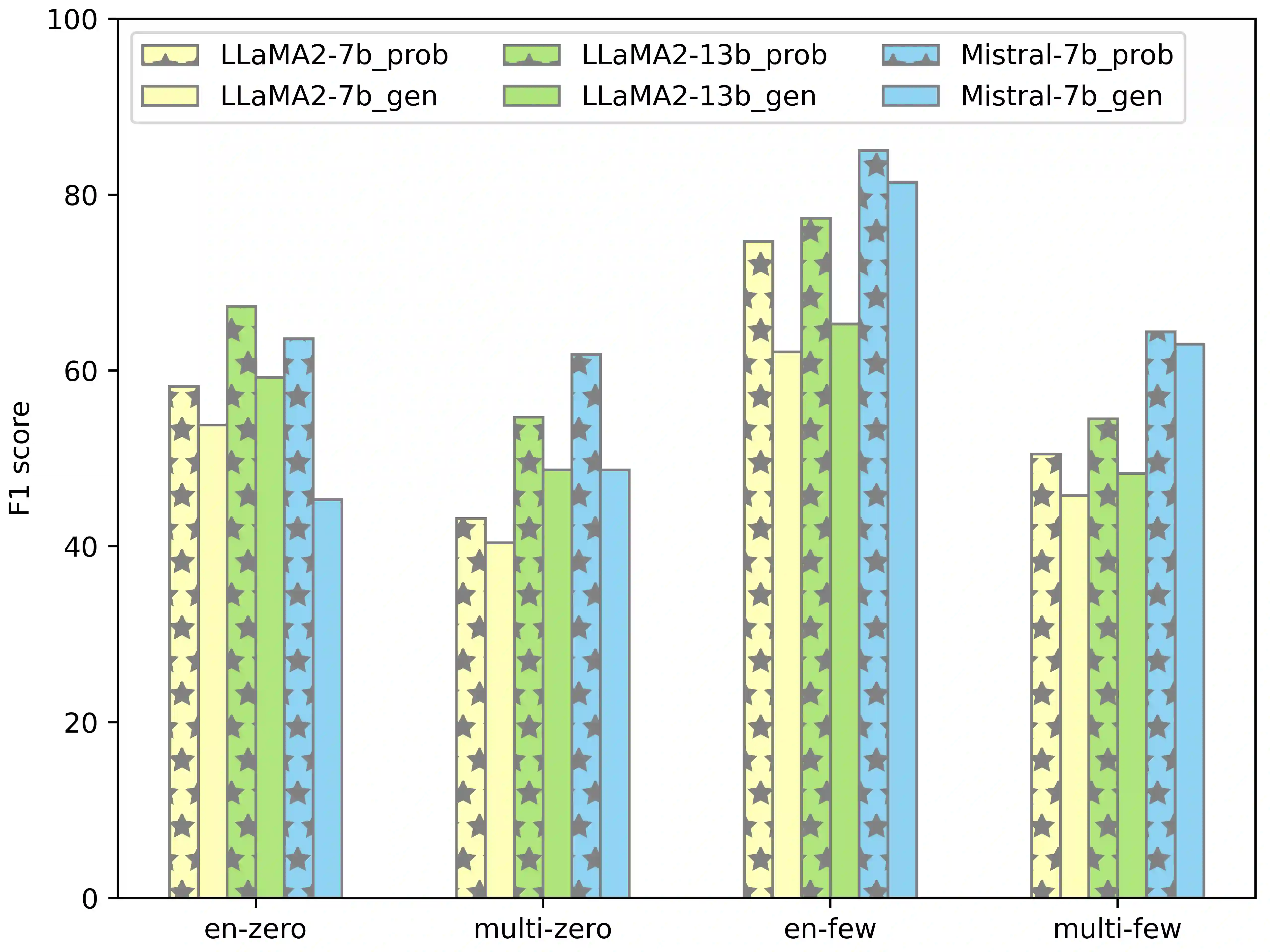
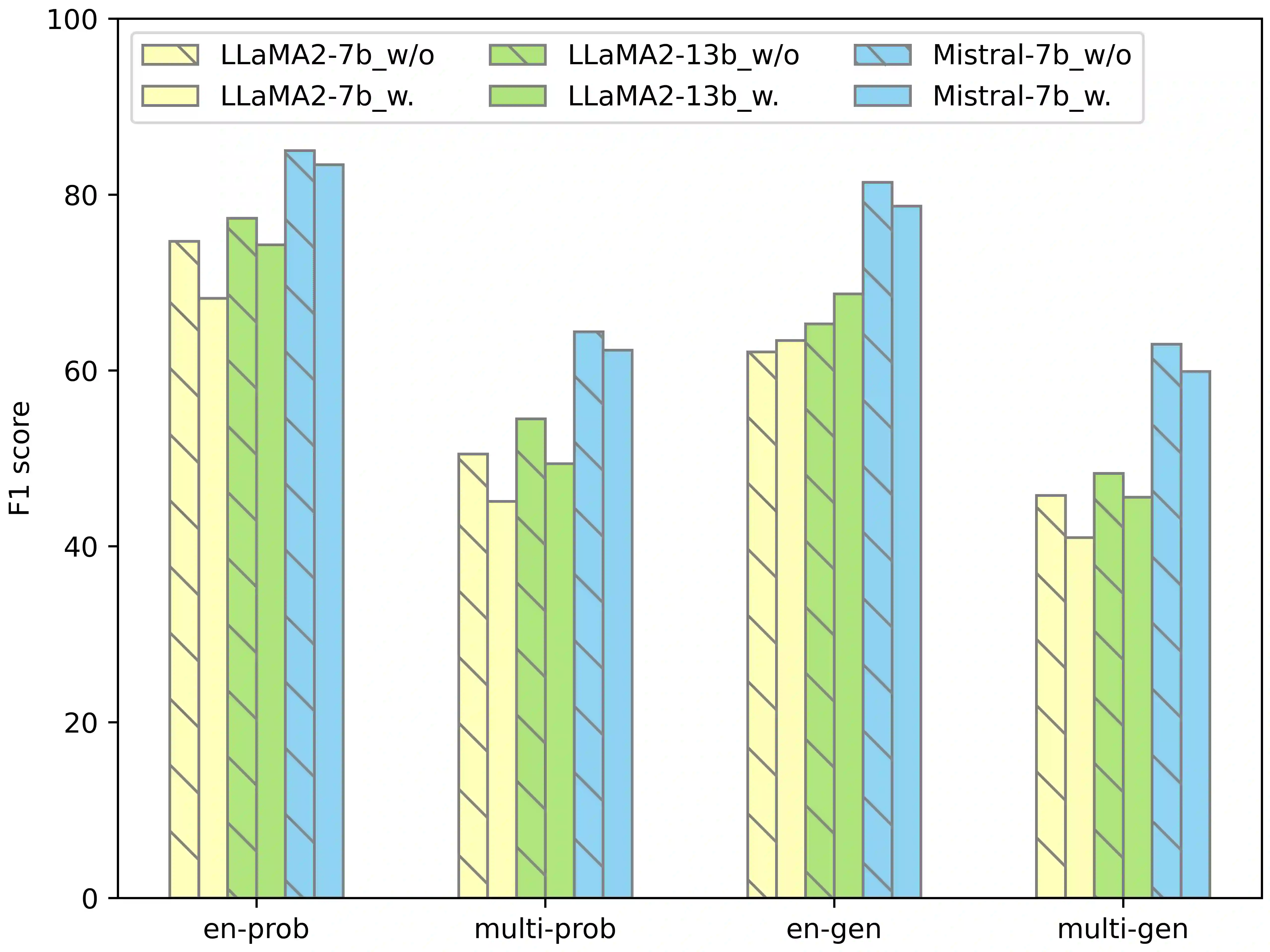
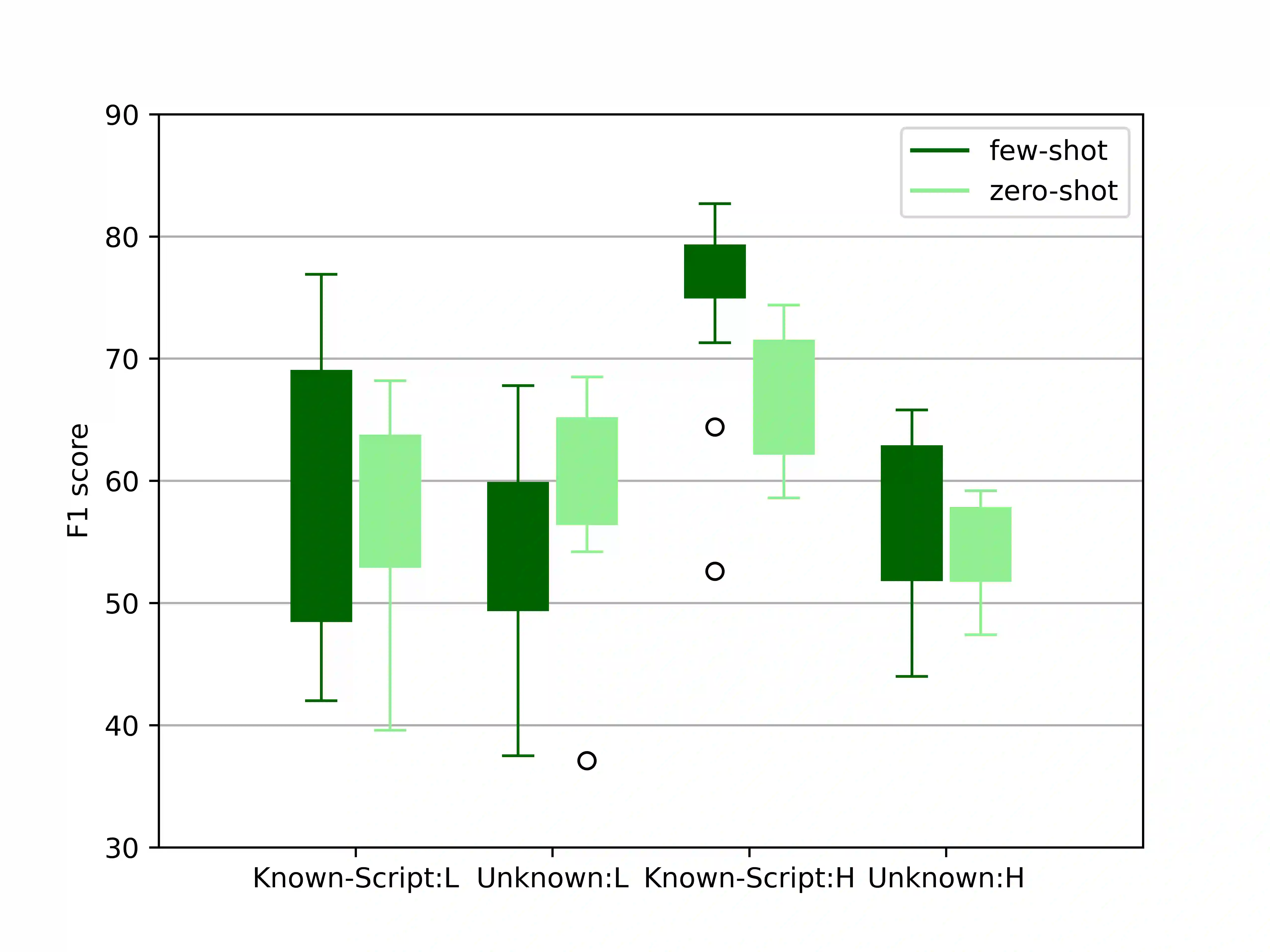
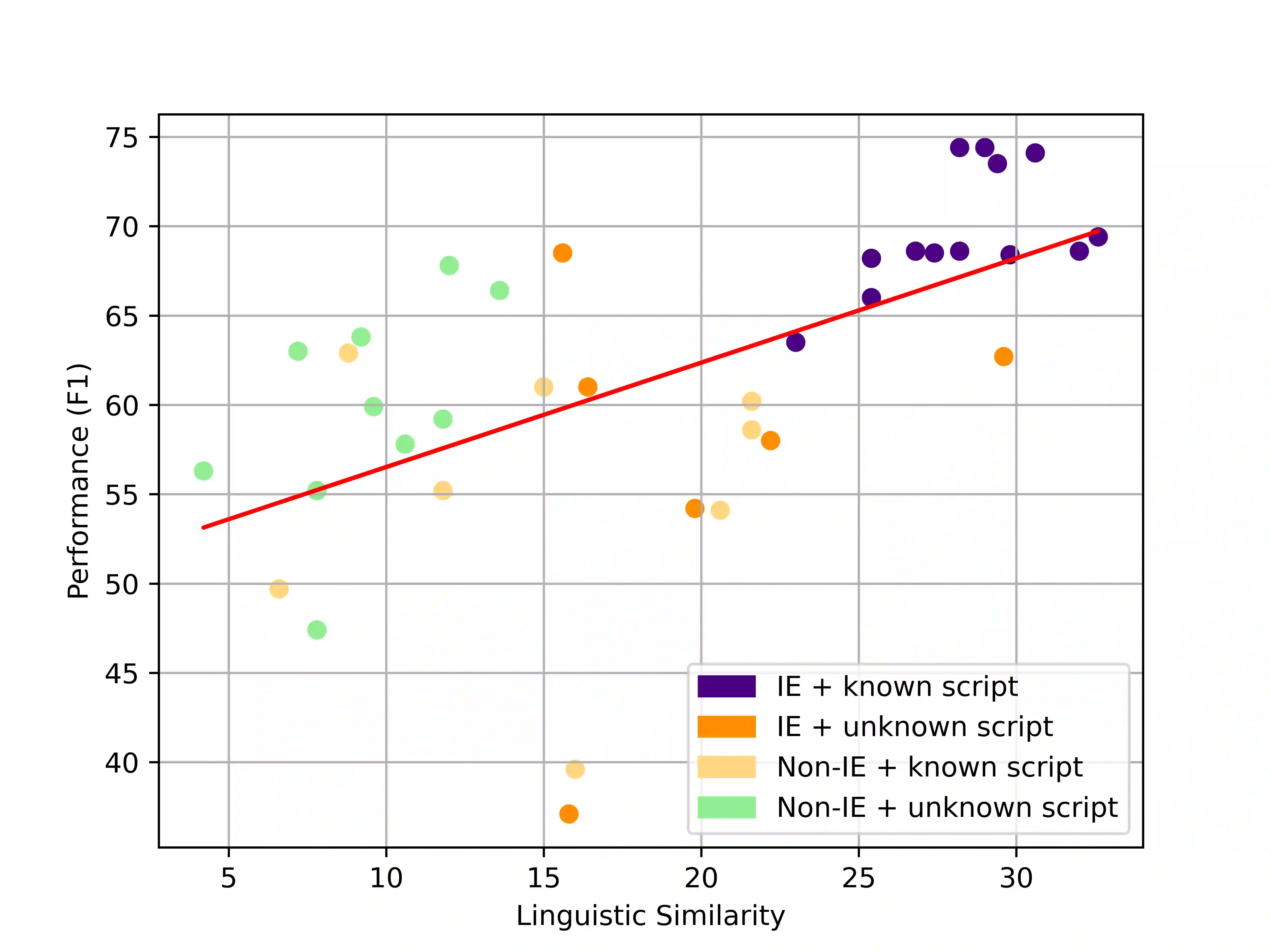
Despite the predominance of English in their training data, English-centric Large Language Models (LLMs) like GPT-3 and LLaMA display a remarkable ability to perform multilingual tasks, raising questions about the depth and nature of their cross-lingual capabilities. This paper introduces the decomposed prompting approach to probe the linguistic structure understanding of these LLMs in sequence labeling tasks. Diverging from the single text-to-text prompt, our method generates for each token of the input sentence an individual prompt which asks for its linguistic label. We assess our method on the Universal Dependencies part-of-speech tagging dataset for 38 languages, utilizing both English-centric and multilingual LLMs. Our findings show that decomposed prompting surpasses the iterative prompting baseline in efficacy and efficiency under zero- and few-shot settings. Further analysis reveals the influence of evaluation methods and the use of instructions in prompts. Our multilingual investigation shows that English-centric language models perform better on average than multilingual models. Our study offers insights into the multilingual transferability of English-centric LLMs, contributing to the understanding of their multilingual linguistic knowledge.
翻译:尽管训练数据中以英语为主,但以英语为中心的大语言模型(如GPT-3和LLaMA)在完成多语言任务时展现出显著能力,这引发了对其跨语言能力深度与本质的探讨。本文引入分解式提示方法,探究这些大语言模型在序列标注任务中的语言结构理解能力。与单一文本到文本提示不同,我们的方法为输入句子中的每个词元生成独立提示,询问其语言标签。我们在涵盖38种语言的通用依存关系词性标注数据集上评估该方法,使用以英语为中心和多语言的大语言模型。研究结果表明,在零样本和少样本设置下,分解式提示在有效性和效率上均优于迭代提示基线。进一步分析揭示了评估方法和提示中指令使用的影响。我们的多语言研究表明,以英语为中心的语言模型平均表现优于多语言模型。本研究为以英语为中心的大语言模型的多语言迁移能力提供了见解,有助于理解其多语言语言知识。