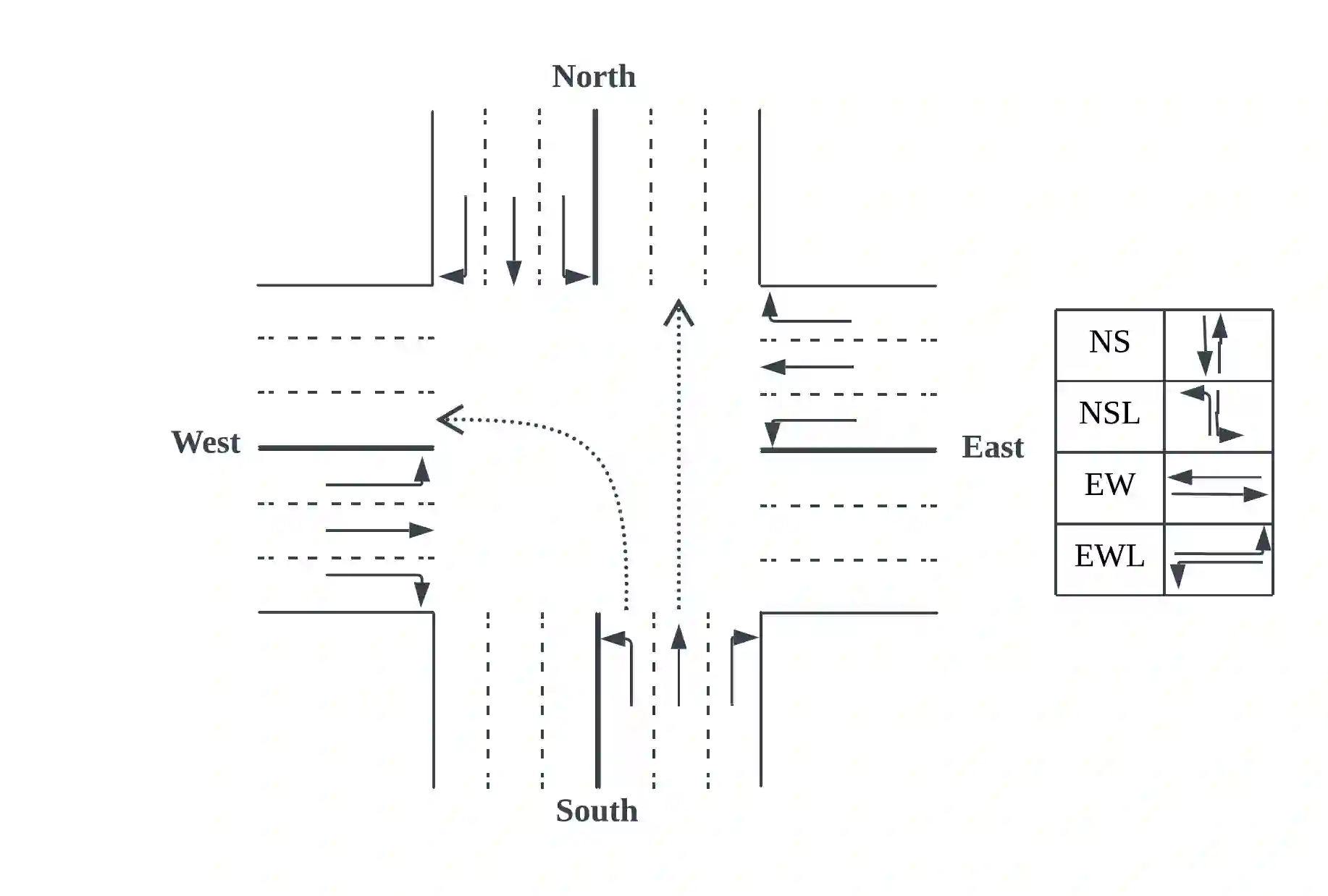
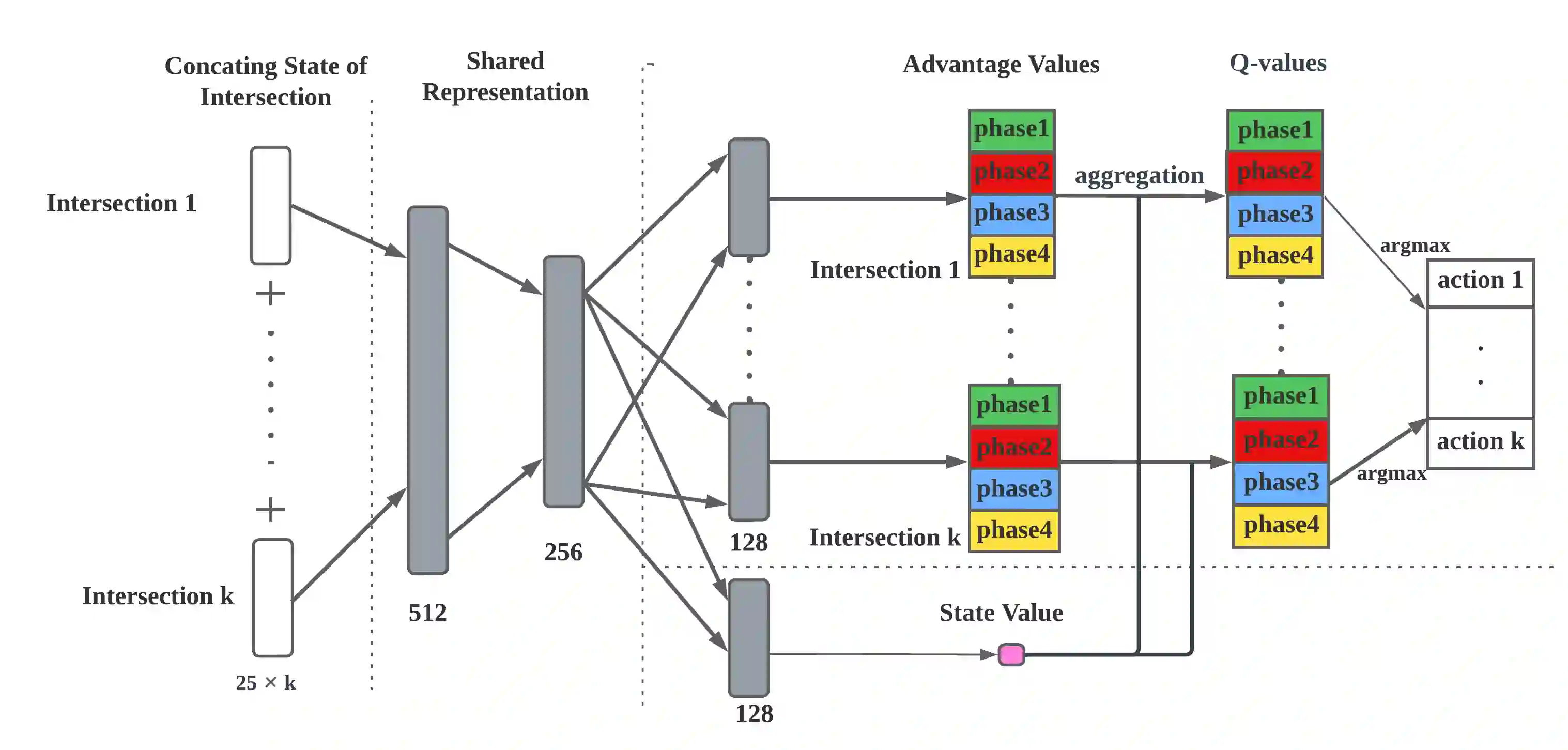
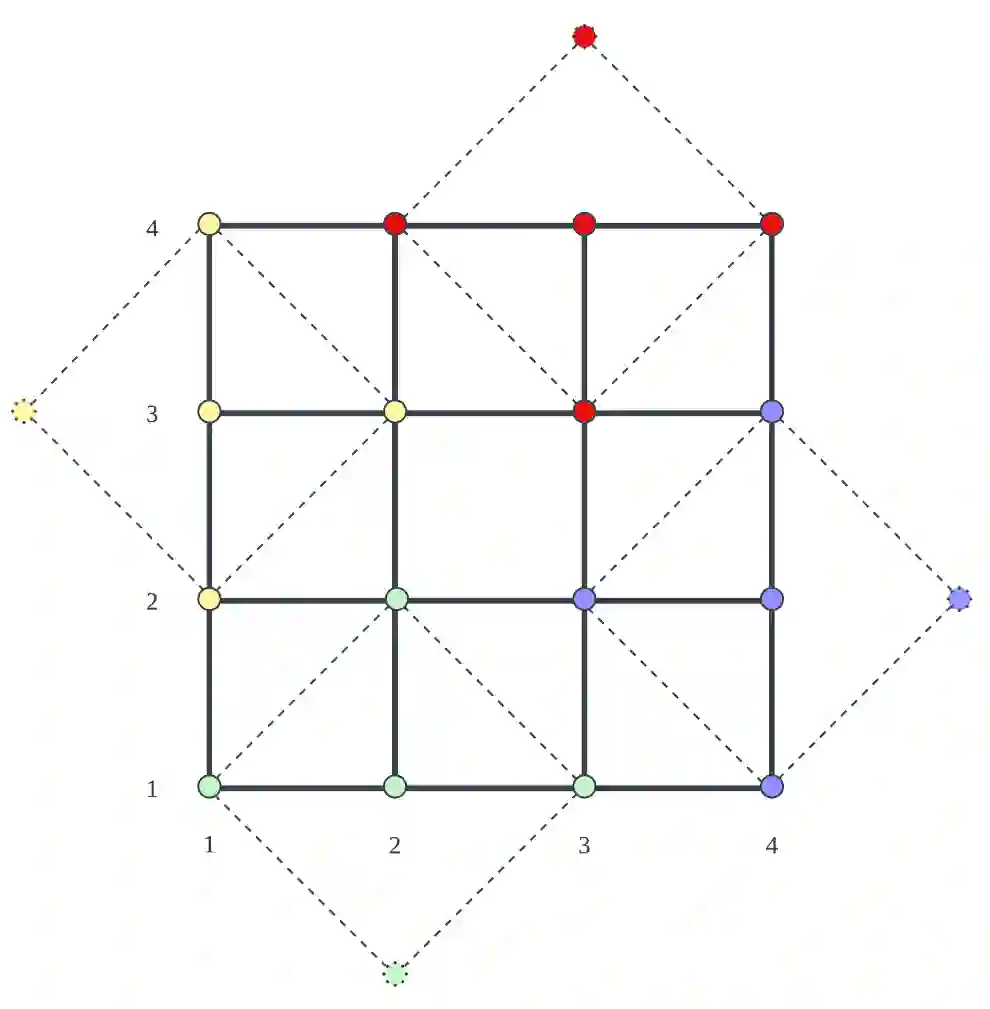
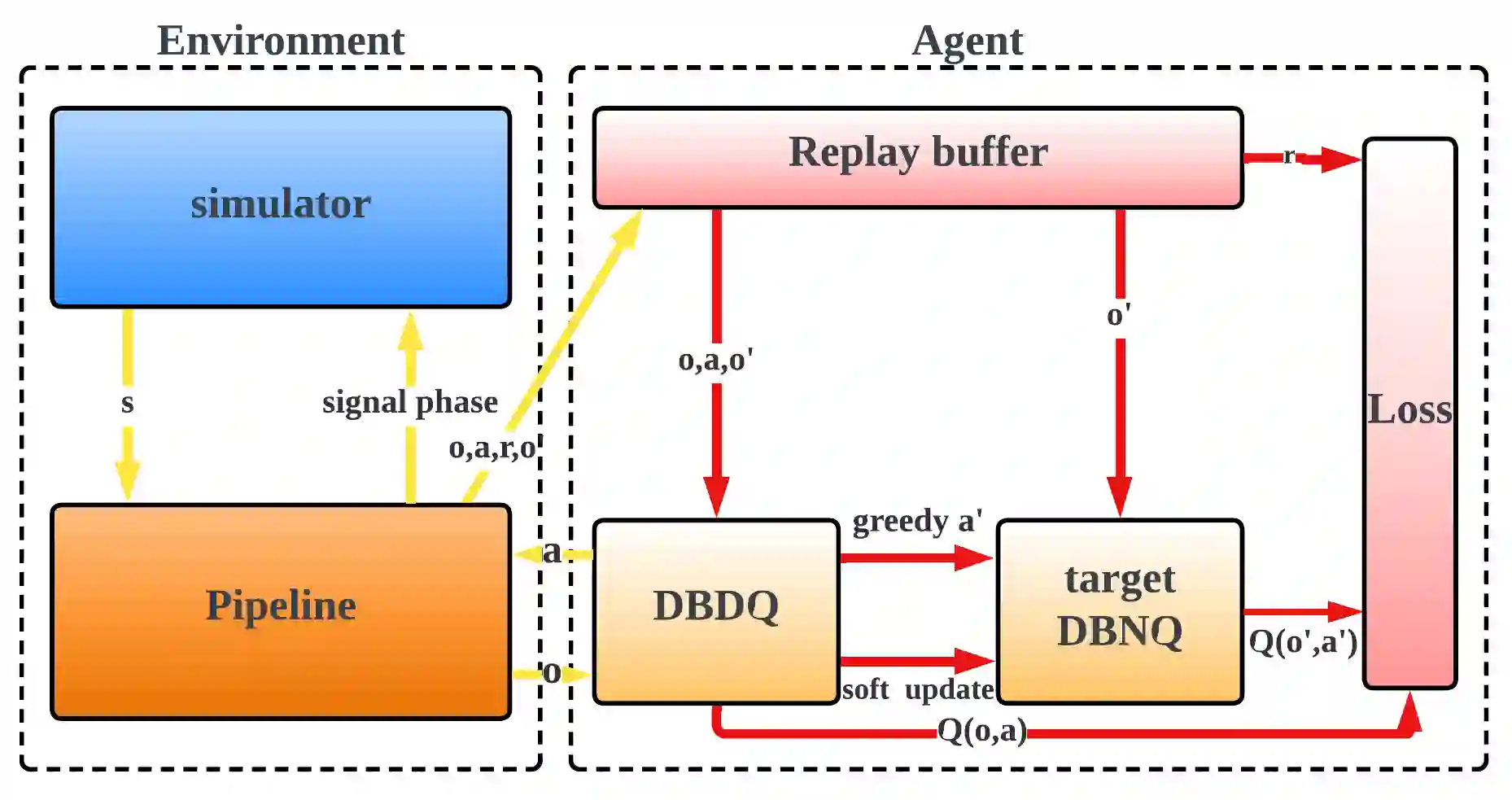
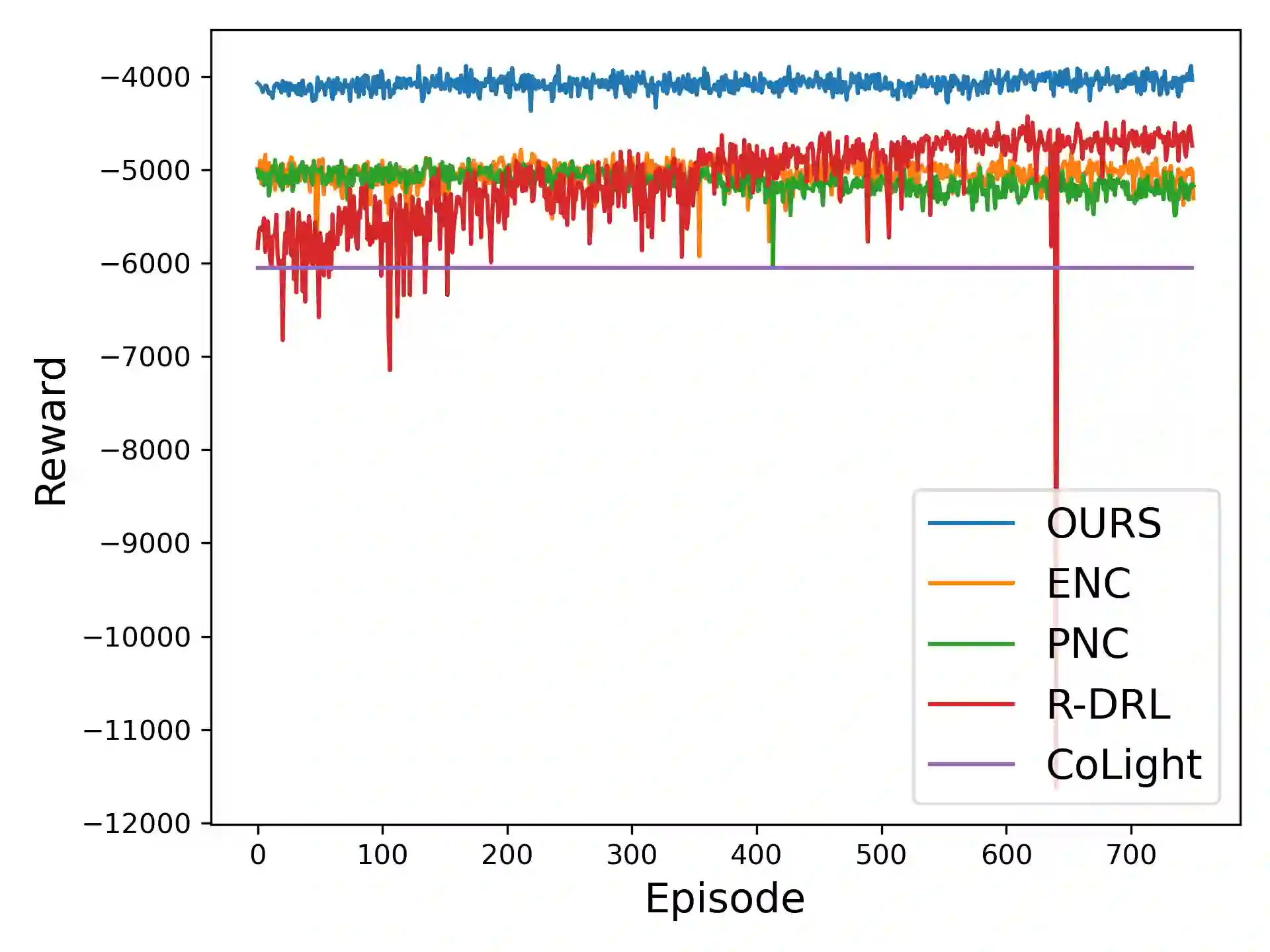
Adaptive traffic signal control with Multi-agent Reinforcement Learning(MARL) is a very popular topic nowadays. In most existing novel methods, one agent controls single intersections and these methods focus on the cooperation between intersections. However, the non-stationary property of MARL still limits the performance of the above methods as the size of traffic networks grows. One compromised strategy is to assign one agent with a region of intersections to reduce the number of agents. There are two challenges in this strategy, one is how to partition a traffic network into small regions and the other is how to search for the optimal joint actions for a region of intersections. In this paper, we propose a novel training framework RegionLight where our region partition rule is based on the adjacency between the intersection and extended Branching Dueling Q-Network(BDQ) to Dynamic Branching Dueling Q-Network(DBDQ) to bound the growth of the size of joint action space and alleviate the bias introduced by imaginary intersections outside of the boundary of the traffic network. Our experiments on both real datasets and synthetic datasets demonstrate that our framework performs best among other novel frameworks and that our region partition rule is robust.
翻译:自适应交通信号控制结合多智能体强化学习(MARL)是当前非常热门的研究课题。在大多数现有创新方法中,每个智能体控制单个交叉口,这些方法侧重于交叉口之间的协作。然而,随着交通网络规模的增大,MARL的非平稳特性仍然限制了上述方法的性能。一种折中策略是为一个智能体分配一个交叉口区域,以减少智能体的数量。该策略面临两个挑战:一是如何将交通网络划分为多个小区域,二是如何为交叉口区域搜索最优联合动作。本文提出了一种新颖的训练框架RegionLight,其中区域划分规则基于交叉口间的邻接关系,并将扩展分支对偶Q网络(BDQ)发展为动态分支对偶Q网络(DBDQ),以限制联合动作空间规模的增长,并减轻交通网络边界外虚拟交叉口引入的偏差。我们在真实数据集和合成数据集上的实验表明,我们的框架在与其他创新框架对比中表现最优,且区域划分规则具有鲁棒性。