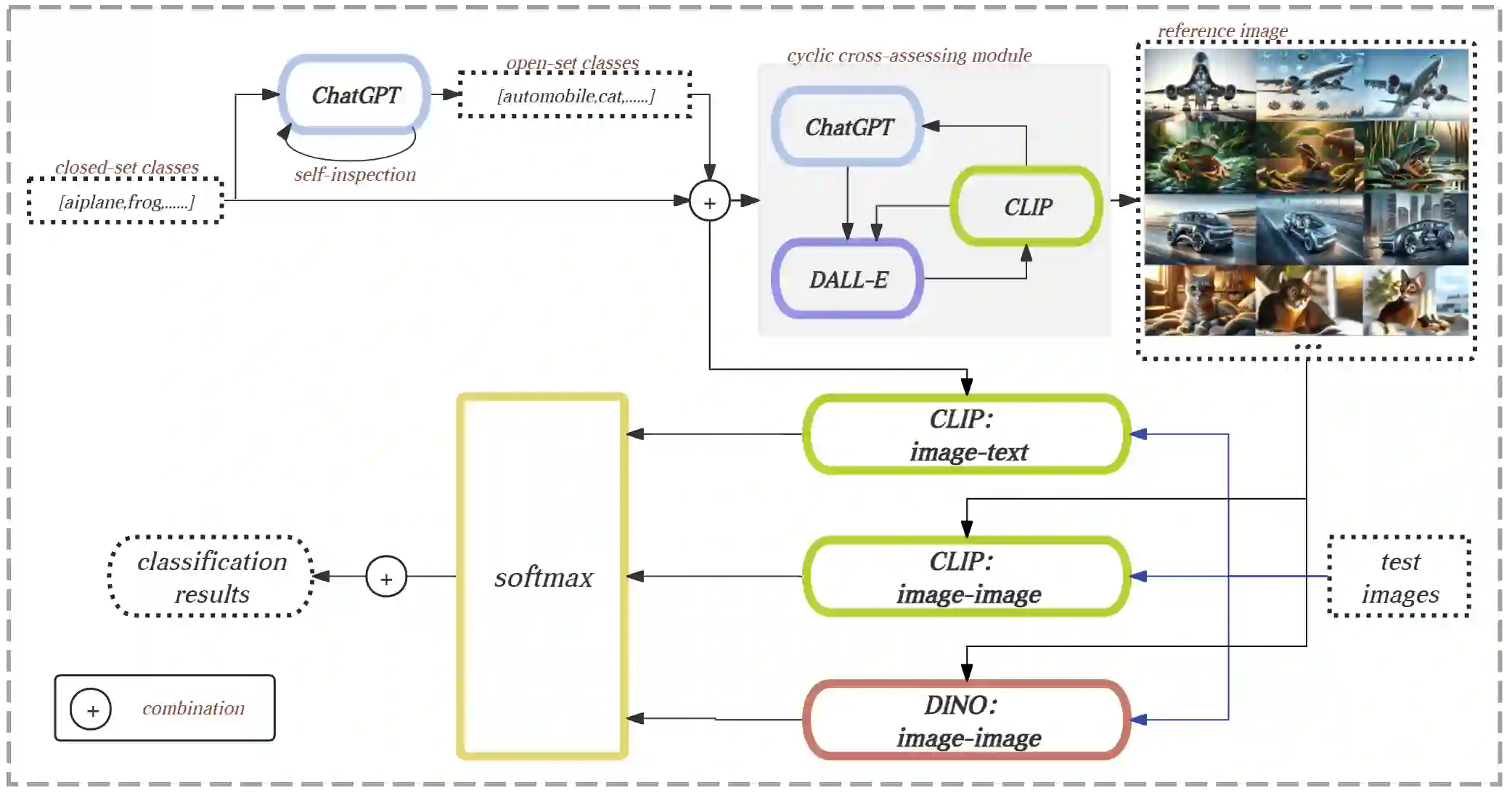
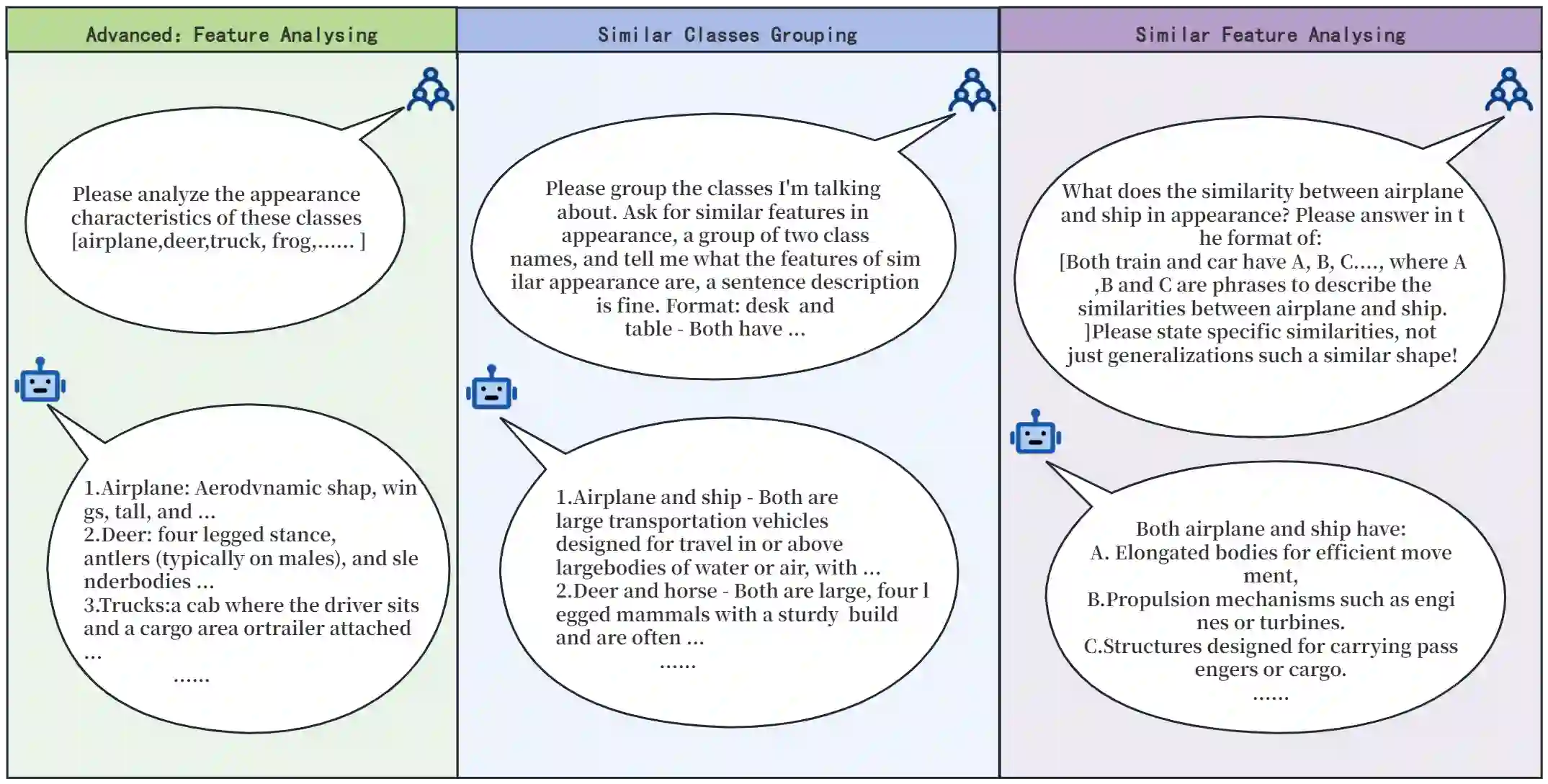
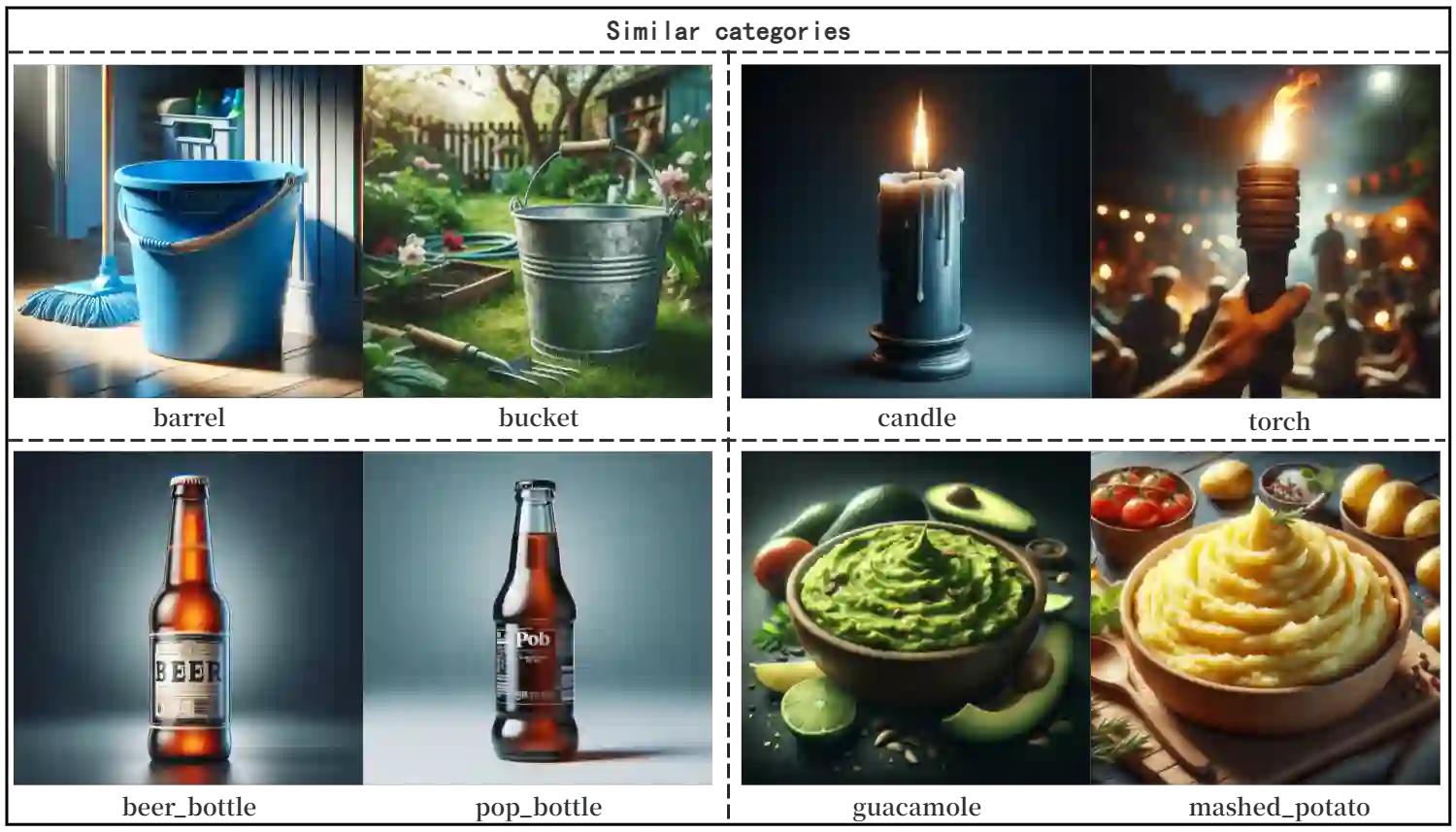
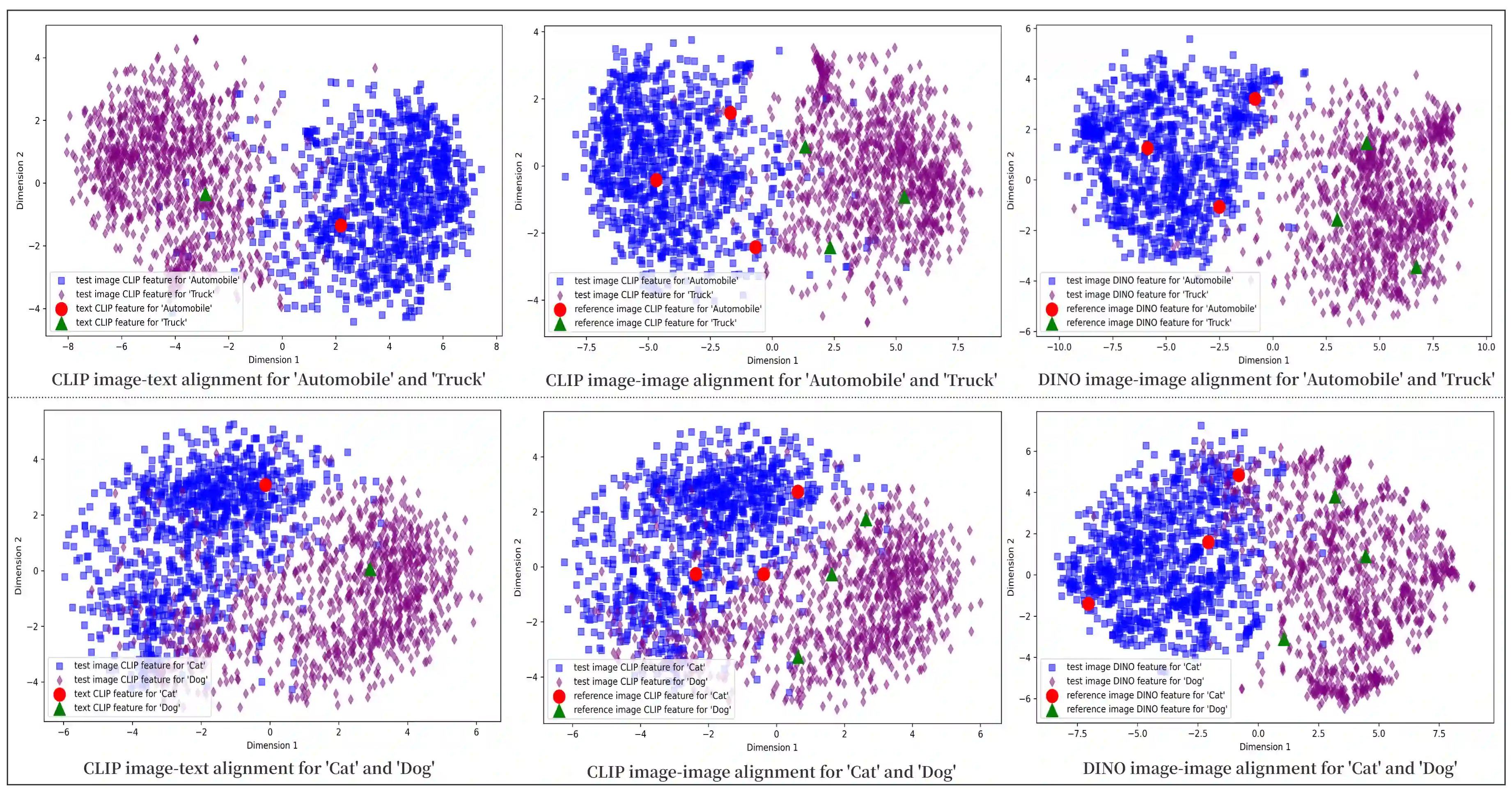
This paper introduces a novel framework for zero-shot learning (ZSL), i.e., to recognize new categories that are unseen during training, by using a multi-model and multi-alignment integration method. Specifically, we propose three strategies to enhance the model's performance to handle ZSL: 1) Utilizing the extensive knowledge of ChatGPT and the powerful image generation capabilities of DALL-E to create reference images that can precisely describe unseen categories and classification boundaries, thereby alleviating the information bottleneck issue; 2) Integrating the results of text-image alignment and image-image alignment from CLIP, along with the image-image alignment results from DINO, to achieve more accurate predictions; 3) Introducing an adaptive weighting mechanism based on confidence levels to aggregate the outcomes from different prediction methods. Experimental results on multiple datasets, including CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate that our model can significantly improve classification accuracy compared to single-model approaches, achieving AUROC scores above 96% across all test datasets, and notably surpassing 99% on the CIFAR-10 dataset.
翻译:本文针对零样本学习(ZSL)问题——即识别训练阶段未见的新类别——提出了一种新颖的框架,采用多模型与多对齐融合方法。具体而言,我们提出了三种策略以增强模型处理ZSL的性能:1)利用ChatGPT的广泛知识及DALL-E强大的图像生成能力,创建能够精确描述未见类别与分类边界的参考图像,从而缓解信息瓶颈问题;2)融合CLIP的文本-图像对齐与图像-图像对齐结果,以及DINO的图像-图像对齐结果,以实现更精准的预测;3)引入基于置信水平的自适应加权机制,聚合不同预测方法的结果。在CIFAR-10、CIFAR-100及TinyImageNet等多个数据集上的实验结果表明,相较于单模型方法,我们的模型能显著提升分类准确率,在所有测试数据集上的AUROC得分均超过96%,其中在CIFAR-10数据集上更是突破99%。