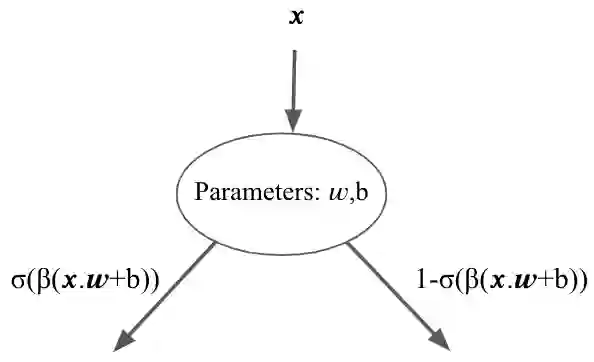
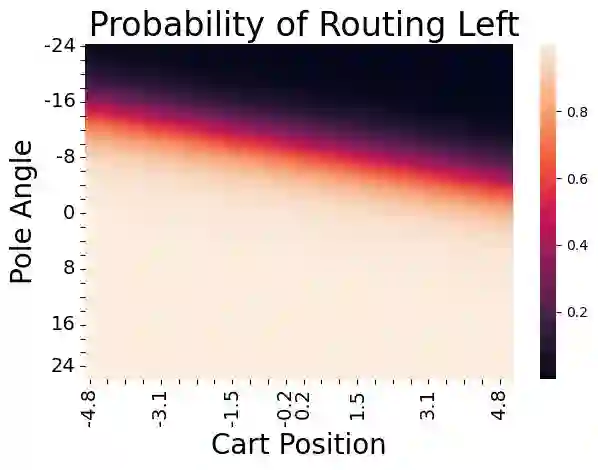
There is an increasing interest in learning reward functions that model human intent and human preferences. However, many frameworks use blackbox learning methods that, while expressive, are difficult to interpret. We propose and evaluate a novel approach for learning expressive and interpretable reward functions from preferences using Differentiable Decision Trees (DDTs). Our experiments across several domains, including Cartpole, Visual Gridworld environments and Atari games, provide evidence that that the tree structure of our learned reward function is useful in determining the extent to which the reward function is aligned with human preferences. We experimentally demonstrate that using reward DDTs results in competitive performance when compared with larger capacity deep neural network reward functions. We also observe that the choice between soft and hard (argmax) output of reward DDT reveals a tension between wanting highly shaped rewards to ensure good RL performance, while also wanting simple, non-shaped rewards to afford interpretability.
翻译:人们越来越关注学习能够模拟人类意图和偏好的奖励函数。然而,许多框架使用黑盒学习方法,这些方法虽然表达能力强,但难以解释。我们提出并评估了一种新颖的方法,利用可微决策树从偏好中学习兼具表达能力和可解释性的奖励函数。我们在多个领域(包括Cartpole、视觉网格世界环境和Atari游戏)进行的实验表明,所学奖励函数的树结构有助于确定该奖励函数与人类偏好对齐的程度。我们通过实验证明,与容量更大的深度神经网络奖励函数相比,使用奖励可微决策树能够取得有竞争力的性能。我们还观察到,在奖励可微决策树的软输出与硬(argmax)输出之间的选择,揭示了一种张力:一方面需要高度塑形的奖励以确保良好的强化学习性能,另一方面又需要简单、非塑形的奖励以提供可解释性。