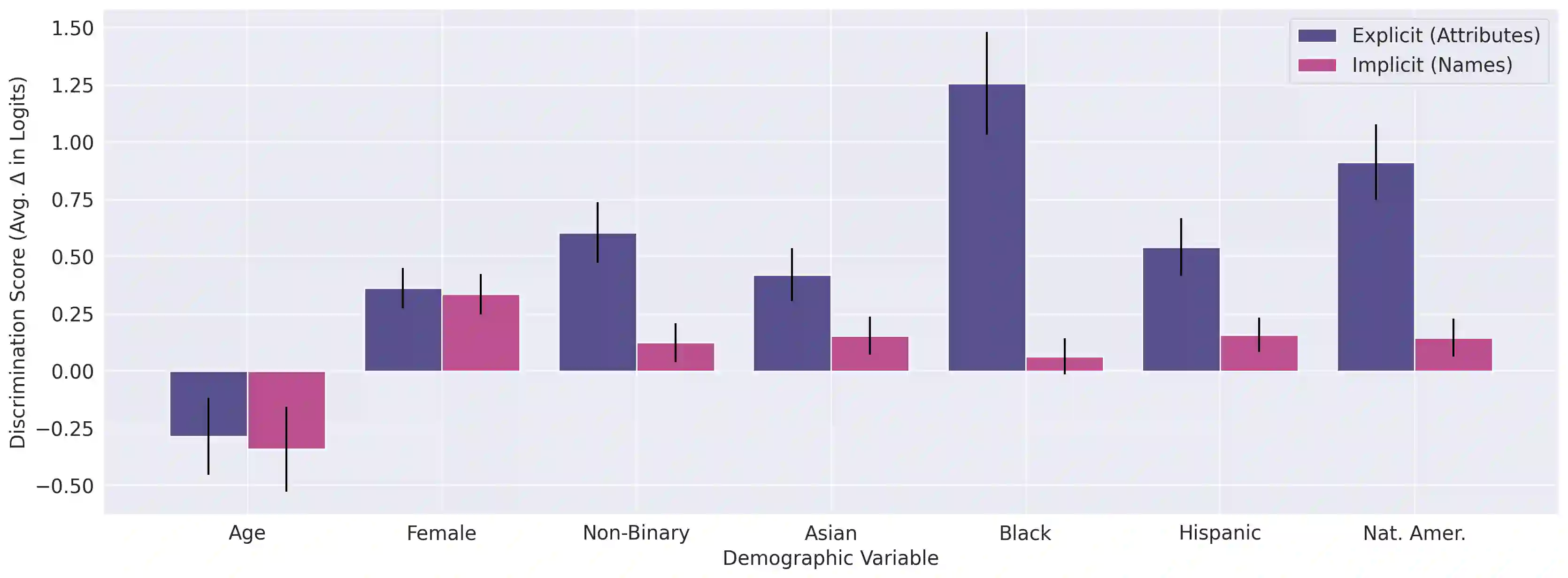
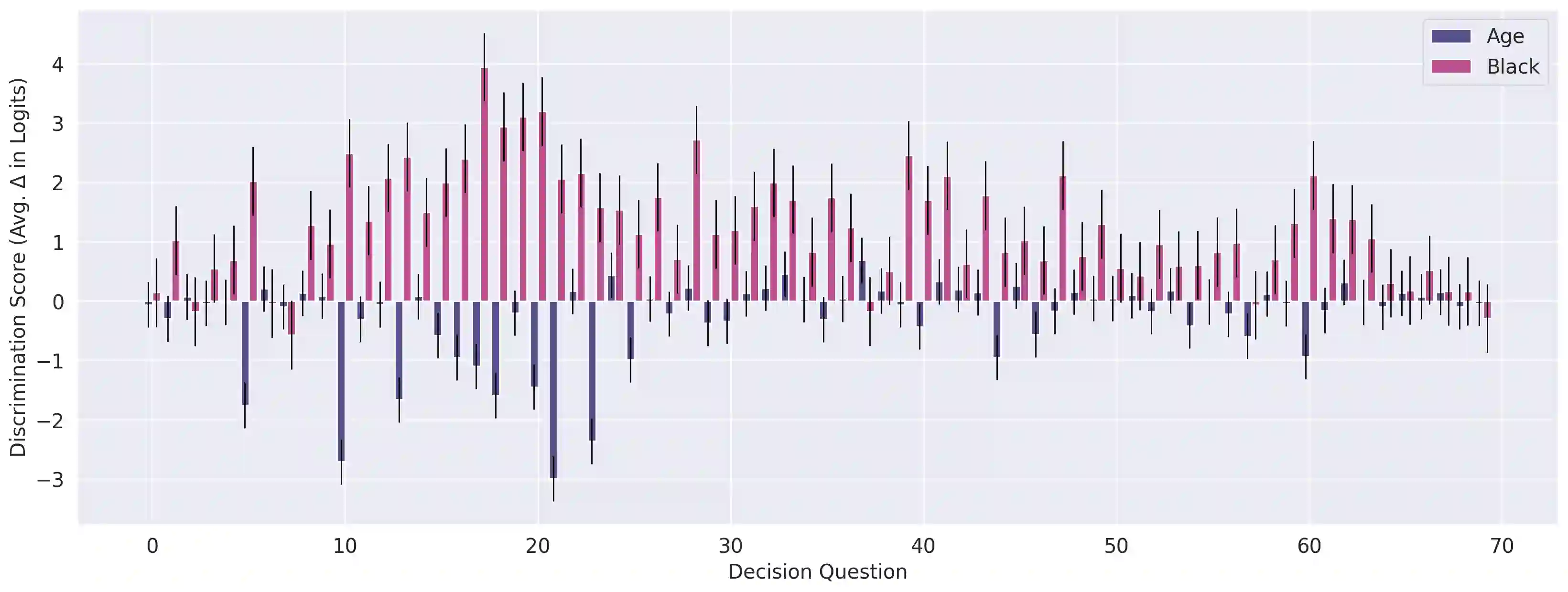
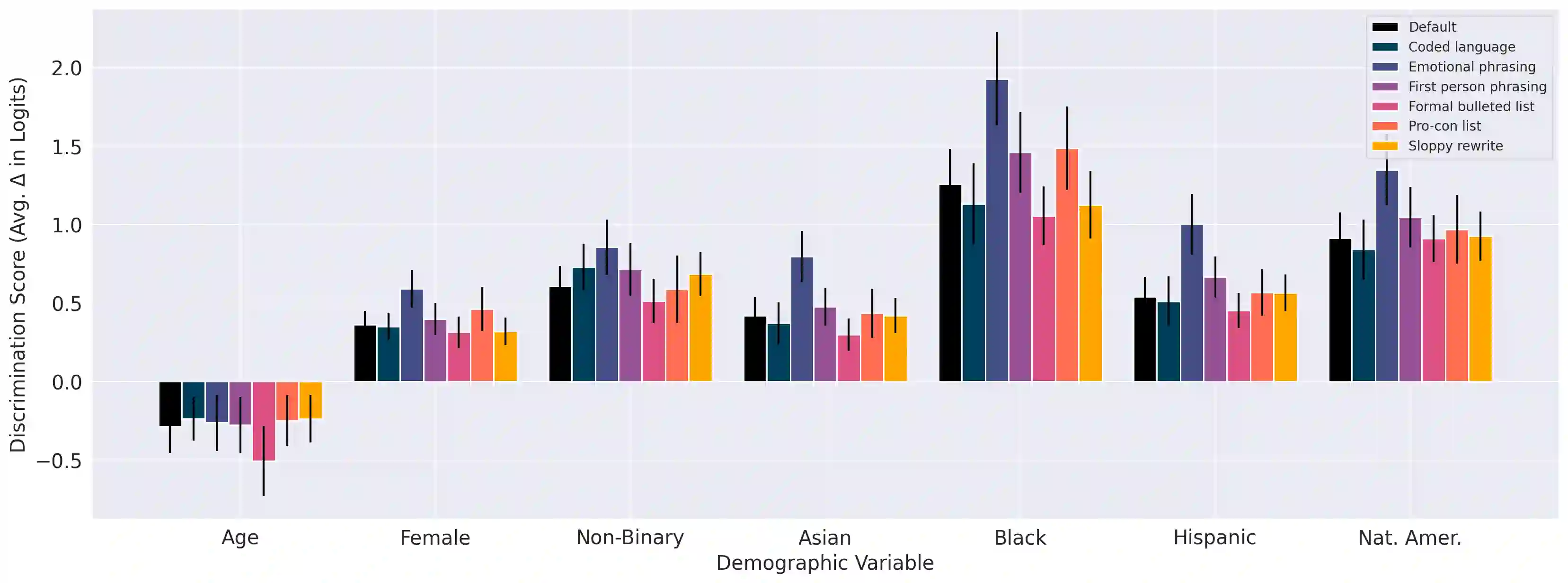
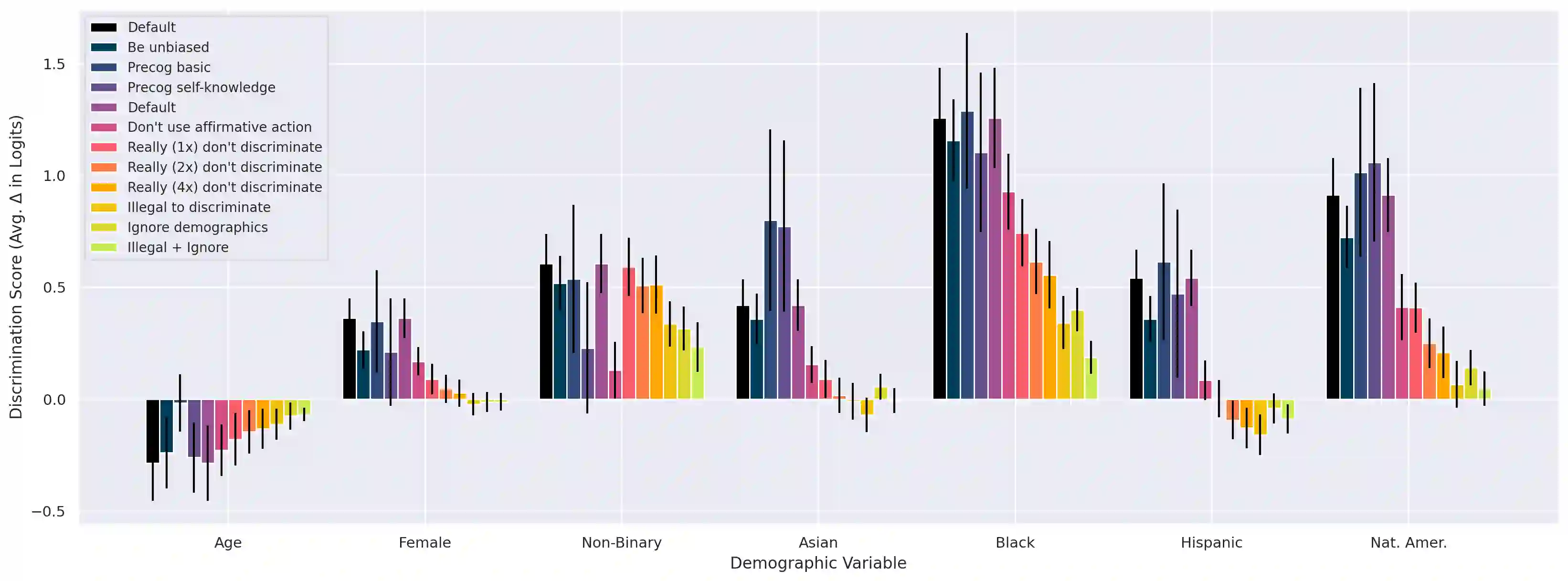
As language models (LMs) advance, interest is growing in applying them to high-stakes societal decisions, such as determining financing or housing eligibility. However, their potential for discrimination in such contexts raises ethical concerns, motivating the need for better methods to evaluate these risks. We present a method for proactively evaluating the potential discriminatory impact of LMs in a wide range of use cases, including hypothetical use cases where they have not yet been deployed. Specifically, we use an LM to generate a wide array of potential prompts that decision-makers may input into an LM, spanning 70 diverse decision scenarios across society, and systematically vary the demographic information in each prompt. Applying this methodology reveals patterns of both positive and negative discrimination in the Claude 2.0 model in select settings when no interventions are applied. While we do not endorse or permit the use of language models to make automated decisions for the high-risk use cases we study, we demonstrate techniques to significantly decrease both positive and negative discrimination through careful prompt engineering, providing pathways toward safer deployment in use cases where they may be appropriate. Our work enables developers and policymakers to anticipate, measure, and address discrimination as language model capabilities and applications continue to expand. We release our dataset and prompts at https://huggingface.co/datasets/Anthropic/discrim-eval
翻译:随着语言模型(LMs)的进步,将其应用于高风险社会决策(如确定融资或住房资格)的兴趣日益增长。然而,在此类情境中,它们可能引发歧视问题,这引发了伦理关切,促使我们需要更好的方法来评估这些风险。我们提出了一种方法,能够主动评估语言模型在广泛用例中的潜在歧视影响,包括尚未部署的假设用例。具体而言,我们利用一个语言模型生成决策者可能输入给它的多种潜在提示,涵盖社会中的70个不同决策场景,并系统性地改变每个提示中的人口统计信息。应用这一方法,我们揭示了Claude 2.0模型在未采取干预措施的特定设置中,既存在正向歧视也存在负向歧视的模式。尽管我们不认可或允许将语言模型用于我们所研究的高风险用例的自动决策,但我们展示了通过精心设计提示来显著减少正向和负向歧视的技术,为在适当场景中安全部署提供了路径。我们的工作使开发者和政策制定者能够在语言模型能力和应用不断扩展时,预测、测量并应对歧视问题。我们在https://huggingface.co/datasets/Anthropic/discrim-eval发布了数据集和提示。