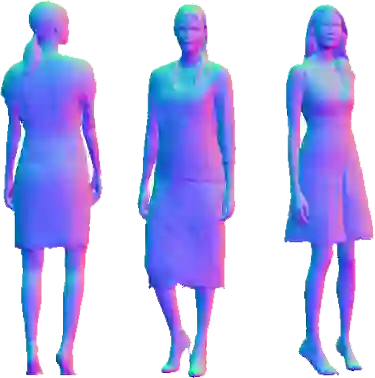While progress in 2D generative models of human appearance has been rapid, many applications require 3D avatars that can be animated and rendered. Unfortunately, most existing methods for learning generative models of 3D humans with diverse shape and appearance require 3D training data, which is limited and expensive to acquire. The key to progress is hence to learn generative models of 3D avatars from abundant unstructured 2D image collections. However, learning realistic and complete 3D appearance and geometry in this under-constrained setting remains challenging, especially in the presence of loose clothing such as dresses. In this paper, we propose a new adversarial generative model of realistic 3D people from 2D images. Our method captures shape and deformation of the body and loose clothing by adopting a holistic 3D generator and integrating an efficient and flexible articulation module. To improve realism, we train our model using multiple discriminators while also integrating geometric cues in the form of predicted 2D normal maps. We experimentally find that our method outperforms previous 3D- and articulation-aware methods in terms of geometry and appearance. We validate the effectiveness of our model and the importance of each component via systematic ablation studies.
翻译:虽然人类外观的二维生成模型进展迅速,但许多应用需要可动画和可渲染的三维虚拟形象。遗憾的是,现有的大多数学习具有多样化形状和外观的三维人体生成模型的方法都需要三维训练数据,而这类数据不仅有限且获取成本高昂。因此,取得进展的关键在于从海量无结构的二维图像集合中学习三维虚拟形象的生成模型。然而,在这一约束不足的场景中学习逼真且完整的三维外观和几何结构仍具挑战性,尤其是在存在连衣裙等宽松衣物的情况下。本文提出了一种基于二维图像生成逼真三维人物的新型对抗式生成模型。我们的方法通过采用整体三维生成器并集成高效灵活的关节模块,捕捉人体及宽松衣物的形状与形变。为提升真实感,我们采用多判别器训练模型,同时以预测的二维法线图形式整合几何线索。实验结果表明,我们的方法在几何与外观方面均优于先前的三维及关节感知方法。通过系统的消融研究,我们验证了模型的有效性及各组件的重要性。