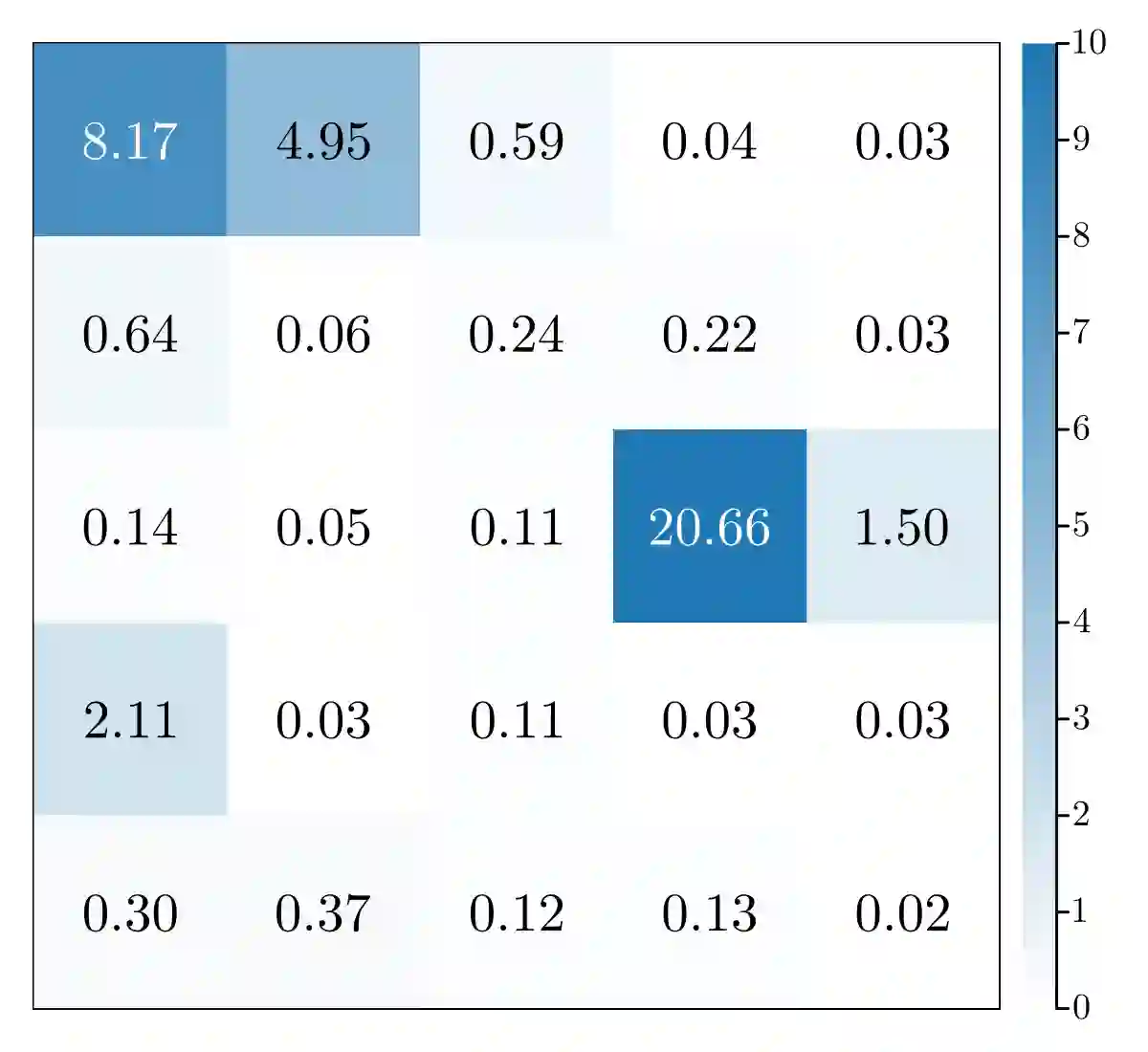
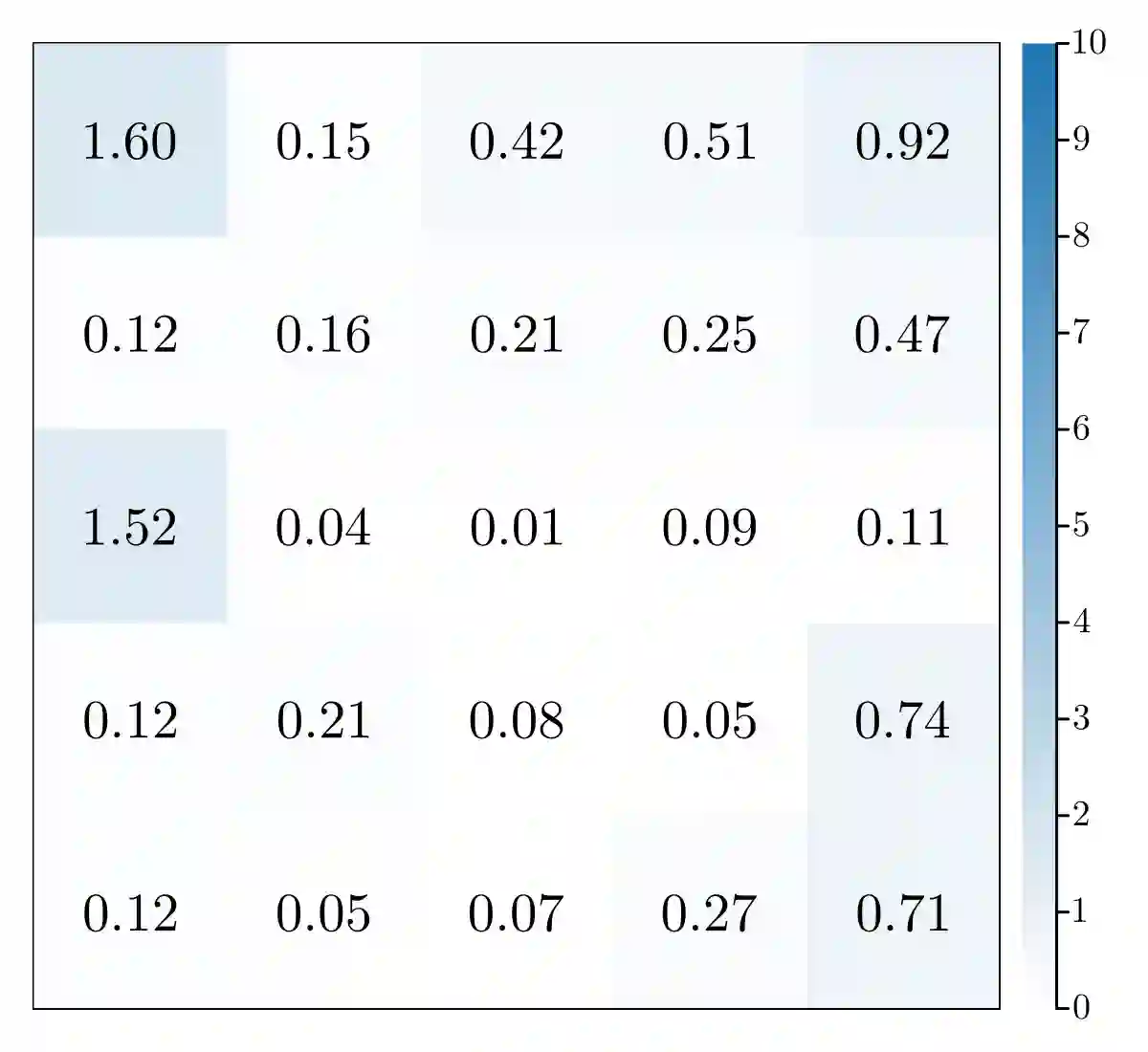
Markov games model interactions among multiple players in a stochastic, dynamic environment. Each player in a Markov game maximizes its expected total discounted reward, which depends upon the policies of the other players. We formulate a class of Markov games, termed affine Markov games, where an affine reward function couples the players' actions. We introduce a novel solution concept, the soft-Bellman equilibrium, where each player is boundedly rational and chooses a soft-Bellman policy rather than a purely rational policy as in the well-known Nash equilibrium concept. We provide conditions for the existence and uniqueness of the soft-Bellman equilibrium and propose a nonlinear least-squares algorithm to compute such an equilibrium in the forward problem. We then solve the inverse game problem of inferring the players' reward parameters from observed state-action trajectories via a projected-gradient algorithm. Experiments in a predator-prey OpenAI Gym environment show that the reward parameters inferred by the proposed algorithm outperform those inferred by a baseline algorithm: they reduce the Kullback-Leibler divergence between the equilibrium policies and observed policies by at least two orders of magnitude.
翻译:马尔可夫博弈刻画了多个参与者在随机动态环境中的交互行为。在马尔可夫博弈中,每位参与者通过最大化自身期望总折扣回报(该回报取决于其他参与者的策略)进行决策。本文提出一类称为仿射马尔可夫博弈的博弈模型,其中仿射回报函数将参与者的行为耦合关联。我们引入一种新的均衡概念——软贝尔曼均衡:在此概念下,每个参与者具有有限理性,选择软贝尔曼策略而非经典纳什均衡中的纯理性策略。我们论证了软贝尔曼均衡存在性与唯一性的条件,并提出一种非线性最小二乘算法用于正向问题中计算此类均衡。继而,我们通过投影梯度算法解决逆向博弈问题,从观测到的状态-动作轨迹中推断参与者的回报参数。在OpenAI Gym的捕食者-猎物环境中的实验表明:本文算法推断的回报参数在减少均衡策略与观测策略间的KL散度方面比基线算法至少优两个数量级。