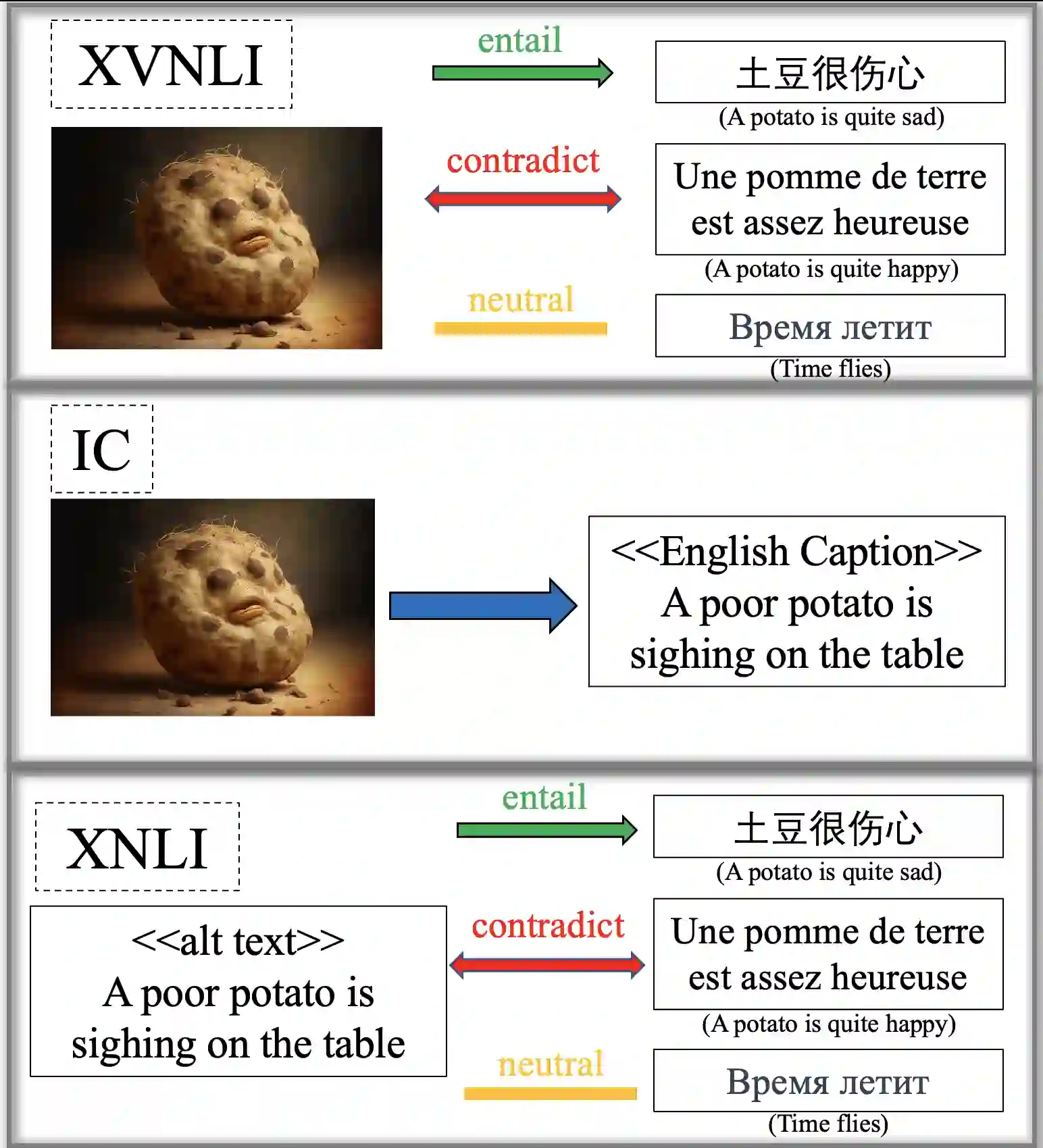
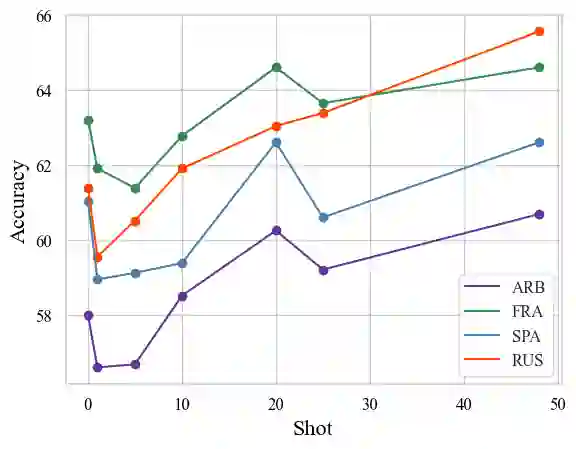
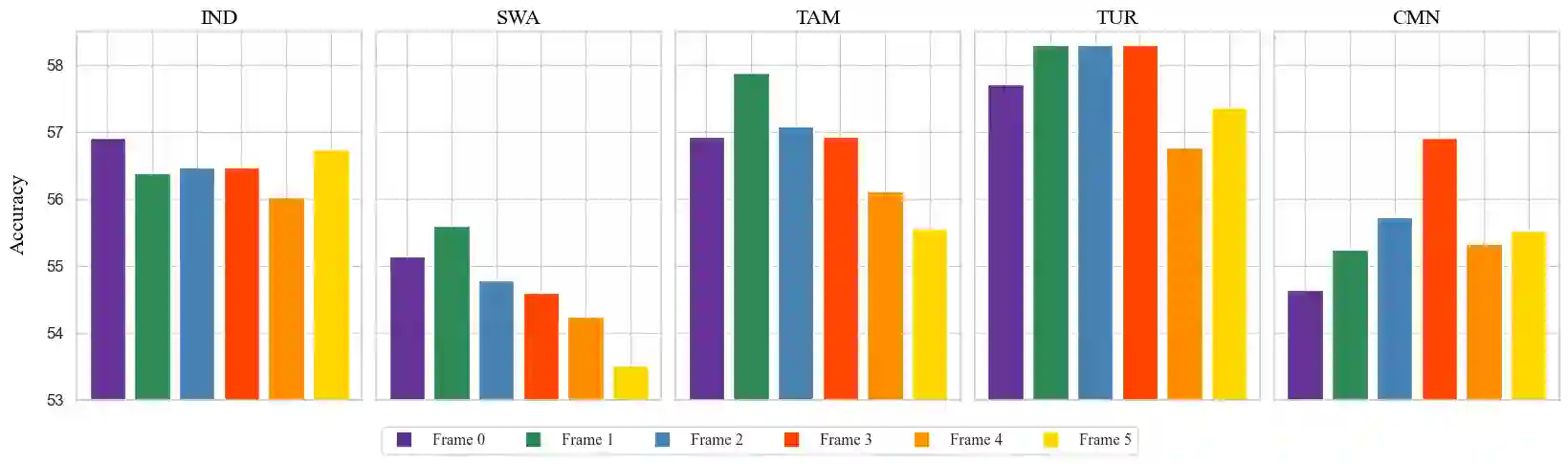
Most multilingual vision-and-language (V&L) research aims to accomplish multilingual and multimodal capabilities within one model. However, the scarcity of multilingual captions for images has hindered the development. To overcome this obstacle, we propose ICU, Image Caption Understanding, which divides a V&L task into two stages: a V&L model performs image captioning in English, and a multilingual language model (mLM), in turn, takes the caption as the alt text and performs crosslingual language understanding. The burden of multilingual processing is lifted off V&L model and placed on mLM. Since the multilingual text data is relatively of higher abundance and quality, ICU can facilitate the conquering of language barriers for V&L models. In experiments on two tasks across 9 languages in the IGLUE benchmark, we show that ICU can achieve new state-of-the-art results for five languages, and comparable results for the rest.
翻译:大多数多语言视觉与语言(V&L)研究旨在在单一模型中实现多语言与多模态能力。然而,图像的多语言描述文本稀缺这一问题始终制约着该领域的发展。为突破这一障碍,我们提出ICU(图像描述理解)方法,将V&L任务分解为两个阶段:首先由V&L模型生成英文图像描述,随后由多语言语言模型(mLM)将生成的描述作为替代文本进行跨语言理解。通过将多语言处理负担从V&L模型转移至mLM模型,利用多语言文本数据在数量和质量上的相对优势,ICU有效推动了V&L模型跨越语言障碍。在IGLUE基准测试涵盖9种语言的两项任务实验中,ICU在5种语言上取得了当前最优结果,并在其余语言上实现了可比的性能水平。