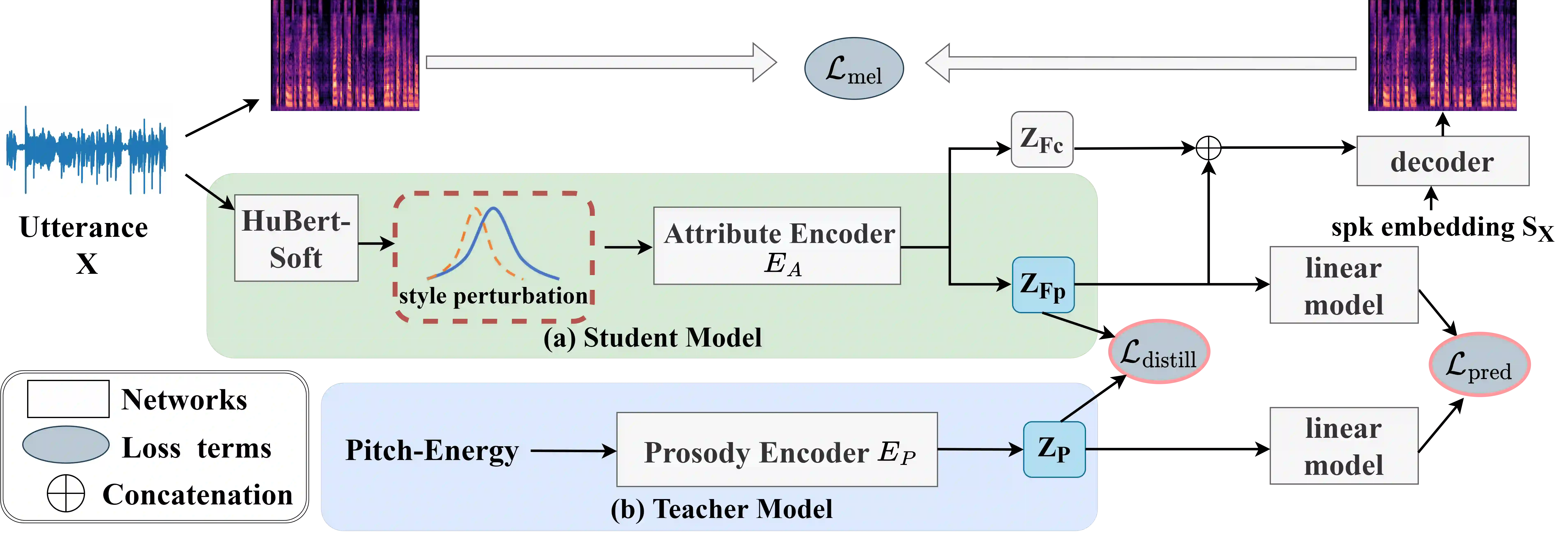
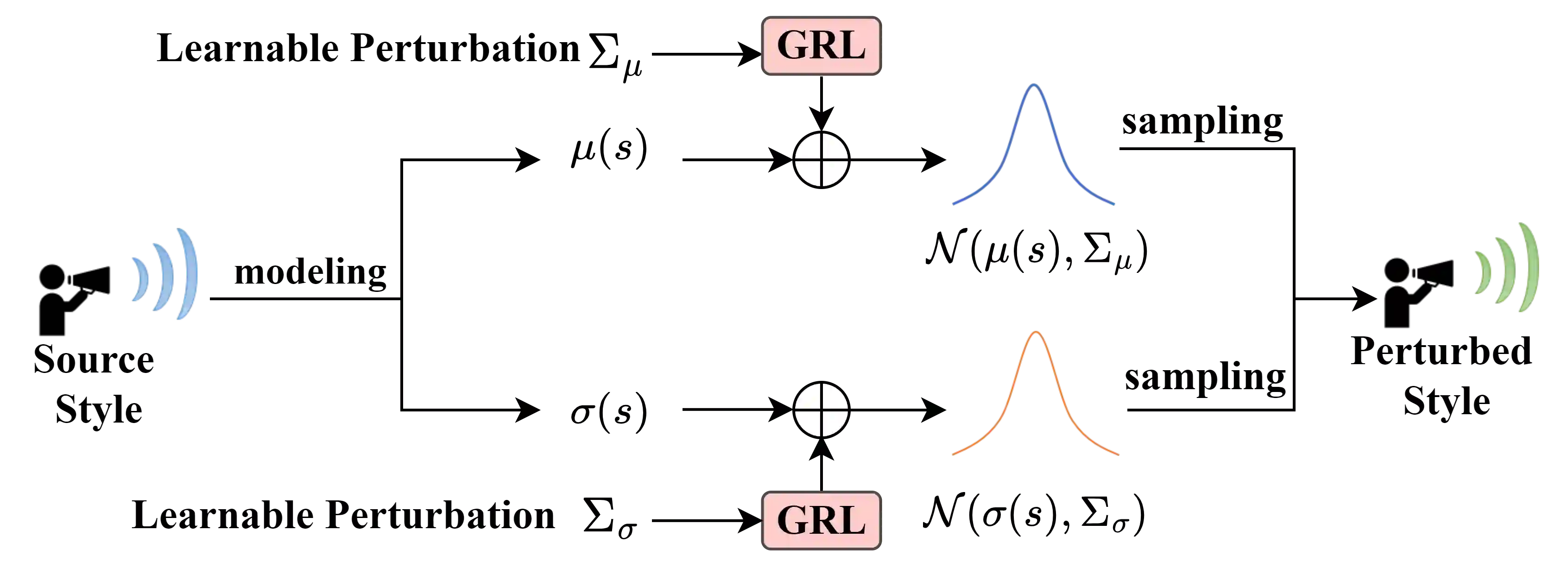
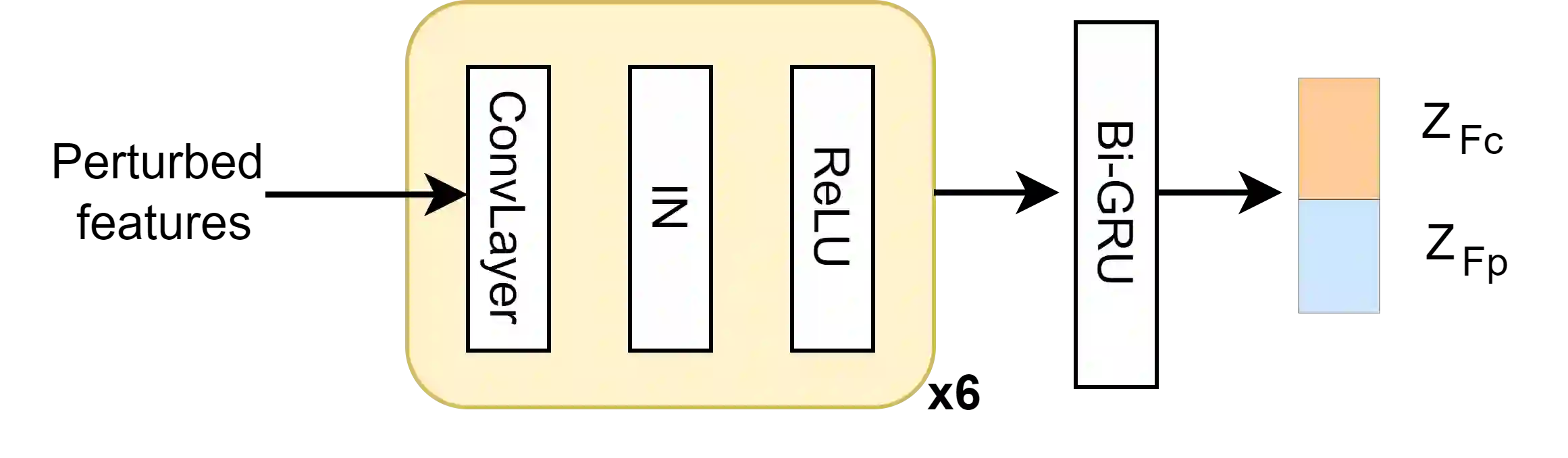
Voice conversion is the task to transform voice characteristics of source speech while preserving content information. Nowadays, self-supervised representation learning models are increasingly utilized in content extraction. However, in these representations, a lot of hidden speaker information leads to timbre leakage while the prosodic information of hidden units lacks use. To address these issues, we propose a novel framework for expressive voice conversion called "SAVC" based on soft speech units from HuBert-soft. Taking soft speech units as input, we design an attribute encoder to extract content and prosody features respectively. Specifically, we first introduce statistic perturbation imposed by adversarial style augmentation to eliminate speaker information. Then the prosody is implicitly modeled on soft speech units with knowledge distillation. Experiment results show that the intelligibility and naturalness of converted speech outperform previous work.
翻译:语音转换旨在保留内容信息的同时改变源语音的声学特征。当前,自监督表示学习模型越来越多地被应用于内容提取任务中。然而,这些表示中隐藏着大量说话人信息导致音色泄露,同时隐单元中的韵律信息未得到充分利用。为解决这些问题,本文提出了一种基于HuBert-soft软语音单元的表达性语音转换新框架"SAVC"。以软语音单元为输入,我们设计了属性编码器分别提取内容与韵律特征。具体而言,首先引入基于对抗风格增强的统计扰动以消除说话人信息,随后通过知识蒸馏在软语音单元上隐式建模韵律特征。实验结果表明,转换语音的可懂度与自然度均优于先前工作。