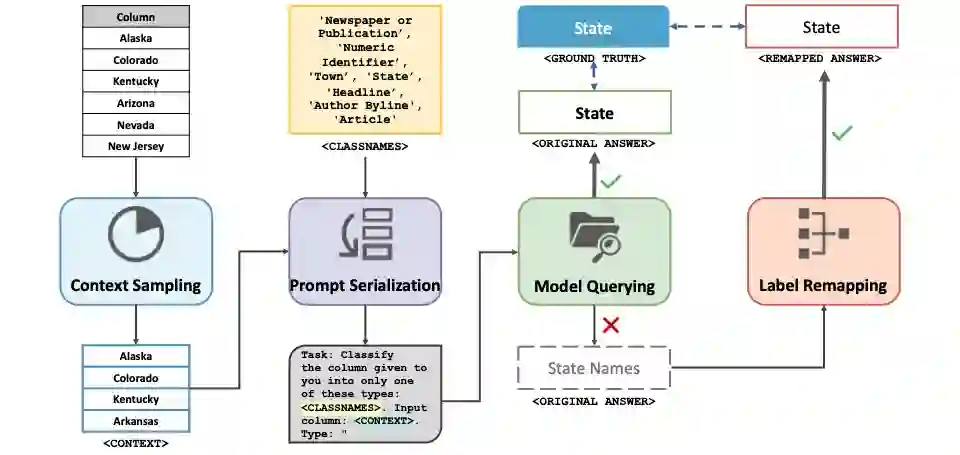
Existing deep-learning approaches to semantic column type annotation (CTA) have important shortcomings: they rely on semantic types which are fixed at training time; require a large number of training samples per type and incur large run-time inference costs; and their performance can degrade when evaluated on novel datasets, even when types remain constant. Large language models have exhibited strong zero-shot classification performance on a wide range of tasks and in this paper we explore their use for CTA. We introduce ArcheType, a simple, practical method for context sampling, prompt serialization, model querying, and label remapping, which enables large language models to solve column type annotation problems in a fully zero-shot manner. We ablate each component of our method separately, and establish that improvements to context sampling and label remapping provide the most consistent gains. ArcheType establishes new state-of-the-art performance on both zero-shot and fine-tuned CTA, including three new domain-specific benchmarks, which we release, along with the code to reproduce our results at https://github.com/penfever/ArcheType.
翻译:现有的基于深度学习的语义列类型标注方法存在重要缺陷:它们依赖训练时固定的语义类型,需要每类大量训练样本且推理成本高昂;当在新型数据集上评估时,即使类型保持不变,其性能也可能下降。大语言模型在广泛任务中展现出强大的零样本分类能力,本文探索了其在列类型标注中的应用。我们提出ArcheType这一简洁实用的方法,包含上下文采样、提示序列化、模型查询和标签重映射四个模块,使大语言模型能够以完全零样本方式解决列类型标注问题。我们分别对每个模块进行消融实验,发现上下文采样和标签重映射的改进能带来最稳定的性能提升。ArcheType在零样本和微调列类型标注任务中均达到当前最优性能,涵盖三个新发布的领域特定基准测试集。相关代码及复现结果详见https://github.com/penfever/ArcheType。