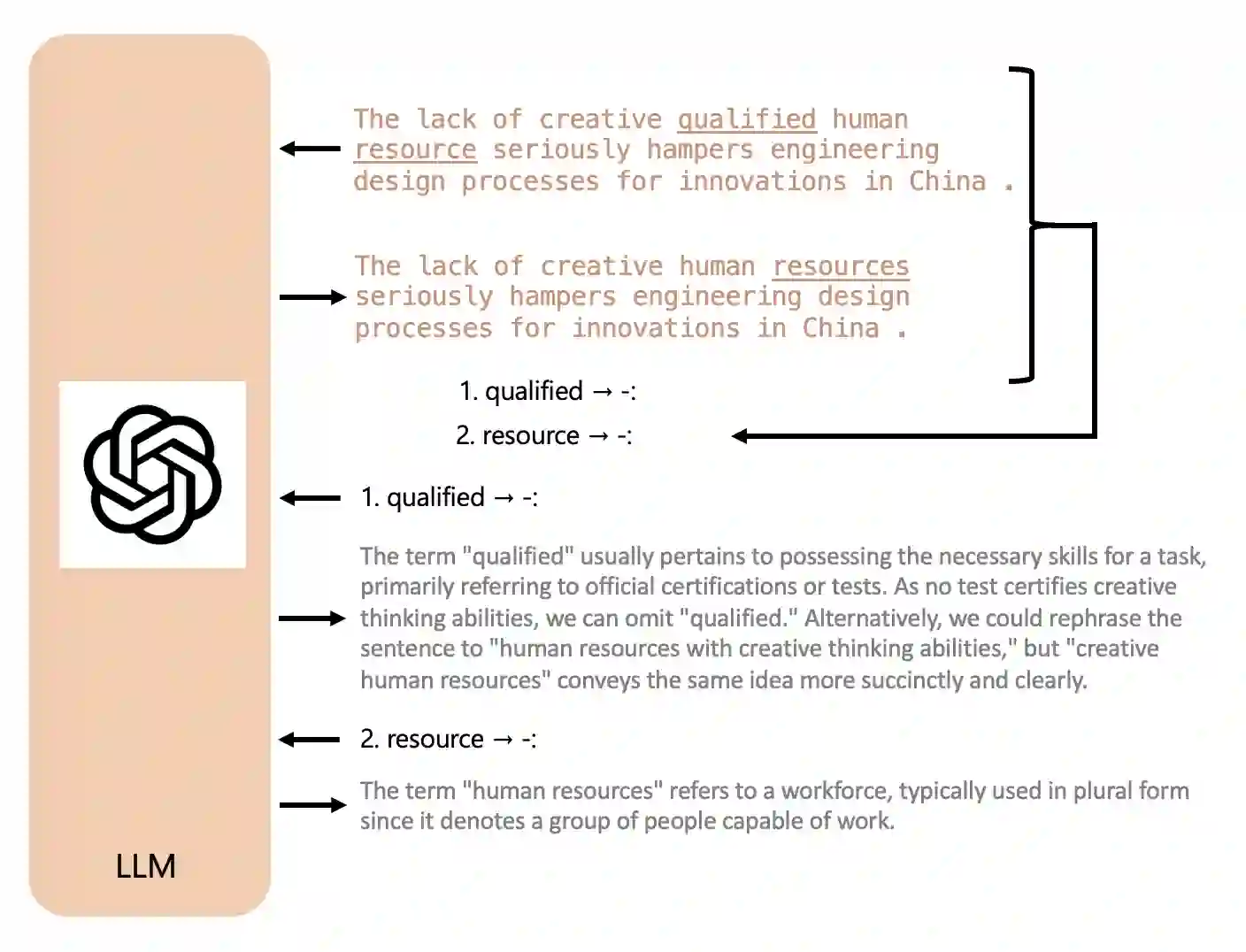
In Grammatical Error Correction (GEC), it is crucial to ensure the user's comprehension of a reason for correction. Existing studies present tokens, examples, and hints as to the basis for correction but do not directly explain the reasons for corrections. Although methods that use Large Language Models (LLMs) to provide direct explanations in natural language have been proposed for various tasks, no such method exists for GEC. Generating explanations for GEC corrections involves aligning input and output tokens, identifying correction points, and presenting corresponding explanations consistently. However, it is not straightforward to specify a complex format to generate explanations, because explicit control of generation is difficult with prompts. This study introduces a method called controlled generation with Prompt Insertion (PI) so that LLMs can explain the reasons for corrections in natural language. In PI, LLMs first correct the input text, and then we automatically extract the correction points based on the rules. The extracted correction points are sequentially inserted into the LLM's explanation output as prompts, guiding the LLMs to generate explanations for the correction points. We also create an Explainable GEC (XGEC) dataset of correction reasons by annotating NUCLE, CoNLL2013, and CoNLL2014. Although generations from GPT-3 and ChatGPT using original prompts miss some correction points, the generation control using PI can explicitly guide to describe explanations for all correction points, contributing to improved performance in generating correction reasons.
翻译:在语法纠错(GEC)中,确保用户理解纠正原因至关重要。现有研究虽提供纠正依据的标记、示例和提示,但未直接解释纠正理由。尽管已有研究利用大语言模型(LLMs)以自然语言直接解释各类任务,但尚无针对GEC的此类方法。生成GEC纠正解释需对齐输入和输出标记、识别纠正点,并一致呈现相应解释。然而,由于提示难以明确控制生成内容,指定复杂格式生成解释并不直接。本研究提出一种名为提示插入(PI)的受控生成方法,使LLMs能够以自然语言解释纠正原因。在PI中,LLMs首先纠正输入文本,随后我们基于规则自动提取纠正点,并将提取的纠正点依次作为提示插入LLM的解释输出中,引导LLMs为纠正点生成解释。我们还通过标注NUCLE、CoNLL2013和CoNLL2014数据集,构建了可解释GEC(XGEC)数据集,包含纠正原因注释。尽管使用原始提示的GPT-3和ChatGPT生成结果遗漏部分纠正点,但基于PI的生成控制能明确引导所有纠正点的解释描述,从而提升纠正原因生成的性能。