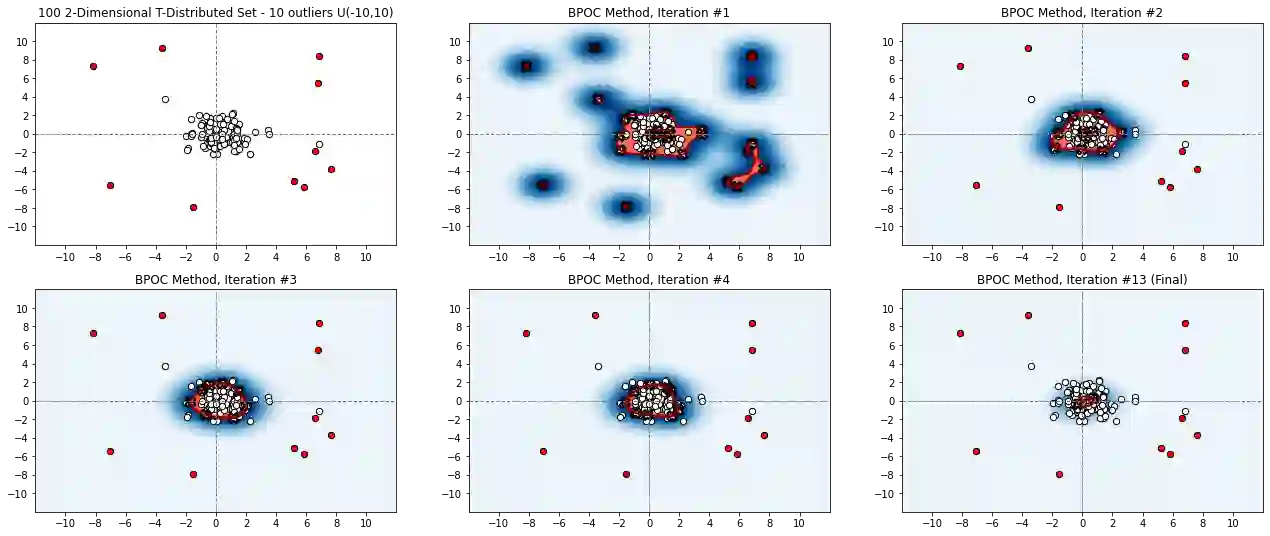
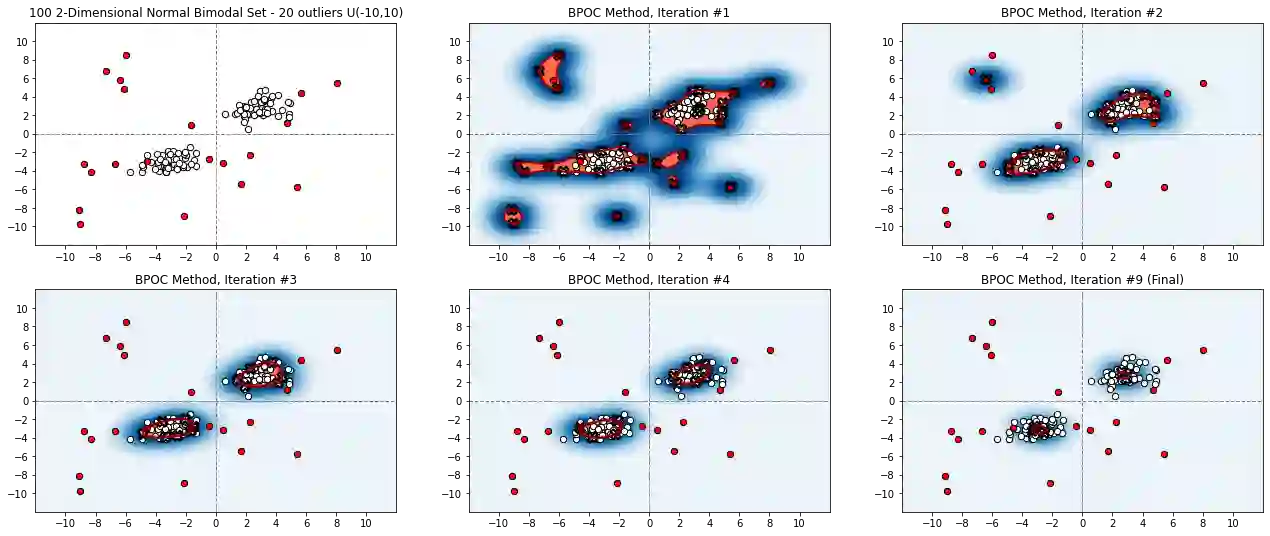
Unsupervised outlier detection constitutes a crucial phase within data analysis and remains a dynamic realm of research. A good outlier detection algorithm should be computationally efficient, robust to tuning parameter selection, and perform consistently well across diverse underlying data distributions. We introduce One-Class Boundary Peeling, an unsupervised outlier detection algorithm. One-class Boundary Peeling uses the average signed distance from iteratively-peeled, flexible boundaries generated by one-class support vector machines. One-class Boundary Peeling has robust hyperparameter settings and, for increased flexibility, can be cast as an ensemble method. In synthetic data simulations One-Class Boundary Peeling outperforms all state of the art methods when no outliers are present while maintaining comparable or superior performance in the presence of outliers, as compared to benchmark methods. One-Class Boundary Peeling performs competitively in terms of correct classification, AUC, and processing time using common benchmark data sets.
翻译:无监督离群点检测构成数据分析中的关键阶段,并始终是充满活力的研究领域。优秀的离群点检测算法应具备计算高效性、对调参选择的鲁棒性,并在多样化的潜在数据分布中保持稳定性能。我们提出单类边界剥离算法——一种无监督离群点检测方法。该算法利用来自单类支持向量机逐次剥离柔性边界的平均带符号距离。单类边界剥离具有稳健的超参数设置,且为增强灵活性可作为集成方法实现。合成数据模拟显示:在无离群点情况下,单类边界剥离优于所有现有最优方法;在存在离群点时,其性能与基准方法相当或更优。基于常见基准数据集,该算法在正确分类率、AUC及处理时间方面均表现出竞争性优势。