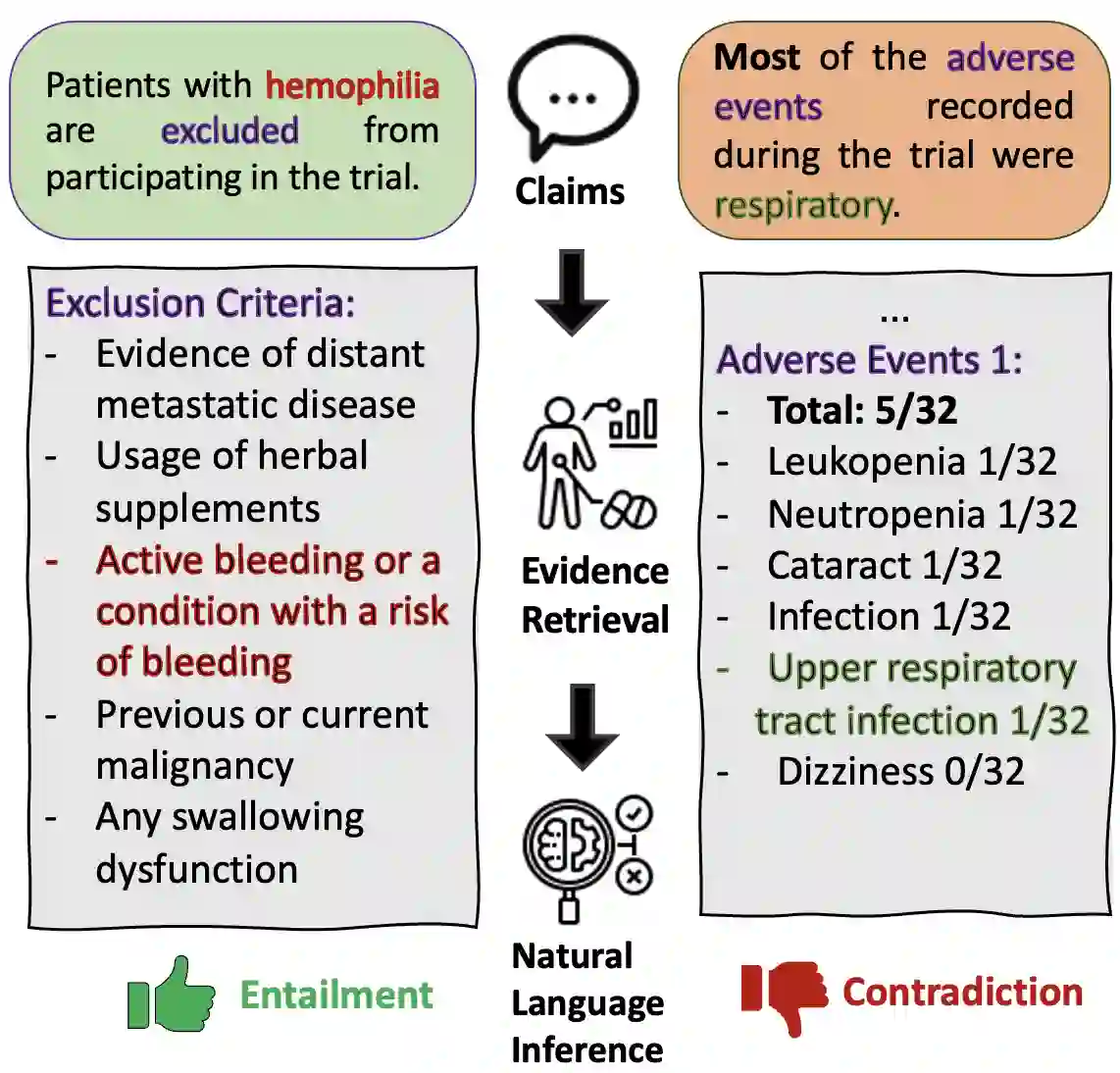
With the increasing number of clinical trial reports generated every day, it is becoming hard to keep up with novel discoveries that inform evidence-based healthcare recommendations. To help automate this process and assist medical experts, NLP solutions are being developed. This motivated the SemEval-2023 Task 7, where the goal was to develop an NLP system for two tasks: evidence retrieval and natural language inference from clinical trial data. In this paper, we describe our two developed systems. The first one is a pipeline system that models the two tasks separately, while the second one is a joint system that learns the two tasks simultaneously with a shared representation and a multi-task learning approach. The final system combines their outputs in an ensemble system. We formalize the models, present their characteristics and challenges, and provide an analysis of achieved results. Our system ranked 3rd out of 40 participants with a final submission.
翻译:随着每日产生的临床试验报告数量不断增加,人们越来越难以跟上为循证医疗建议提供依据的新发现。为助力这一过程的自动化并辅助医学专家,自然语言处理(NLP)解决方案正在研发中。这催生了SemEval-2023任务7,其目标是从临床试验数据中开发一个面向两项任务的NLP系统:证据检索与自然语言推理。本文描述了我们开发的两个系统:第一个是分别建模这两项任务的流水线系统,第二个是采用共享表征与多任务学习方法同时学习这两项任务的联合系统。最终系统通过集成方法结合两者的输出。我们对模型进行了形式化定义,阐述了其特性与挑战,并对所获结果进行了分析。在最终提交中,我们的系统在40个参赛者中排名第三。