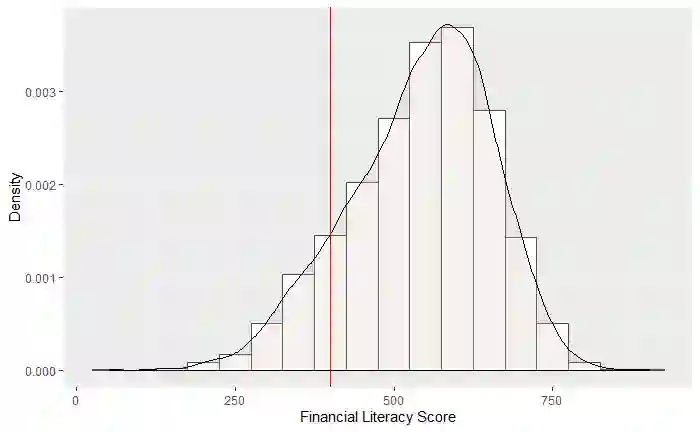
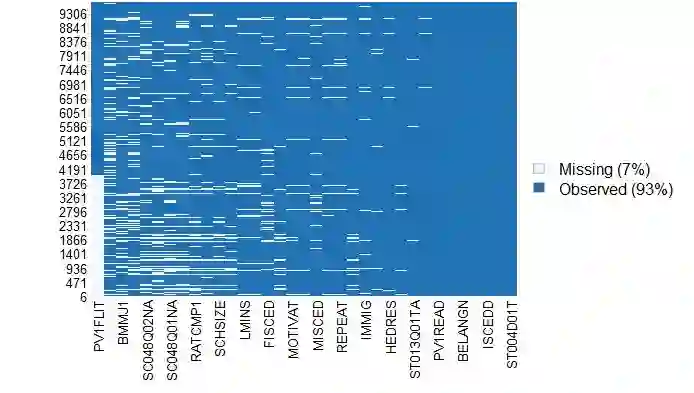
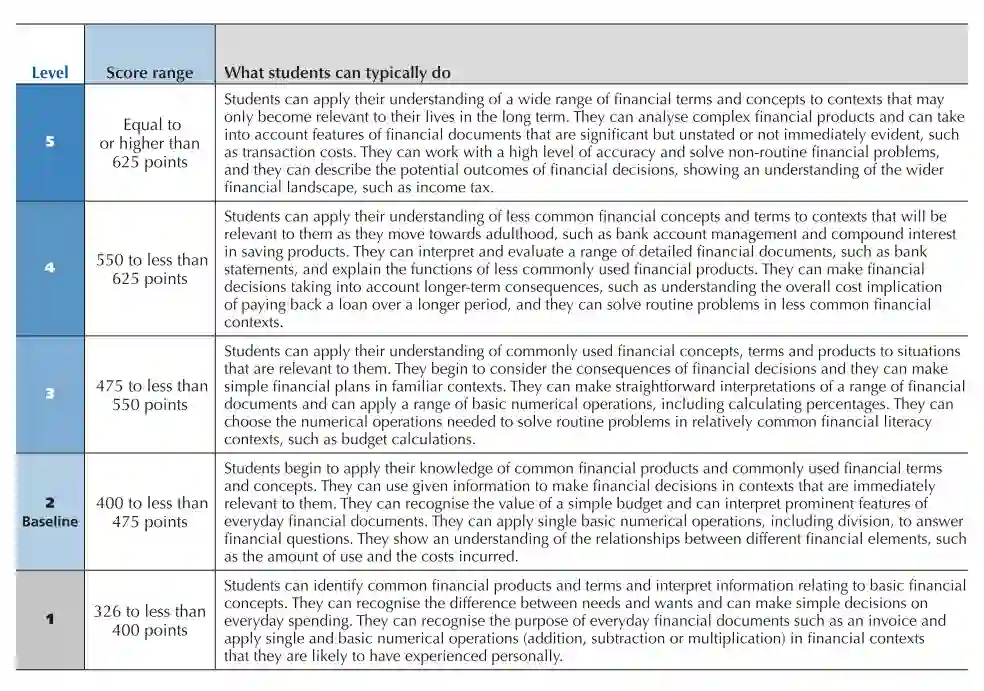
Educational policymakers often lack data on student outcomes in regions where standardized tests were not administered. Machine learning techniques can be used to predict unobserved outcomes in target populations by training models on data from a source population. However, differences between the source and target populations, particularly in covariate distributions, can reduce the transportability of these models, potentially reducing predictive accuracy and introducing bias. We propose using double machine learning for a covariate-shift weighted model. First, we estimate the overlap score-namely, the probability that an observation belongs to the source dataset given its covariates. Second, balancing weights, defined as the density ratio of target-to-source membership probabilities, are used to reweight the individual observations' contribution to the loss or likelihood function in the target outcome prediction model. This approach downweights source observations that are less similar to the target population, allowing predictions to rely more heavily on observations with greater overlap. As a result, predictions become more generalizable under covariate shift. We illustrate this framework in the context of uncertain data on students' standardized financial literacy scores (FLS). Using Bayesian Additive Regression Trees (BART), we predict missing FLS. We find minimal differences in predictive performance between the weighted and unweighted models, suggesting limited covariate shift in our empirical setting. Nonetheless, the proposed approach provides a principled framework for addressing covariate shift and is broadly applicable to predictive modeling in the social and health sciences, where differences between source and target populations are common.
翻译:教育政策制定者常面临标准化测试未实施地区学生学业成果数据缺失的问题。机器学习技术可通过在源群体数据上训练模型,预测目标群体中未观测的成果。然而,源群体与目标群体之间的差异(特别是协变量分布的差异)会降低这些模型的可迁移性,可能导致预测准确性下降并引入偏差。本文提出采用双重机器学习构建协变量偏移加权模型:首先估计重叠分数(即给定协变量条件下观测样本属于源数据集的概率);其次定义平衡权重(目标群体与源群体隶属概率的密度比),用于重新加权个体观测在目标成果预测模型的损失函数或似然函数中的贡献度。该方法降低与目标群体相似度较低的源观测样本的权重,使预测更依赖于重叠度较高的观测样本,从而提升模型在协变量偏移下的泛化能力。我们以学生标准化金融素养分数(FLS)的不确定性数据为例,采用贝叶斯加性回归树(BART)预测缺失的FLS。研究发现加权模型与未加权模型的预测性能差异极小,表明实证场景中协变量偏移有限。尽管如此,所提方法为处理协变量偏移提供了理论框架,可广泛适用于源群体与目标群体存在差异的社会科学与健康科学预测建模领域。