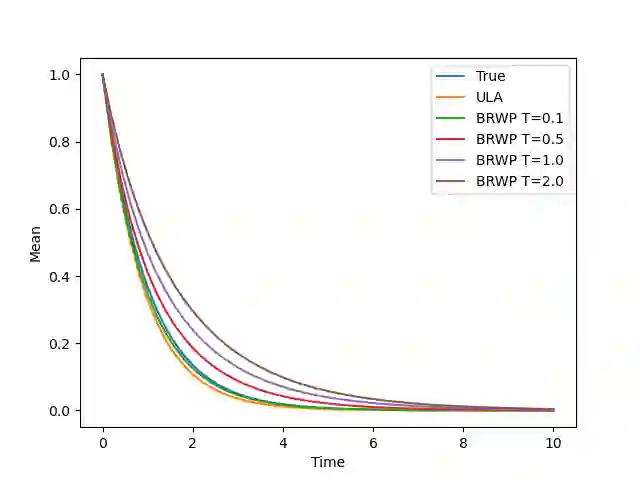
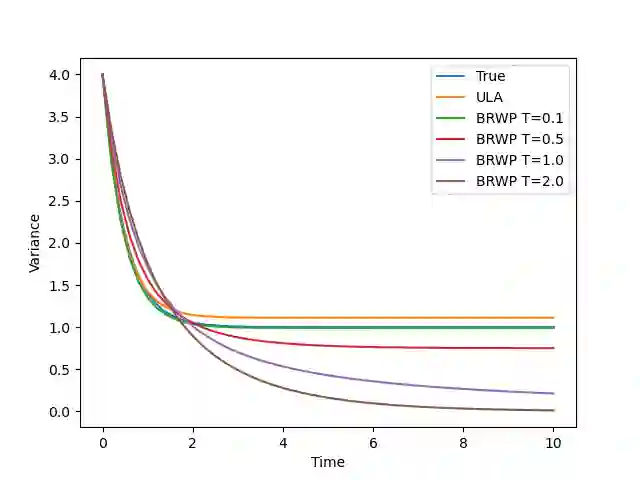
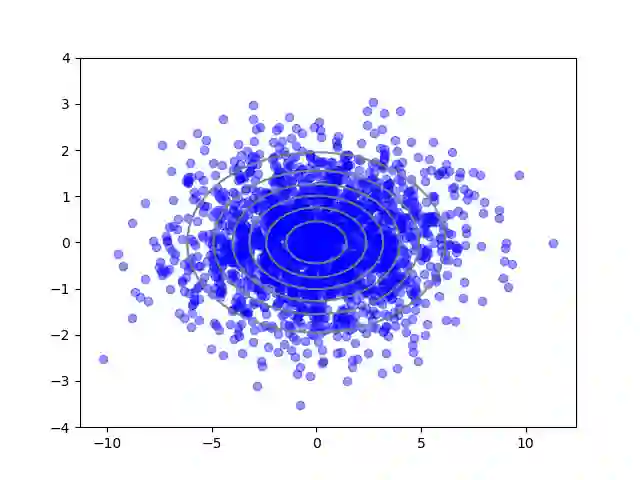
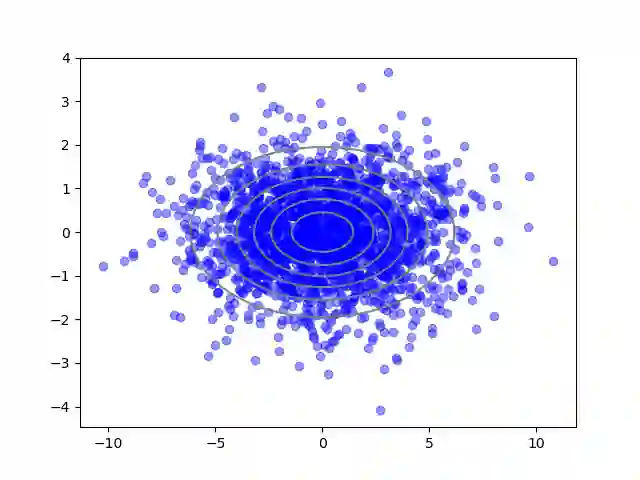
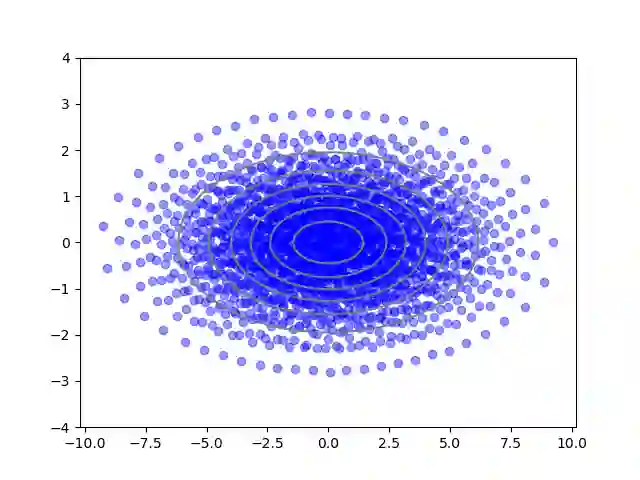
We consider the problem of sampling from a distribution governed by a potential function. This work proposes an explicit score based MCMC method that is deterministic, resulting in a deterministic evolution for particles rather than a stochastic differential equation evolution. The score term is given in closed form by a regularized Wasserstein proximal, using a kernel convolution that is approximated by sampling. We demonstrate fast convergence on various problems and show improved dimensional dependence of mixing time bounds for the case of Gaussian distributions compared to the unadjusted Langevin algorithm (ULA) and the Metropolis-adjusted Langevin algorithm (MALA). We additionally derive closed form expressions for the distributions at each iterate for quadratic potential functions, characterizing the variance reduction. Empirical results demonstrate that the particles behave in an organized manner, lying on level set contours of the potential. Moreover, the posterior mean estimator of the proposed method is shown to be closer to the maximum a-posteriori estimator compared to ULA and MALA in the context of Bayesian logistic regression. Additional examples demonstrate competitive performance for Bayesian neural network training.
翻译:我们考虑从由势函数支配的分布中进行采样的问题。本文提出了一种显式基于分数的确定性马尔可夫链蒙特卡洛方法,该方法导致粒子的确定性演化而非随机微分方程演化。分数项由正则化Wasserstein近端以闭式给出,并通过采样近似的核卷积实现。我们在多种问题上展示了快速收敛性,并针对高斯分布情况,与未调整的朗之万算法(ULA)和Metropolis调整的朗之万算法(MALA)相比,证明了混合时间界限的维度依赖性有所改善。此外,针对二次势函数,我们推导了每次迭代分布的闭式表达式,刻画了方差缩减特性。实验结果表明,粒子以有序方式运动,分布在势函数的水平集轮廓上。在贝叶斯逻辑回归背景下,所提方法的后验均值估计器比ULA和MALA更接近最大后验估计器。其他示例证明了该方法在贝叶斯神经网络训练中的竞争性能。