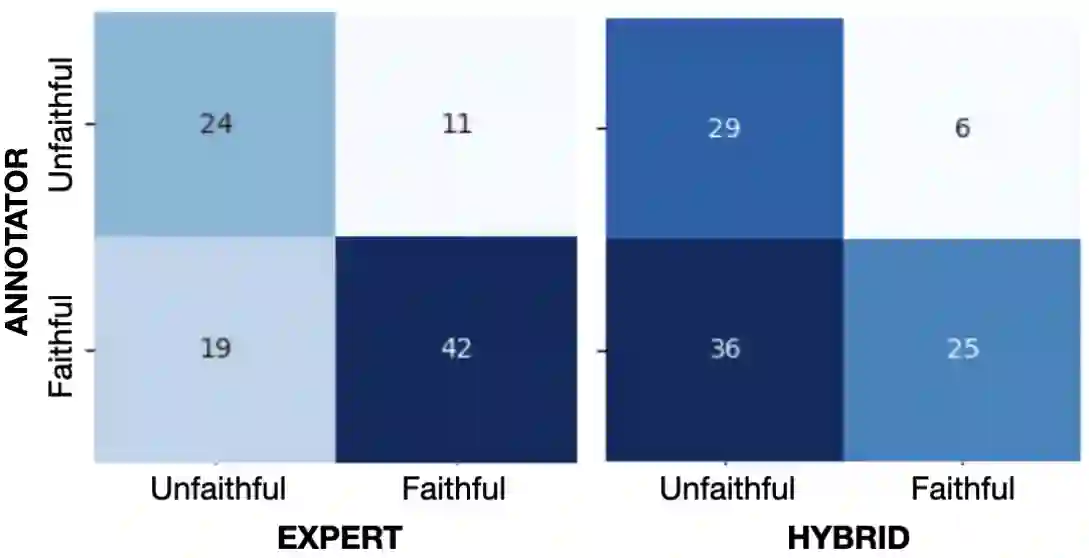
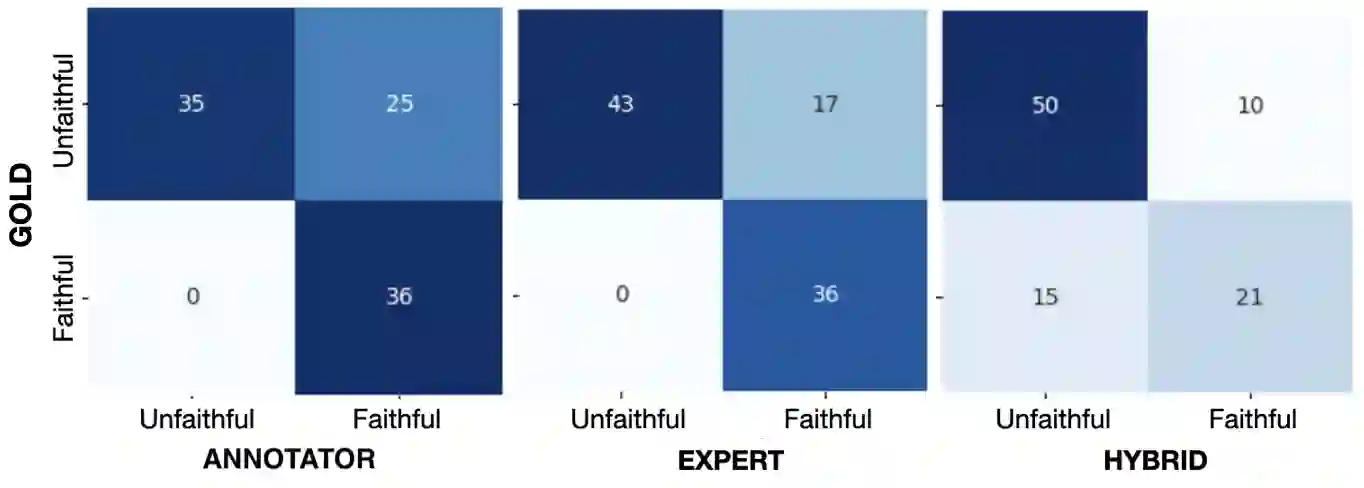
Human evaluation has been the gold standard for checking faithfulness in abstractive summarization. However, with a challenging source domain like narrative, multiple annotators can agree a summary is faithful, while missing details that are obvious errors only once pointed out. We therefore introduce a new dataset, STORYSUMM, comprising LLM summaries of short stories with localized faithfulness labels and error explanations. This benchmark is for evaluation methods, testing whether a given method can detect challenging inconsistencies. Using this dataset, we first show that any one human annotation protocol is likely to miss inconsistencies, and we advocate for pursuing a range of methods when establishing ground truth for a summarization dataset. We finally test recent automatic metrics and find that none of them achieve more than 70% balanced accuracy on this task, demonstrating that it is a challenging benchmark for future work in faithfulness evaluation.
翻译:人工评估一直是检验抽象摘要忠实度的黄金标准。然而,对于像叙事这样具有挑战性的源领域,多名标注者可能一致认为某个摘要是忠实的,却忽略了那些一经指出便显属错误的细节。为此,我们引入了一个新的数据集STORYSUMM,它包含由大语言模型生成的短故事摘要,并配有局部化的忠实度标签和错误解释。该基准旨在评估各种方法,测试给定方法能否检测出具有挑战性的不一致之处。利用该数据集,我们首先表明任何一种人工标注方案都可能遗漏不一致性,因此我们主张在为摘要数据集建立真实基准时,应采用多种方法。最后,我们测试了最新的自动评估指标,发现它们在此任务上的平衡准确率均未超过70%,这表明该基准对于未来忠实度评估的研究而言是一个具有挑战性的测试平台。