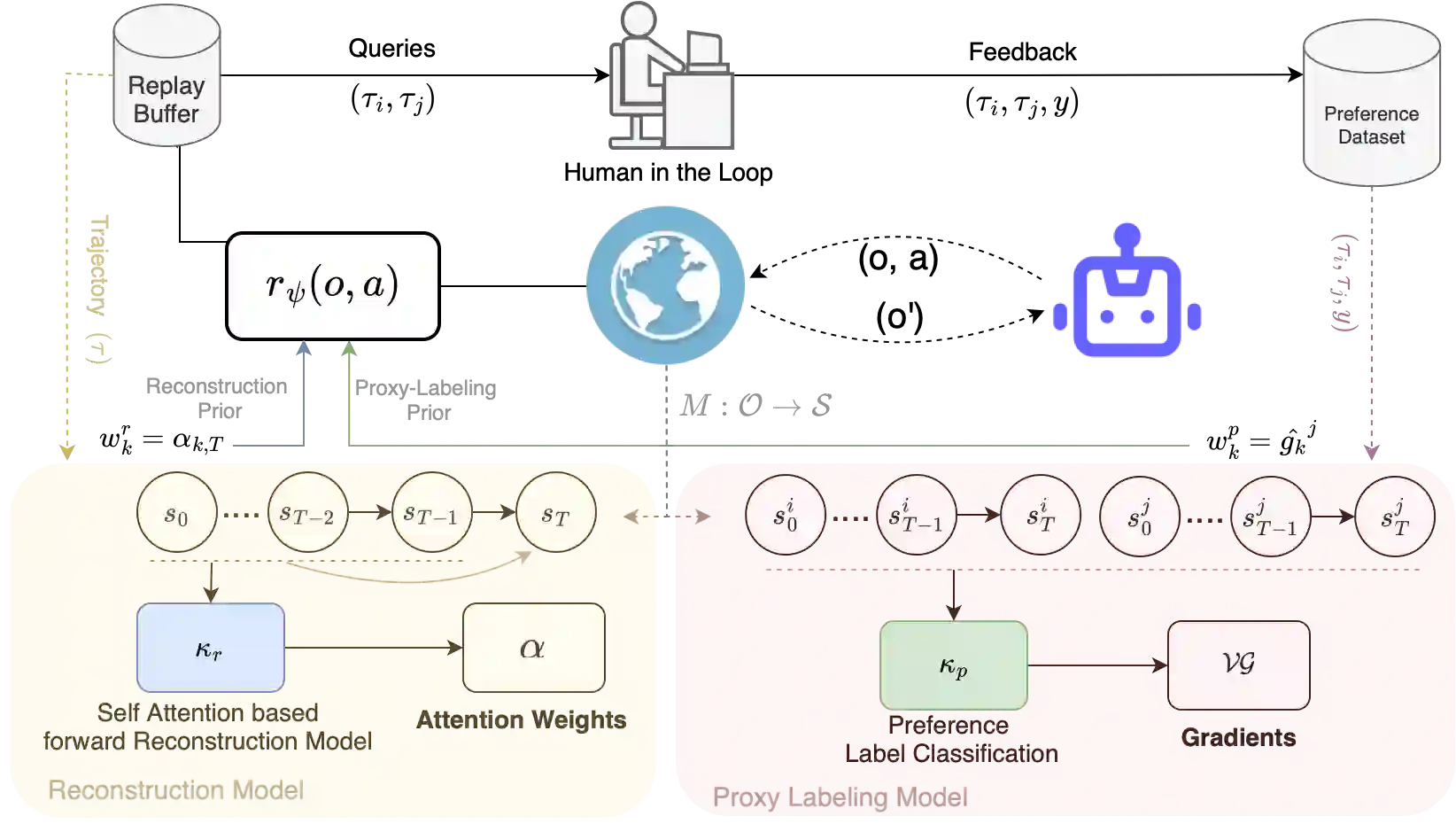
Specifying rewards for reinforcement learned (RL) agents is challenging. Preference-based RL (PbRL) mitigates these challenges by inferring a reward from feedback over sets of trajectories. However, the effectiveness of PbRL is limited by the amount of feedback needed to reliably recover the structure of the target reward. We present the PRIor Over Rewards (PRIOR) framework, which incorporates priors about the structure of the reward function and the preference feedback into the reward learning process. Imposing these priors as soft constraints on the reward learning objective reduces the amount of feedback required by half and improves overall reward recovery. Additionally, we demonstrate that using an abstract state space for the computation of the priors further improves the reward learning and the agent's performance.
翻译:指定已获得的强化(RL)代理人的奖赏具有挑战性。基于优惠的RL(PbRL)通过从一组轨迹的反馈中推断出一种奖赏来减轻这些挑战。然而,PbRL的效力受到可靠恢复目标奖赏结构所需的反馈数量的限制。我们提出了Prior overwards(PRIOR)框架,该框架将奖赏功能结构的先例和优先反馈纳入奖赏学习过程。这些前科作为奖励学习目标的软约束,减少了一半所需反馈的数量,改善了总体奖赏回收。此外,我们证明利用抽象状态计算前科,可以进一步提高奖赏学习和代理人的业绩。