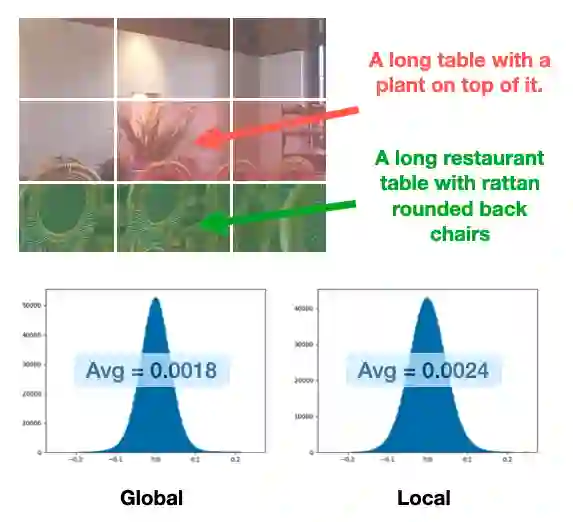
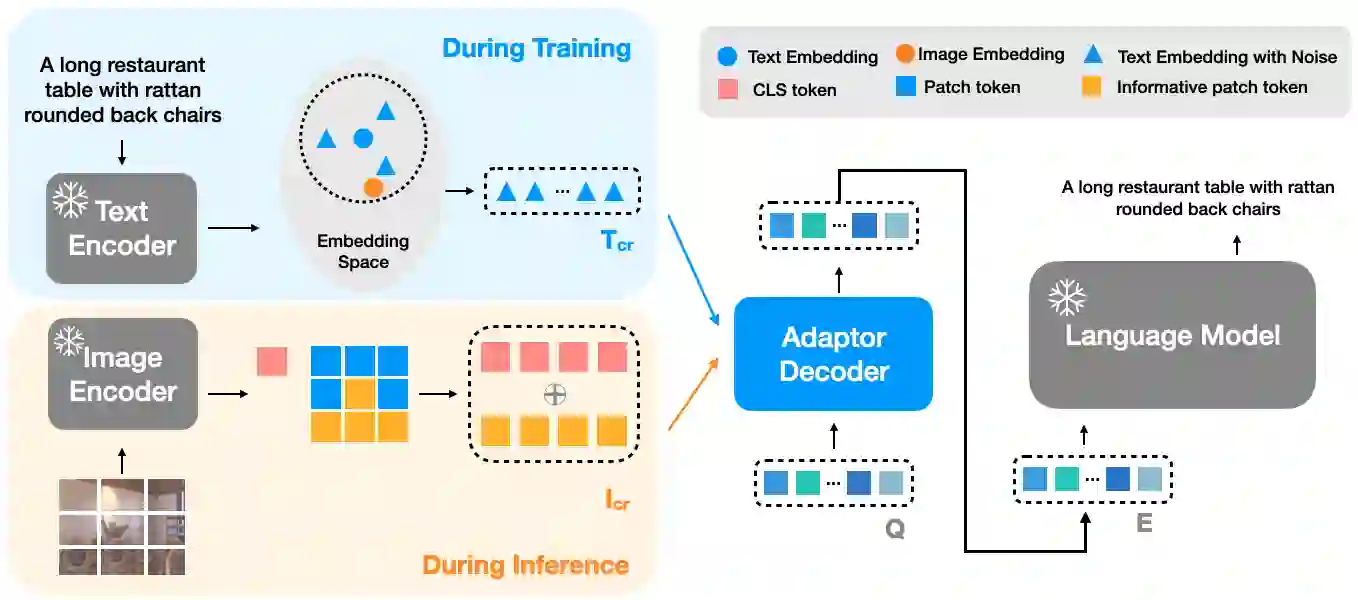
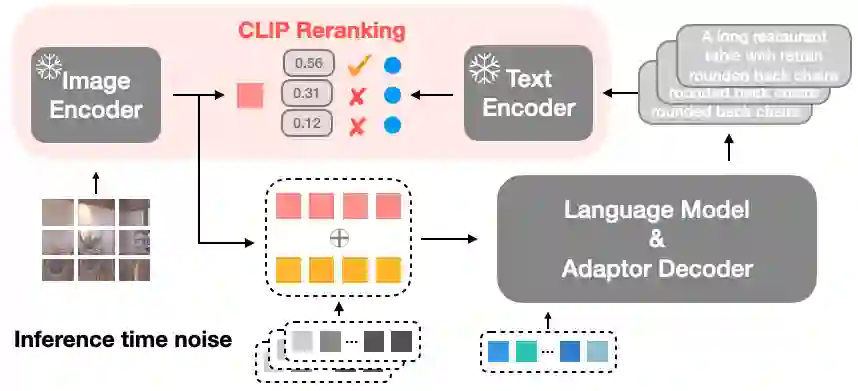
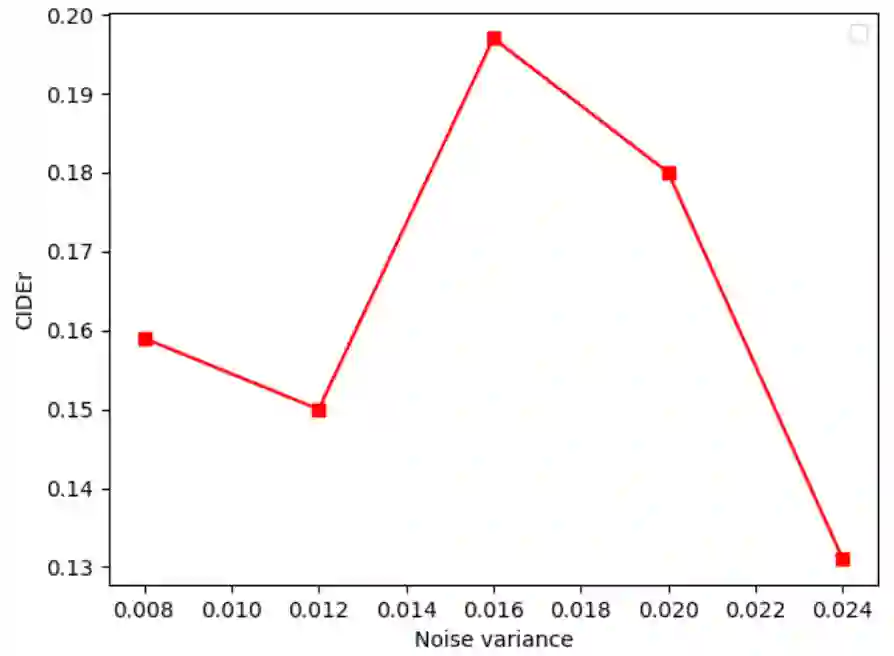
Image captioning aims at generating descriptive and meaningful textual descriptions of images, enabling a broad range of vision-language applications. Prior works have demonstrated that harnessing the power of Contrastive Image Language Pre-training (CLIP) offers a promising approach to achieving zero-shot captioning, eliminating the need for expensive caption annotations. However, the widely observed modality gap in the latent space of CLIP harms the performance of zero-shot captioning by breaking the alignment between paired image-text features. To address this issue, we conduct an analysis on the CLIP latent space which leads to two findings. Firstly, we observe that the CLIP's visual feature of image subregions can achieve closer proximity to the paired caption due to the inherent information loss in text descriptions. In addition, we show that the modality gap between a paired image-text can be empirically modeled as a zero-mean Gaussian distribution. Motivated by the findings, we propose a novel zero-shot image captioning framework with text-only training to reduce the modality gap. In particular, we introduce a subregion feature aggregation to leverage local region information, which produces a compact visual representation for matching text representation. Moreover, we incorporate a noise injection and CLIP reranking strategy to boost captioning performance. We also extend our framework to build a zero-shot VQA pipeline, demonstrating its generality. Through extensive experiments on common captioning and VQA datasets such as MSCOCO, Flickr30k and VQAV2, we show that our method achieves remarkable performance improvements. Code is available at https://github.com/Artanic30/MacCap.
翻译:图像描述旨在为图像生成描述性强且富有意义的文本描述,支撑广泛的视觉-语言应用。先前研究表明,利用对比图像-语言预训练(CLIP)的力量为零样本图像描述提供了有前景的途径,从而避免了对昂贵标注数据的依赖。然而,CLIP潜空间中普遍存在的模态鸿沟问题会破坏图像-文本对特征的对其,进而损害零样本图像描述的性能。为解决该问题,我们对CLIP潜空间展开分析,得出两项发现:首先,观察到因文本描述固有的信息损失,CLIP对图像子区域的视觉特征能与对应描述文本在特征空间中实现更近邻的匹配;其次,证明图像-文本对的模态间隙可经验性地建模为零均值高斯分布。受这些发现启发,我们提出一种仅需文本训练的新型零样本图像描述框架,旨在缩小模态间隙。具体而言,我们引入子区域特征聚合机制,通过利用局部区域信息生成紧凑的视觉表征以匹配文本表征。此外,我们融合噪声注入与CLIP重排序策略以提升描述性能。为验证框架通用性,我们将其扩展为零样本VQA流水线。在MSCOCO、Flickr30k和VQAv2等通用图像描述与VQA数据集上的大量实验表明,该方法取得了显著的性能提升。代码开源地址:https://github.com/Artanic30/MacCap。