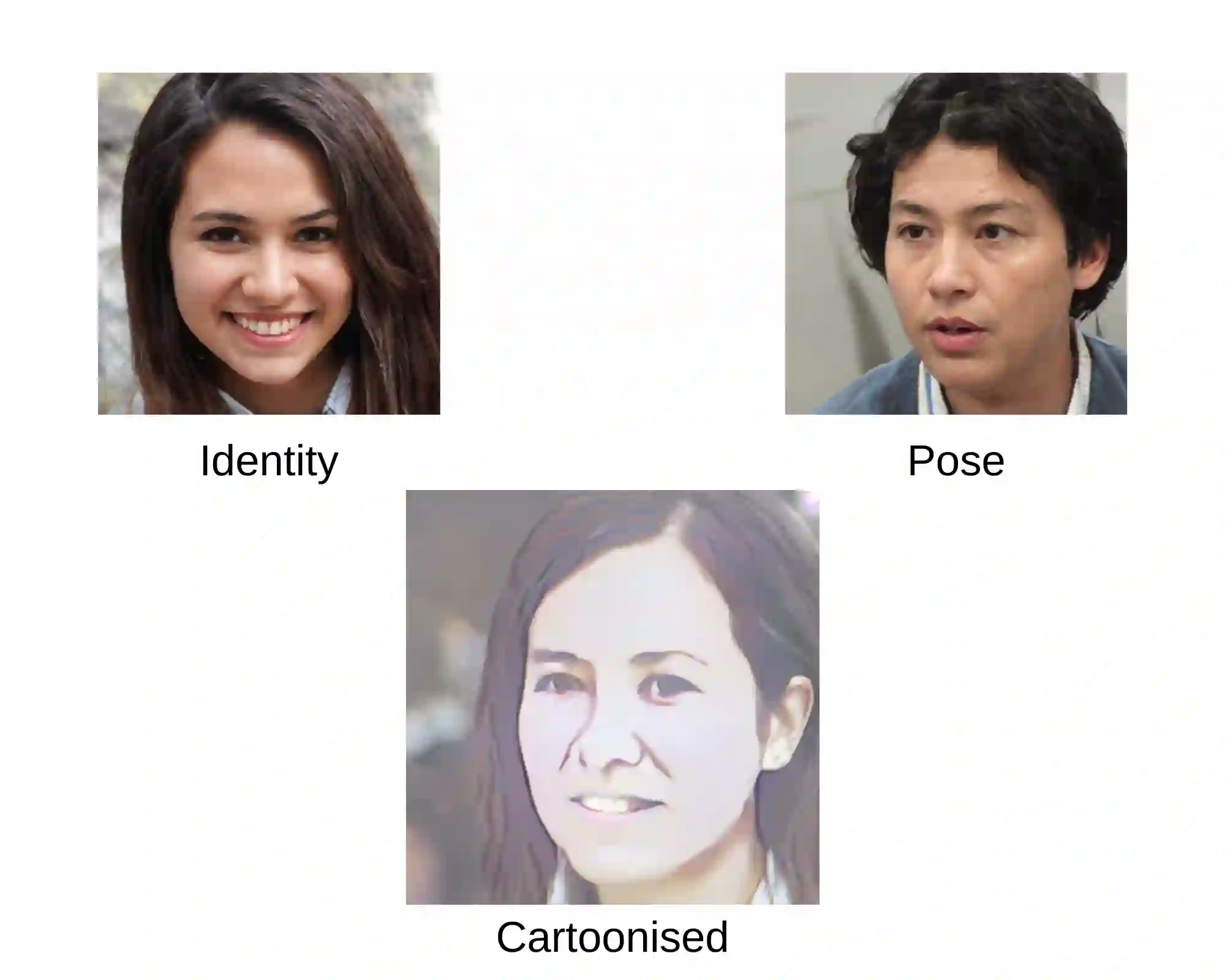
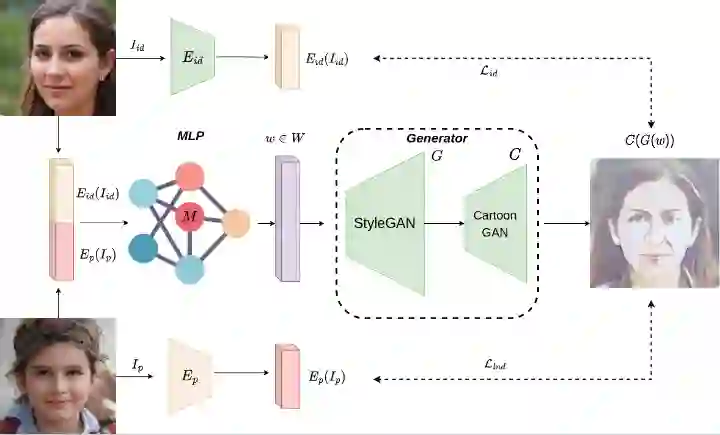
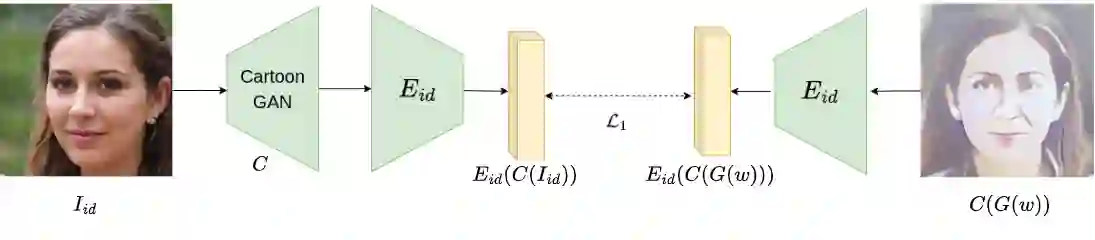
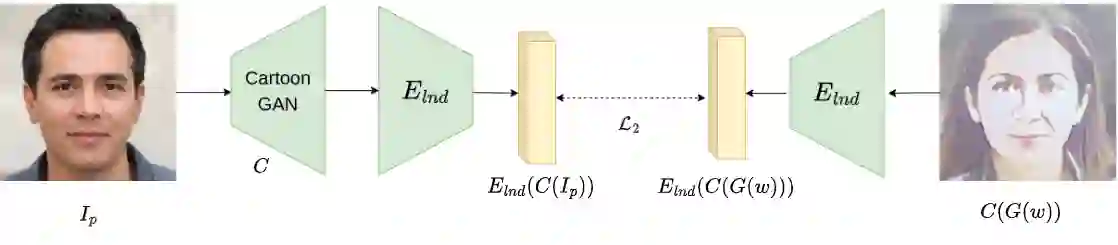
This paper presents an innovative approach to achieve face cartoonisation while preserving the original identity and accommodating various poses. Unlike previous methods in this field that relied on conditional-GANs, which posed challenges related to dataset requirements and pose training, our approach leverages the expressive latent space of StyleGAN. We achieve this by introducing an encoder that captures both pose and identity information from images and generates a corresponding embedding within the StyleGAN latent space. By subsequently passing this embedding through a pre-trained generator, we obtain the desired cartoonised output. While many other approaches based on StyleGAN necessitate a dedicated and fine-tuned StyleGAN model, our method stands out by utilizing an already-trained StyleGAN designed to produce realistic facial images. We show by extensive experimentation how our encoder adapts the StyleGAN output to better preserve identity when the objective is cartoonisation.
翻译:本文提出了一种创新方法,在保留原始身份特征的同时实现人脸卡通化,并能适配多种姿态。与以往依赖条件生成对抗网络(conditional-GANs)的研究不同——这类方法存在数据集需求与姿态训练方面的挑战——本方法充分利用了StyleGAN的潜在空间表达能力。我们通过引入编码器来实现这一目标,该编码器能够从图像中提取姿态与身份信息,并在StyleGAN潜在空间中生成对应的嵌入向量。随后将该嵌入向量输入预训练生成器,即可获得所需的卡通化输出。尽管许多基于StyleGAN的方法需要专门微调的模型,本方法的独特之处在于直接使用已训练好的、用于生成逼真人脸的StyleGAN模型。通过大量实验证明,我们的编码器能够使StyleGAN输出在卡通化任务中更好地保留原始身份特征。