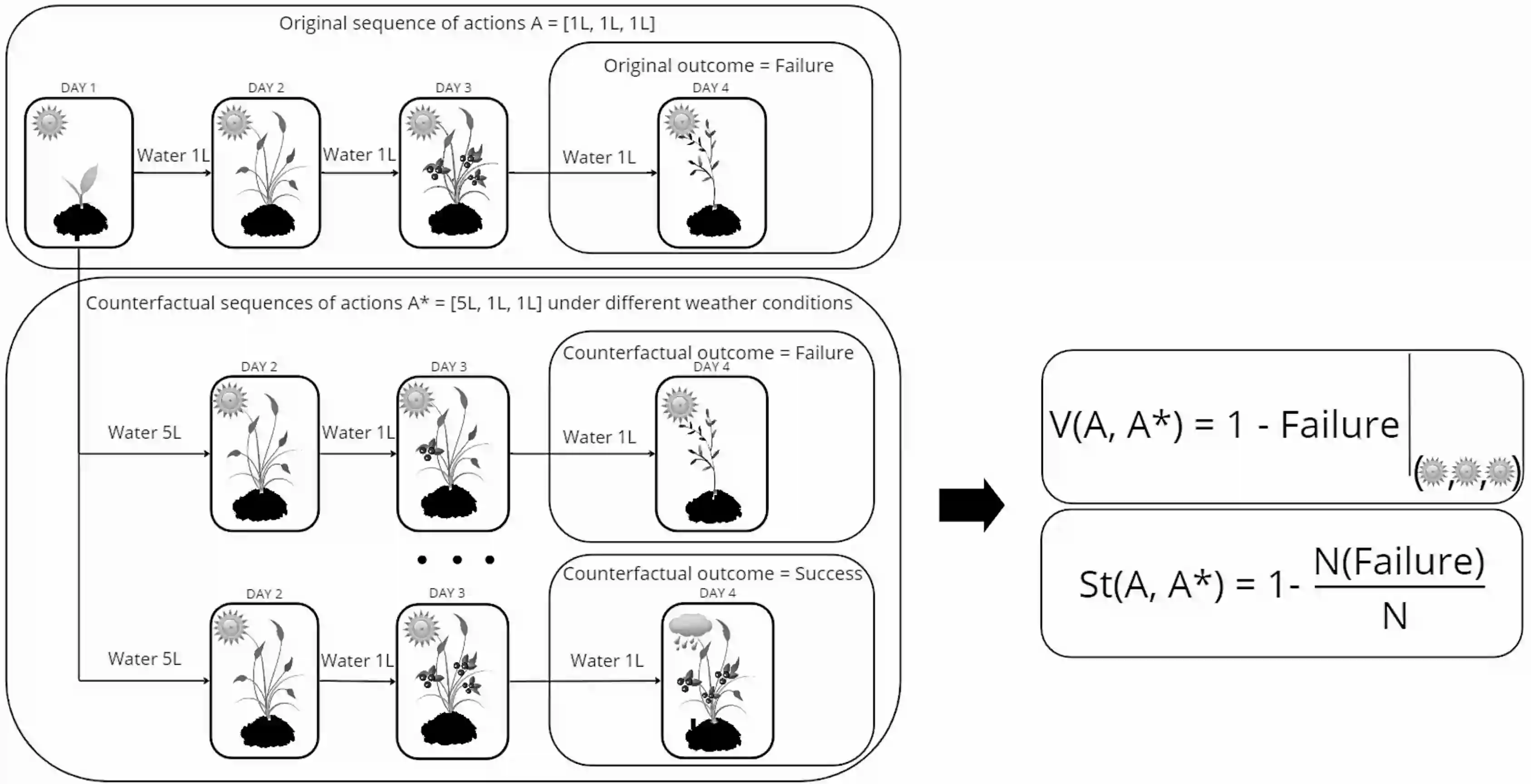
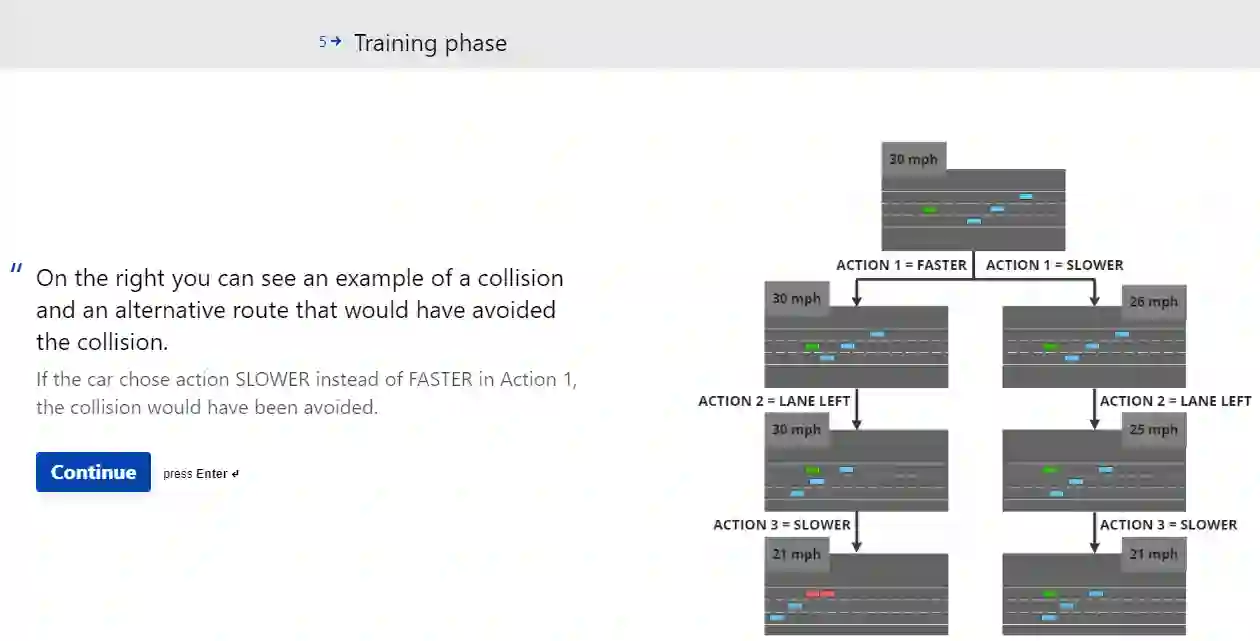
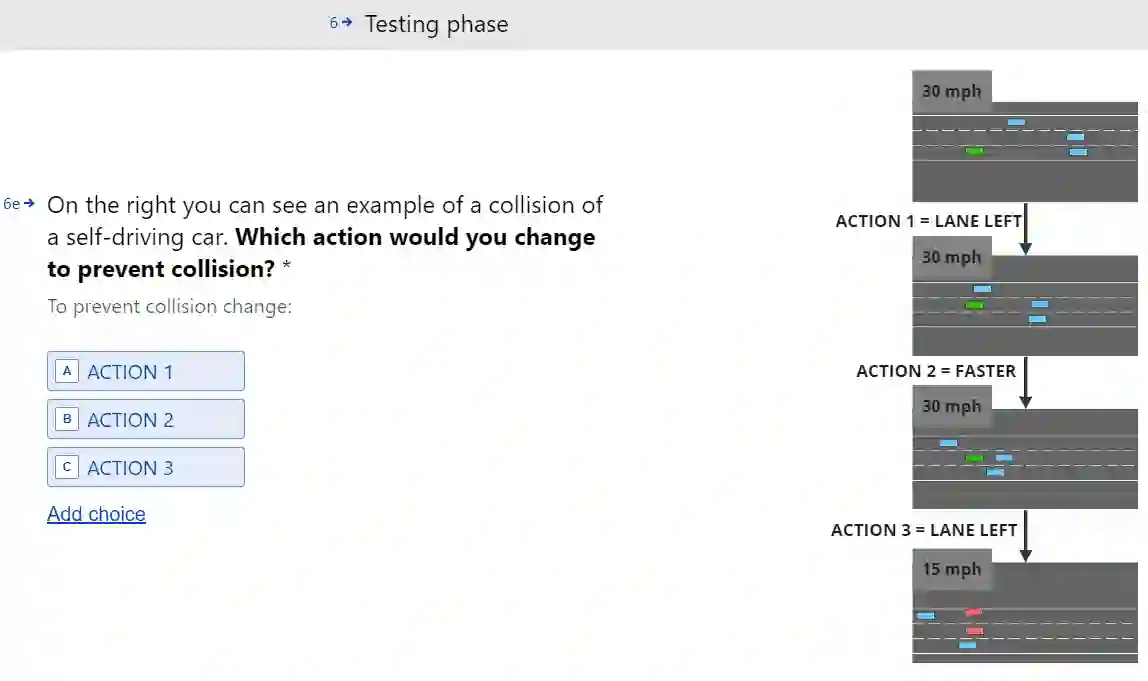
Understanding how failure occurs and how it can be prevented in reinforcement learning (RL) is necessary to enable debugging, maintain user trust, and develop personalized policies. Counterfactual reasoning has often been used to assign blame and understand failure by searching for the closest possible world in which the failure is avoided. However, current counterfactual state explanations in RL can only explain an outcome using just the current state features and offer no actionable recourse on how a negative outcome could have been prevented. In this work, we propose ACTER (Actionable Counterfactual Sequences for Explaining Reinforcement Learning Outcomes), an algorithm for generating counterfactual sequences that provides actionable advice on how failure can be avoided. ACTER investigates actions leading to a failure and uses the evolutionary algorithm NSGA-II to generate counterfactual sequences of actions that prevent it with minimal changes and high certainty even in stochastic environments. Additionally, ACTER generates a set of multiple diverse counterfactual sequences that enable users to correct failure in the way that best fits their preferences. We also introduce three diversity metrics that can be used for evaluating the diversity of counterfactual sequences. We evaluate ACTER in two RL environments, with both discrete and continuous actions, and show that it can generate actionable and diverse counterfactual sequences. We conduct a user study to explore how explanations generated by ACTER help users identify and correct failure.
翻译:理解强化学习中失败的发生原因及其预防方法,对于实现调试、维护用户信任以及开发个性化策略至关重要。反事实推理常被用于归因和解释失败,通过搜索最接近且能够避免失败的可能情境来实现。然而,目前强化学习中的反事实状态解释仅能基于当前状态特征解释结果,却无法提供可操作的补救方案来阐明如何预防负面结果。本研究提出ACTER(可操作反事实序列用于解释强化学习结果)算法,通过生成反事实序列提供避免失败的可操作建议。ACTER分析导致失败的动作序列,并利用进化算法NSGA-II生成反事实动作序列——即使在随机环境中,该序列也能以最小变更和高度确定性避免失败。此外,ACTER可生成一组多样化的反事实序列,使用户能够根据自身偏好选择最佳方式纠正失败。我们同时提出三种多样性度量指标,用于评估反事实序列的多样性。我们在两个离散动作和连续动作的强化学习环境中评估ACTER,证明其能生成可操作且多样化的反事实序列。通过用户研究,我们进一步探究ACTER生成的解释如何帮助用户识别并纠正失败。