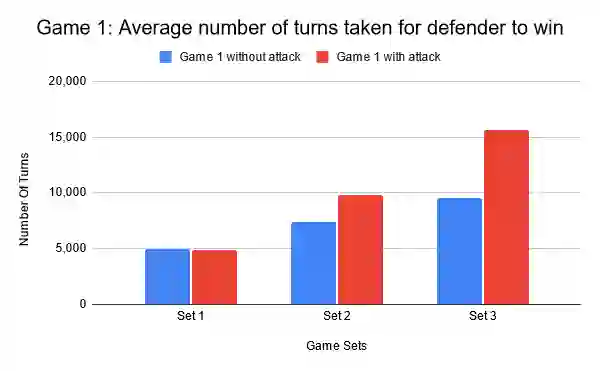
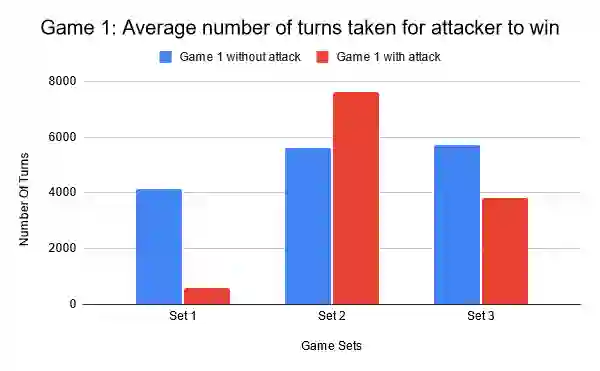
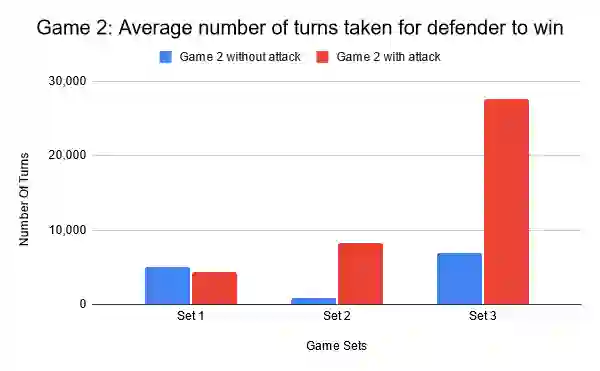
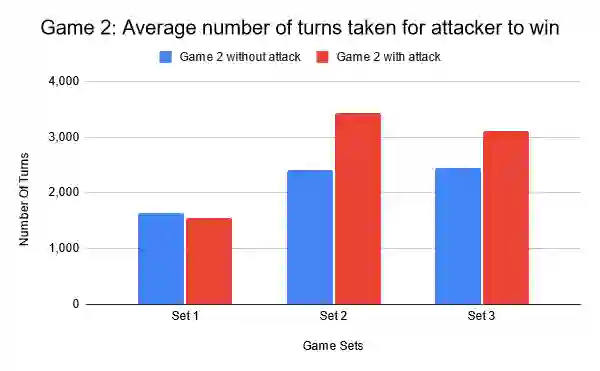
This paper focuses on the impact of leveraging autonomous offensive approaches in Deep Reinforcement Learning (DRL) to train more robust agents by exploring the impact of applying adversarial learning to DRL for autonomous security in Software Defined Networks (SDN). Two algorithms, Double Deep Q-Networks (DDQN) and Neural Episodic Control to Deep Q-Network (NEC2DQN or N2D), are compared. NEC2DQN was proposed in 2018 and is a new member of the deep q-network (DQN) family of algorithms. The attacker has full observability of the environment and access to a causative attack that uses state manipulation in an attempt to poison the learning process. The implementation of the attack is done under a white-box setting, in which the attacker has access to the defender's model and experiences. Two games are played; in the first game, DDQN is a defender and N2D is an attacker, and in second game, the roles are reversed. The games are played twice; first, without an active causative attack and secondly, with an active causative attack. For execution, three sets of game results are recorded in which a single set consists of 10 game runs. The before and after results are then compared in order to see if there was actually an improvement or degradation. The results show that with minute parameter changes made to the algorithms, there was growth in the attacker's role, since it is able to win games. Implementation of the adversarial learning by the introduction of the causative attack showed the algorithms are still able to defend the network according to their strengths.
翻译:本文聚焦于利用自主攻击方法在深度强化学习(DRL)中训练更鲁棒智能体的影响,通过探究在软件定义网络(SDN)自主安全场景下将对抗学习应用于DRL的效果。比较了两种算法:双深度Q网络(DDQN)和神经情景控制深度Q网络(NEC2DQN或N2D)。NEC2DQN于2018年提出,是深度Q网络(DQN)算法家族的新成员。攻击者对环境具有完全可观测性,并可实施因果攻击——通过状态操纵试图毒化学习过程。该攻击在白盒环境下实现,此时攻击者可访问防御者的模型与经验。游戏分两轮进行:首轮DDQN担任防守方、N2D担任攻击方,次轮角色互换。每轮游戏执行两次:首次无主动因果攻击,第二次包含主动因果攻击。实验记录三组游戏结果,每组包含10次游戏运行。通过对比前后结果判定性能是否改善或退化。结果表明,尽管算法参数仅作微小调整,攻击方角色仍因获胜能力提升而增强。引入因果攻击的对抗学习实践显示,算法仍能根据自身优势有效维护网络安全。