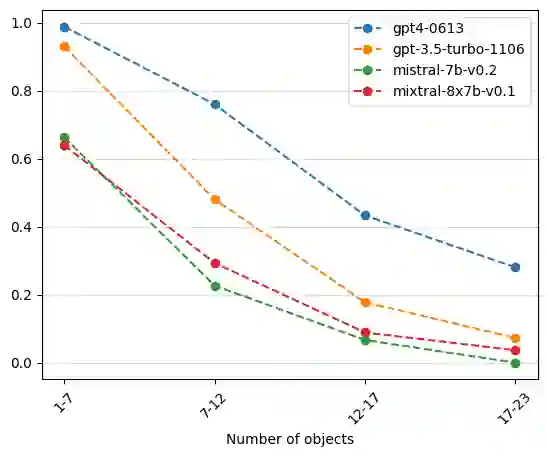
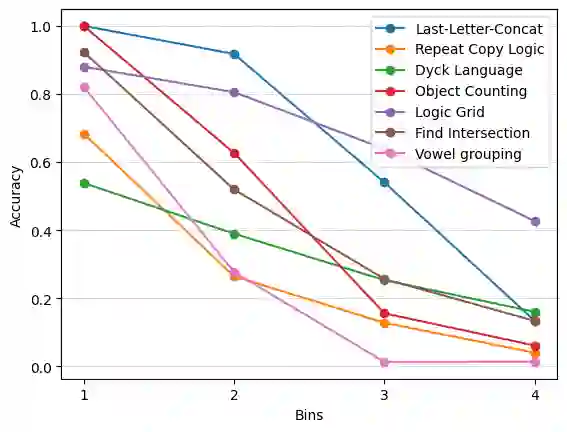
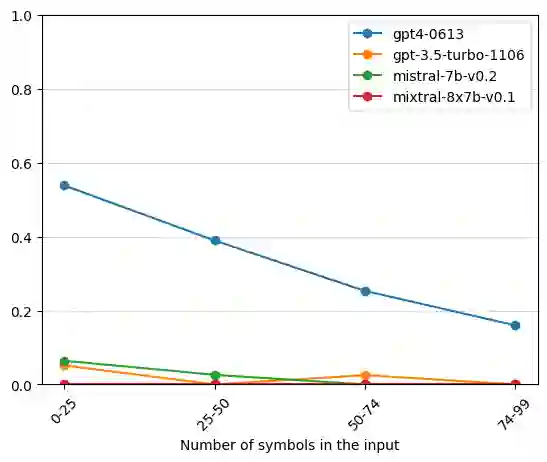
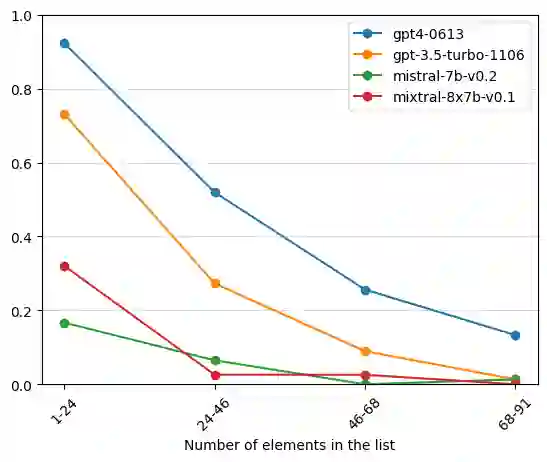
Language models are now capable of solving tasks that require dealing with long sequences consisting of hundreds of thousands of tokens. However, they often fail on tasks that require repetitive use of simple rules, even on sequences that are much shorter than those seen during training. For example, state-of-the-art LLMs can find common items in two lists with up to 20 items but fail when lists have 80 items. In this paper, we introduce Lissard, a benchmark comprising seven tasks whose goal is to assess the ability of models to process and generate wide-range sequence lengths, requiring repetitive procedural execution. Our evaluation of open-source (Mistral-7B and Mixtral-8x7B) and proprietary models (GPT-3.5 and GPT-4) show a consistent decline in performance across all models as the complexity of the sequence increases. The datasets and code are available at https://github.com/unicamp-dl/Lissard
翻译:语言模型现已能处理包含数十万token的长序列任务。然而,在面对需要重复运用简单规则的任务时,即便序列长度远短于训练集,模型仍会频繁出错。例如,最先进的LLM可在20个项目的列表中找出共同项,但当列表包含80个项目时便会失败。本文提出Lissard基准测试,包含七个旨在评估模型处理与生成宽范围序列长度所需重复程序执行能力的任务。我们对开源模型(Mistral-7B与Mixtral-8x7B)及专有模型(GPT-3.5与GPT-4)的评估显示,随着序列复杂度提升,所有模型的性能均呈现一致衰减。数据集与代码见https://github.com/unicamp-dl/Lissard