
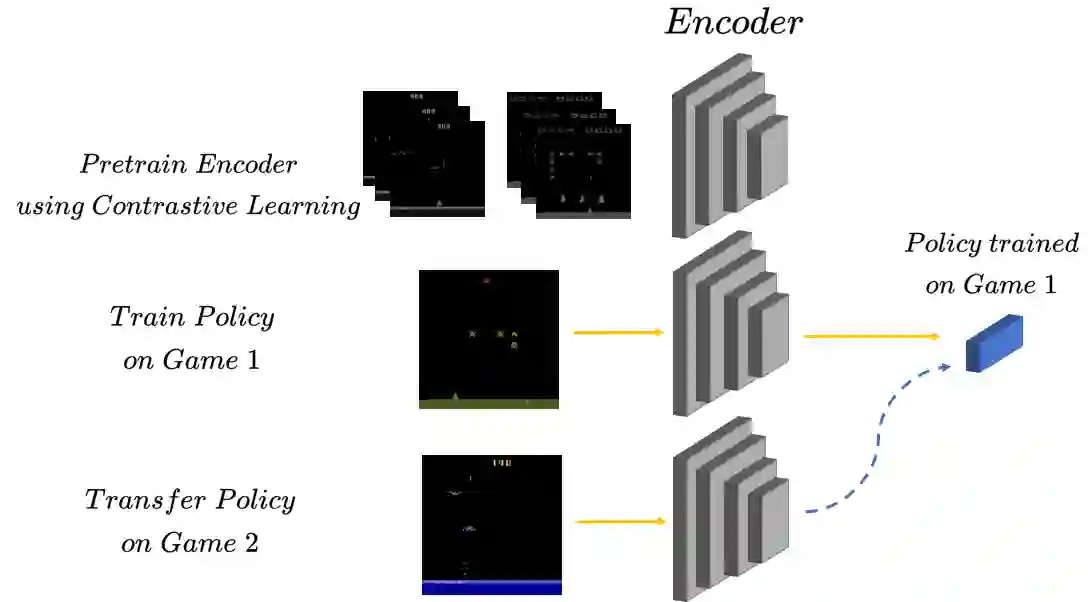
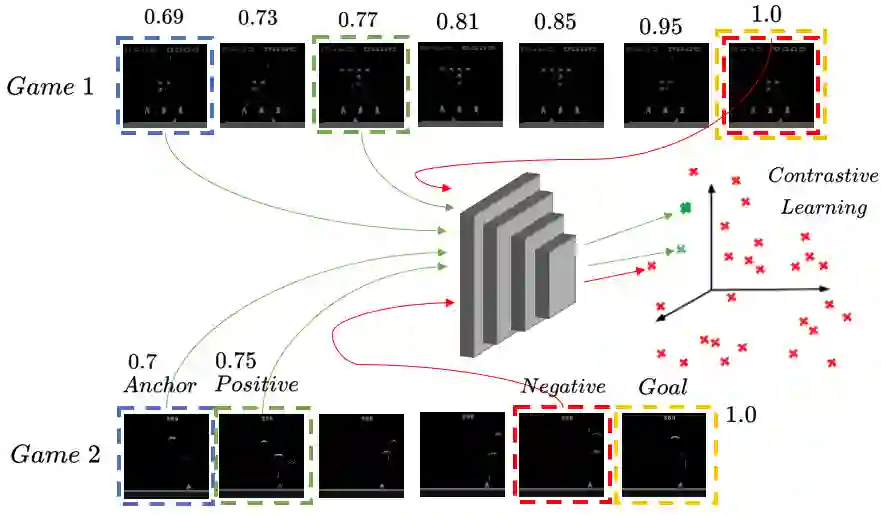
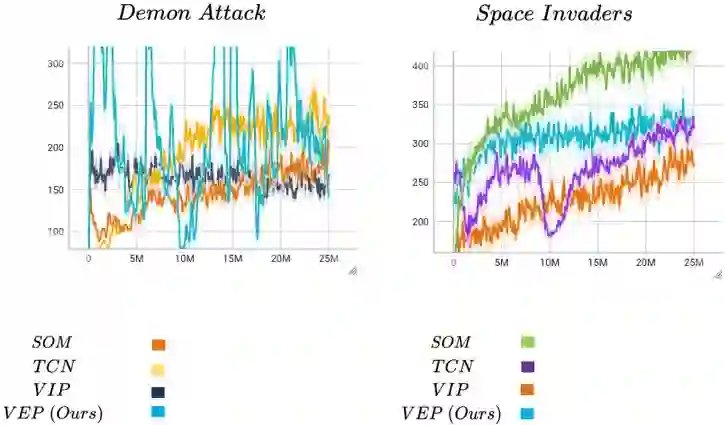
We propose a method that allows for learning task-agnostic representations based on value function estimates from a sequence of observations where the last frame corresponds to a goal. These representations would learn to relate states across different tasks, based on the temporal distance to the goal state, irrespective of the appearance changes and dynamics. This method could be used to transfer learnt policies/skills to unseen related tasks.
翻译:我们提出了一种方法,该方法能够基于从观测序列(其中最后一帧对应目标)中估计的价值函数,学习与任务无关的表征。这些表征能够根据状态与目标状态之间的时间距离,在不同任务间建立状态关联,而无需考虑外貌变化与动力学特性。该方法可用于将已习得的策略/技能迁移至未见过的相关任务。
相关内容
专知会员服务
35+阅读 · 2019年10月18日
专知会员服务
37+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2024年1月31日



最新内容
相关VIP内容
专知会员服务
35+阅读 · 2019年10月18日
专知会员服务
37+阅读 · 2019年10月17日
相关资讯
相关论文
Arxiv
0+阅读 · 2024年1月31日