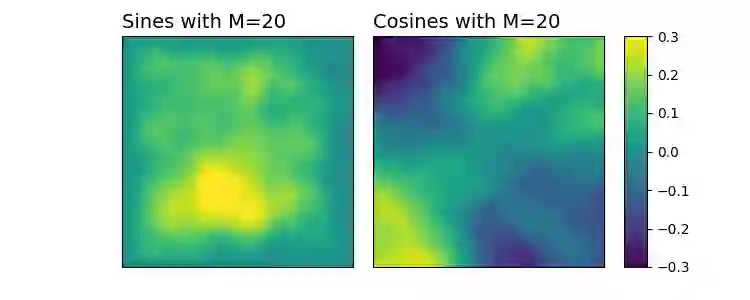
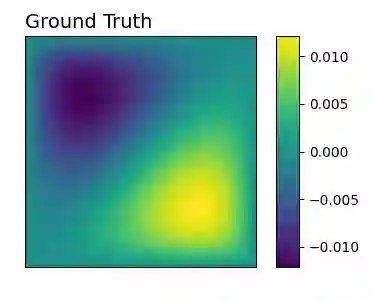
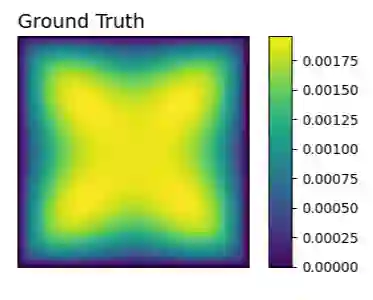
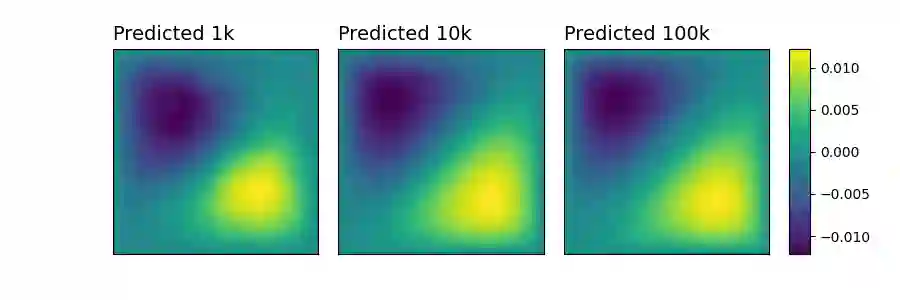
Numerous developments in the recent literature show the promising potential of deep learning in obtaining numerical solutions to partial differential equations (PDEs) beyond the reach of current numerical solvers. However, data-driven neural operators all suffer from the same problem: the data needed to train a network depends on classical numerical solvers such as finite difference or finite element, among others. In this paper, we propose a new approach to generating synthetic functional training data that does not require solving a PDE numerically. The way we do this is simple: we draw a large number $N$ of independent and identically distributed `random functions' $u_j$ from the underlying solution space (e.g., $H_0^1(\Omega)$) in which we know the solution lies according to classical theory. We then plug each such random candidate solution into the equation and get a corresponding right-hand side function $f_j$ for the equation, and consider $(f_j, u_j)_{j=1}^N$ as supervised training data for learning the underlying inverse problem $f \rightarrow u$. This `backwards' approach to generating training data only requires derivative computations, in contrast to standard `forward' approaches, which require a numerical PDE solver, enabling us to generate a large number of such data points quickly and efficiently. While the idea is simple, we hope that this method will expand the potential for developing neural PDE solvers that do not depend on classical numerical solvers.
翻译:近期文献中的诸多进展表明,深度学习在获取超越当前数值求解器能力的偏微分方程数值解方面具有巨大潜力。然而,数据驱动的神经算子均面临相同问题:训练网络所需的数据依赖于经典数值求解器(如有限差分法或有限元法等)。本文提出一种无需数值求解偏微分方程即可生成合成函数训练数据的新方法。其实现方式简单:根据经典理论可知解属于特定解空间(如H_0^1(Ω)),我们从此空间中抽取大量独立同分布的"随机函数"u_j,随后将每个随机候选解代入方程中获取对应的右端项函数f_j,并将(f_j, u_j)_{j=1}^N作为监督训练数据用于学习f→u的逆问题。这种"反向"生成训练数据的方法仅需导数计算,而标准"正向"方法需要数值PDE求解器,因此我们能够快速高效地生成大量此类数据点。尽管思路简单,我们期待该方法能拓展不依赖经典数值求解器的神经PDE求解器的发展潜力。