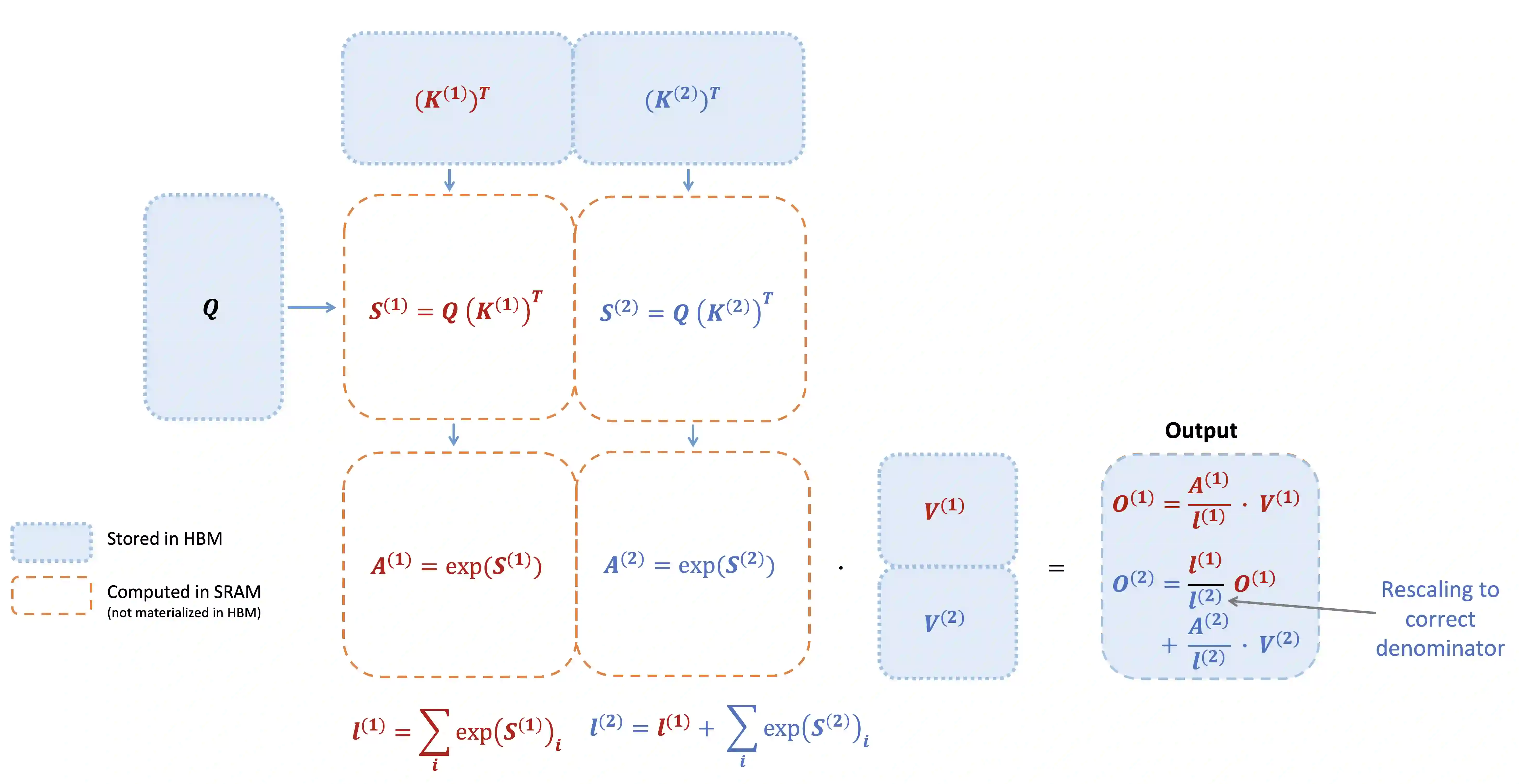
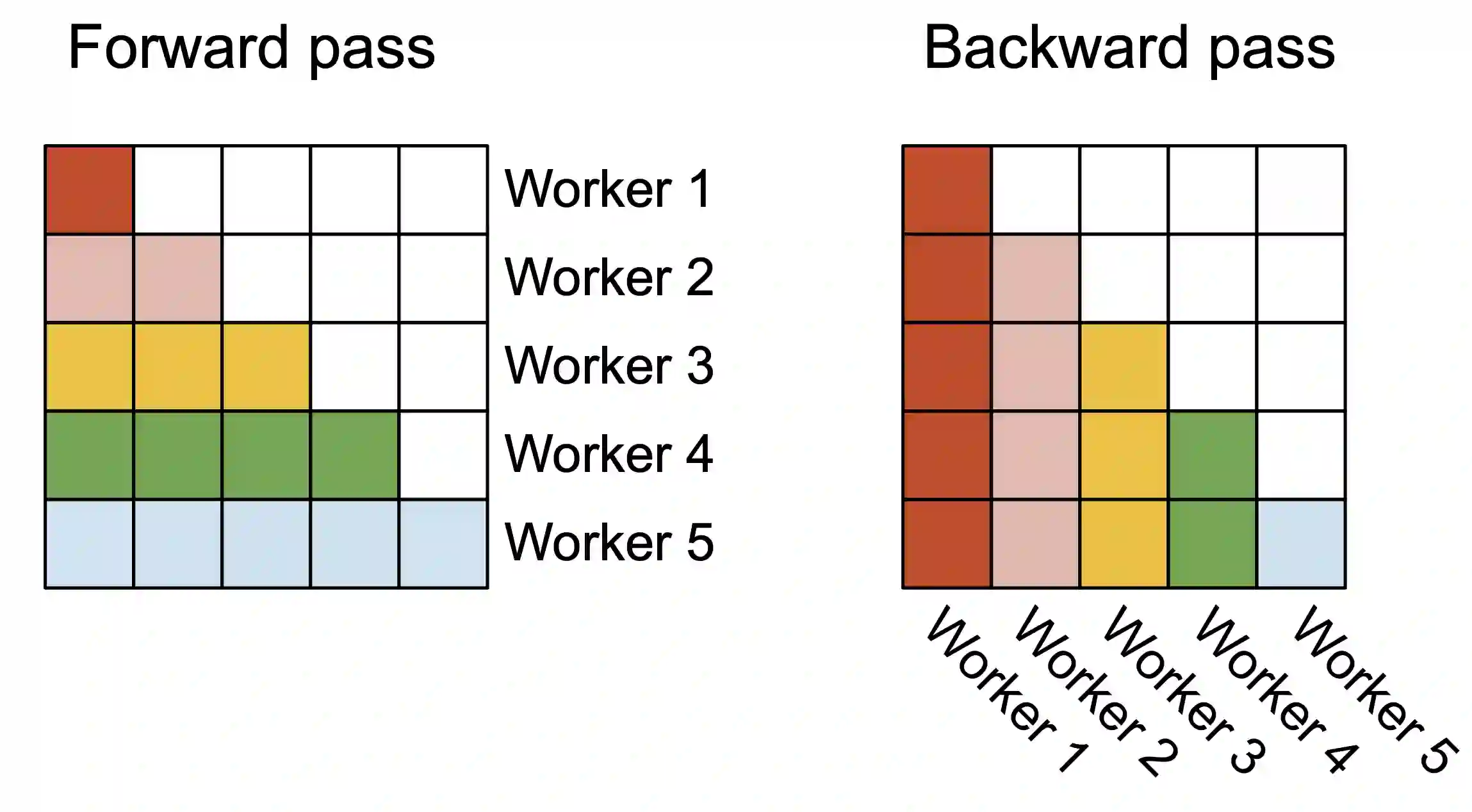
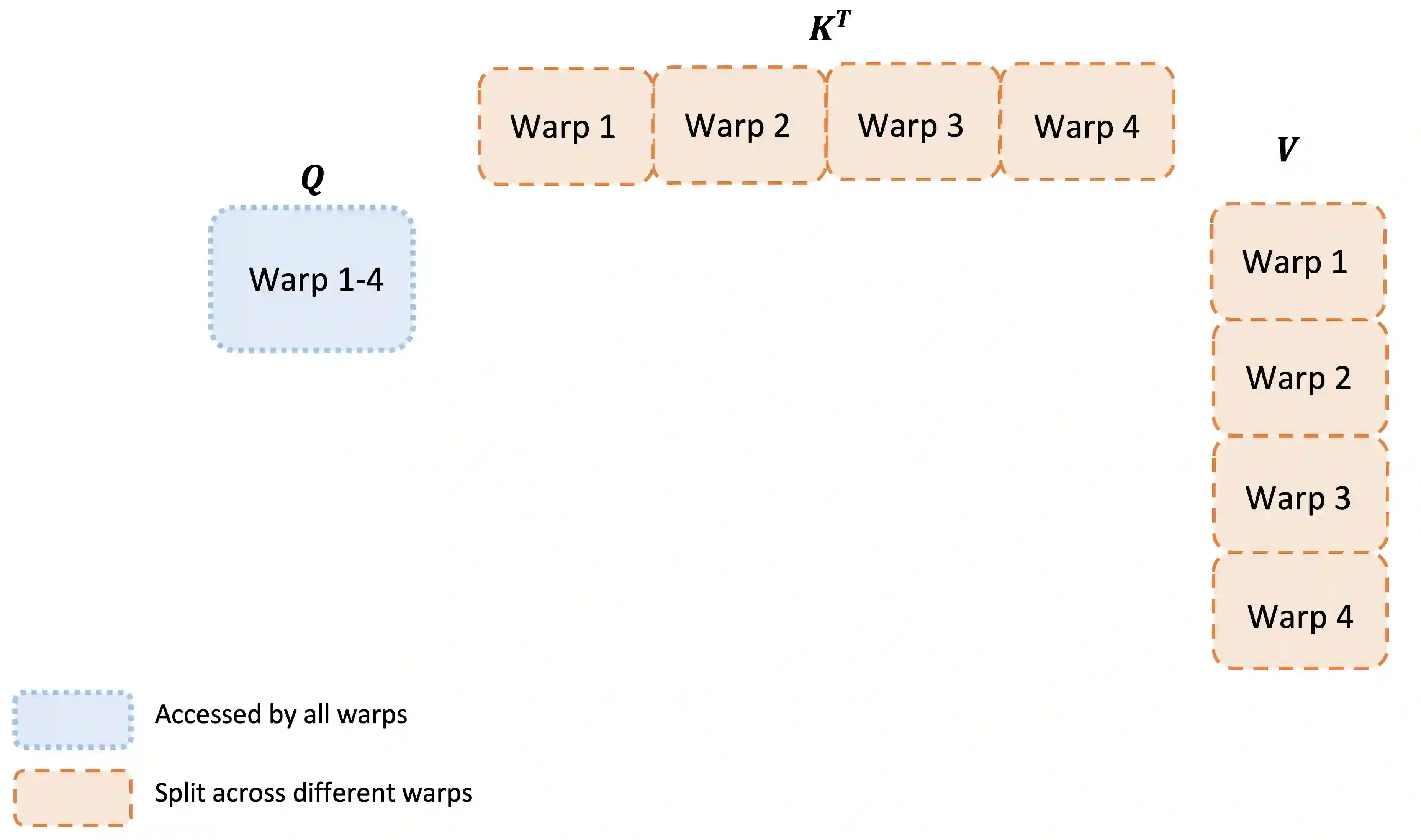
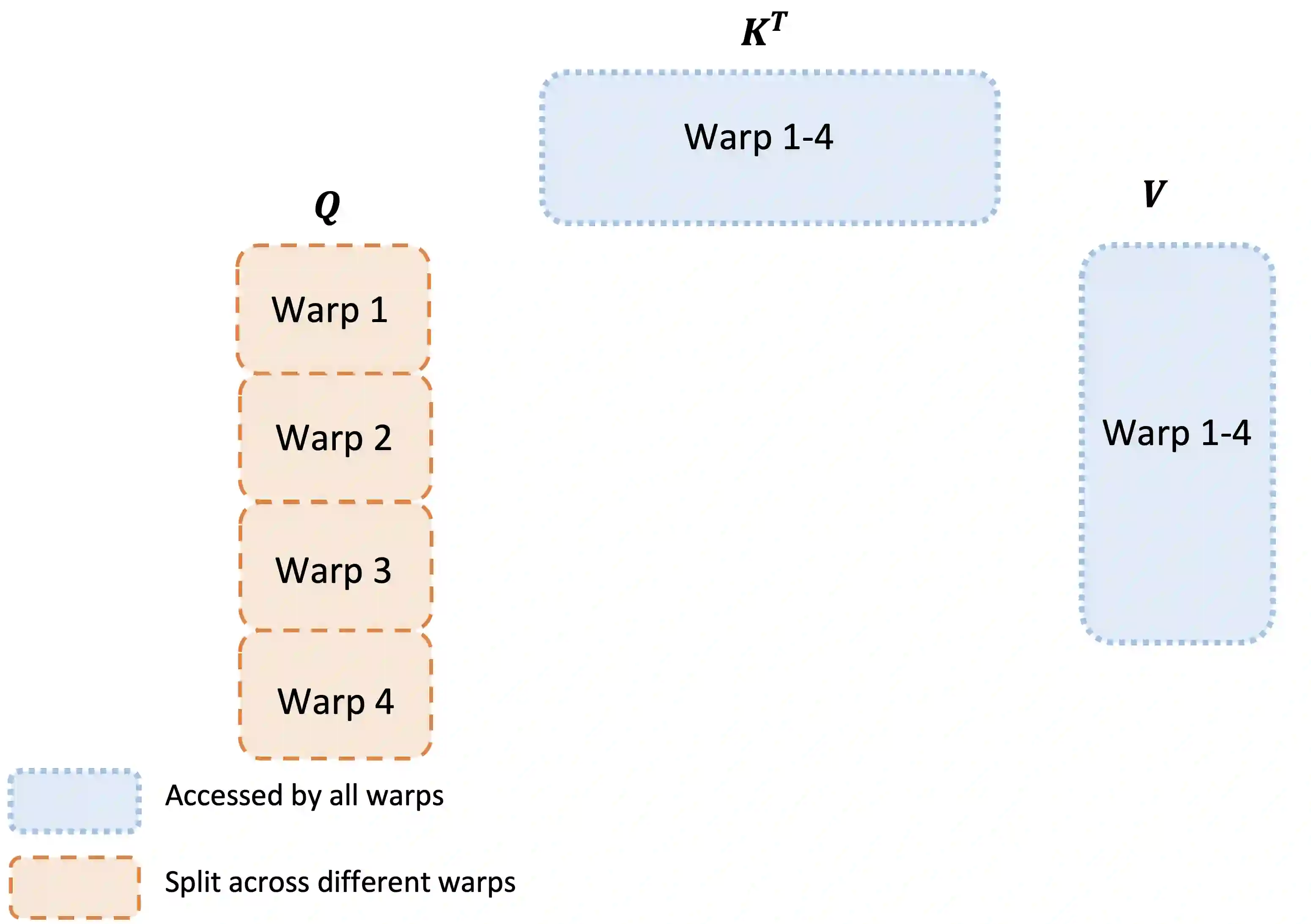
Scaling Transformers to longer sequence lengths has been a major problem in the last several years, promising to improve performance in language modeling and high-resolution image understanding, as well as to unlock new applications in code, audio, and video generation. The attention layer is the main bottleneck in scaling to longer sequences, as its runtime and memory increase quadratically in the sequence length. FlashAttention exploits the asymmetric GPU memory hierarchy to bring significant memory saving (linear instead of quadratic) and runtime speedup (2-4$\times$ compared to optimized baselines), with no approximation. However, FlashAttention is still not nearly as fast as optimized matrix-multiply (GEMM) operations, reaching only 25-40\% of the theoretical maximum FLOPs/s. We observe that the inefficiency is due to suboptimal work partitioning between different thread blocks and warps on the GPU, causing either low-occupancy or unnecessary shared memory reads/writes. We propose FlashAttention-2, with better work partitioning to address these issues. In particular, we (1) tweak the algorithm to reduce the number of non-matmul FLOPs (2) parallelize the attention computation, even for a single head, across different thread blocks to increase occupancy, and (3) within each thread block, distribute the work between warps to reduce communication through shared memory. These yield around 2$\times$ speedup compared to FlashAttention, reaching 50-73\% of the theoretical maximum FLOPs/s on A100 and getting close to the efficiency of GEMM operations. We empirically validate that when used end-to-end to train GPT-style models, FlashAttention-2 reaches training speed of up to 225 TFLOPs/s per A100 GPU (72\% model FLOPs utilization).
翻译:将Transformer扩展至更长序列长度是近年来的一大难题,有望提升语言建模和高分辨率图像理解的性能,同时解锁代码、音频和视频生成领域的新应用。注意力层是扩展至长序列的主要瓶颈,其运行时间和内存占用随序列长度呈二次增长。FlashAttention利用GPU非对称内存层次结构实现了显著的内存节省(线性而非二次)和运行加速(相比优化基线提升2-4倍),且无需近似处理。然而,FlashAttention的速度仍未接近优化的矩阵乘法(GEMM)操作,仅达到理论最大FLOPs/s的25-40%。我们发现低效的原因在于GPU上不同线程块与线程束间的工作划分次优,导致占用率不足或不必要的共享内存读写。为此,我们提出具有更优工作划分的FlashAttention-2以解决上述问题。具体而言,我们:(1)调整算法以减少非矩阵乘法FLOPs数量;(2)将注意力计算(甚至单头计算)并行化至不同线程块以提高占用率;(3)在每个线程块内,在线程束间分配工作以减少共享内存通信。这些改进相比FlashAttention实现约2倍加速,在A100上达到理论最大FLOPs/s的50-73%,接近GEMM操作的效率。实验验证表明,当端到端用于训练GPT风格模型时,FlashAttention-2在每块A100 GPU上可实现高达225 TFLOPs/s的训练速度(模型FLOPs利用率达72%)。