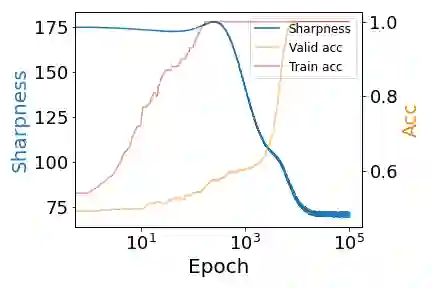
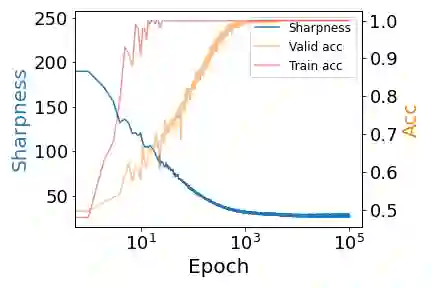
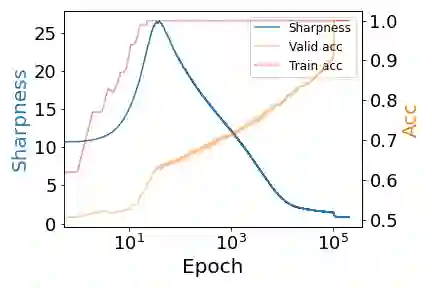
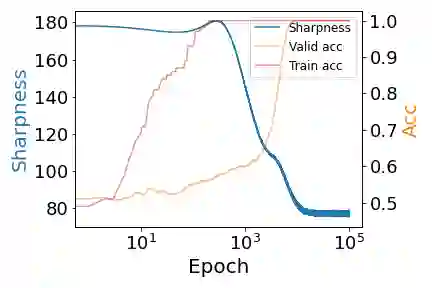
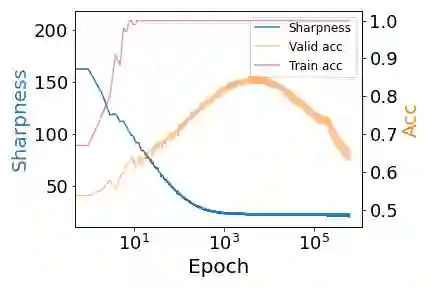
Despite extensive studies, the underlying reason as to why overparameterized neural networks can generalize remains elusive. Existing theory shows that common stochastic optimizers prefer flatter minimizers of the training loss, and thus a natural potential explanation is that flatness implies generalization. This work critically examines this explanation. Through theoretical and empirical investigation, we identify the following three scenarios for two-layer ReLU networks: (1) flatness provably implies generalization; (2) there exist non-generalizing flattest models and sharpness minimization algorithms fail to generalize, and (3) perhaps most surprisingly, there exist non-generalizing flattest models, but sharpness minimization algorithms still generalize. Our results suggest that the relationship between sharpness and generalization subtly depends on the data distributions and the model architectures and sharpness minimization algorithms do not only minimize sharpness to achieve better generalization. This calls for the search for other explanations for the generalization of over-parameterized neural networks.
翻译:尽管已有大量研究,但过参数化神经网络为何能够泛化的根本原因仍不明确。现有理论表明,常见的随机优化器倾向于选择训练损失更平坦的极小值点,因此一种自然的潜在解释是:平坦性意味着泛化能力。本文批判性地审视了这一解释。通过理论与实证研究,我们针对双层ReLU网络发现了以下三种情形:(1)平坦性可证明地隐含泛化能力;(2)存在非泛化的最平坦模型,且锐度最小化算法无法泛化;(3)最令人惊讶的是,存在非泛化的最平坦模型,但锐度最小化算法仍能泛化。我们的结果表明,锐度与泛化之间的关系微妙地依赖于数据分布与模型架构,且锐度最小化算法并非仅通过最小化锐度来实现更好的泛化。这呼吁我们寻找关于过参数化神经网络泛化能力的其他解释。