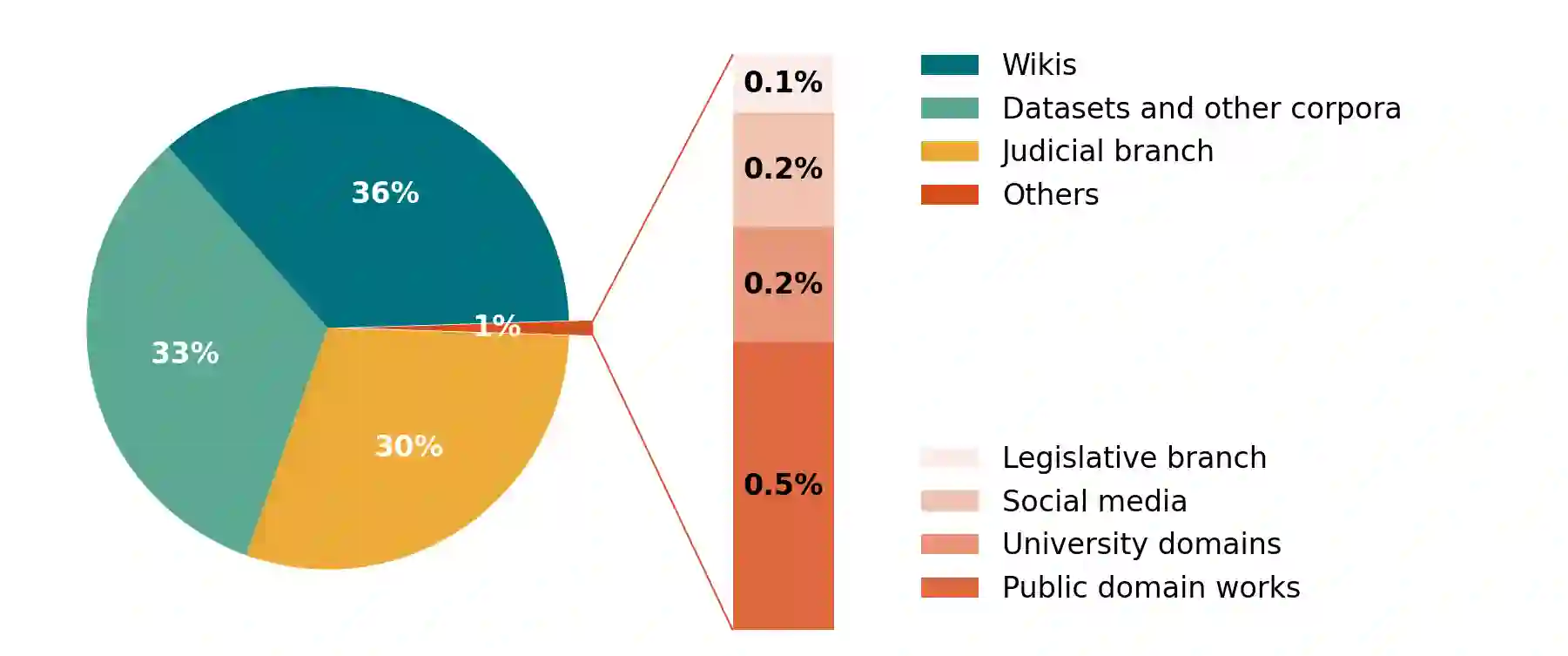
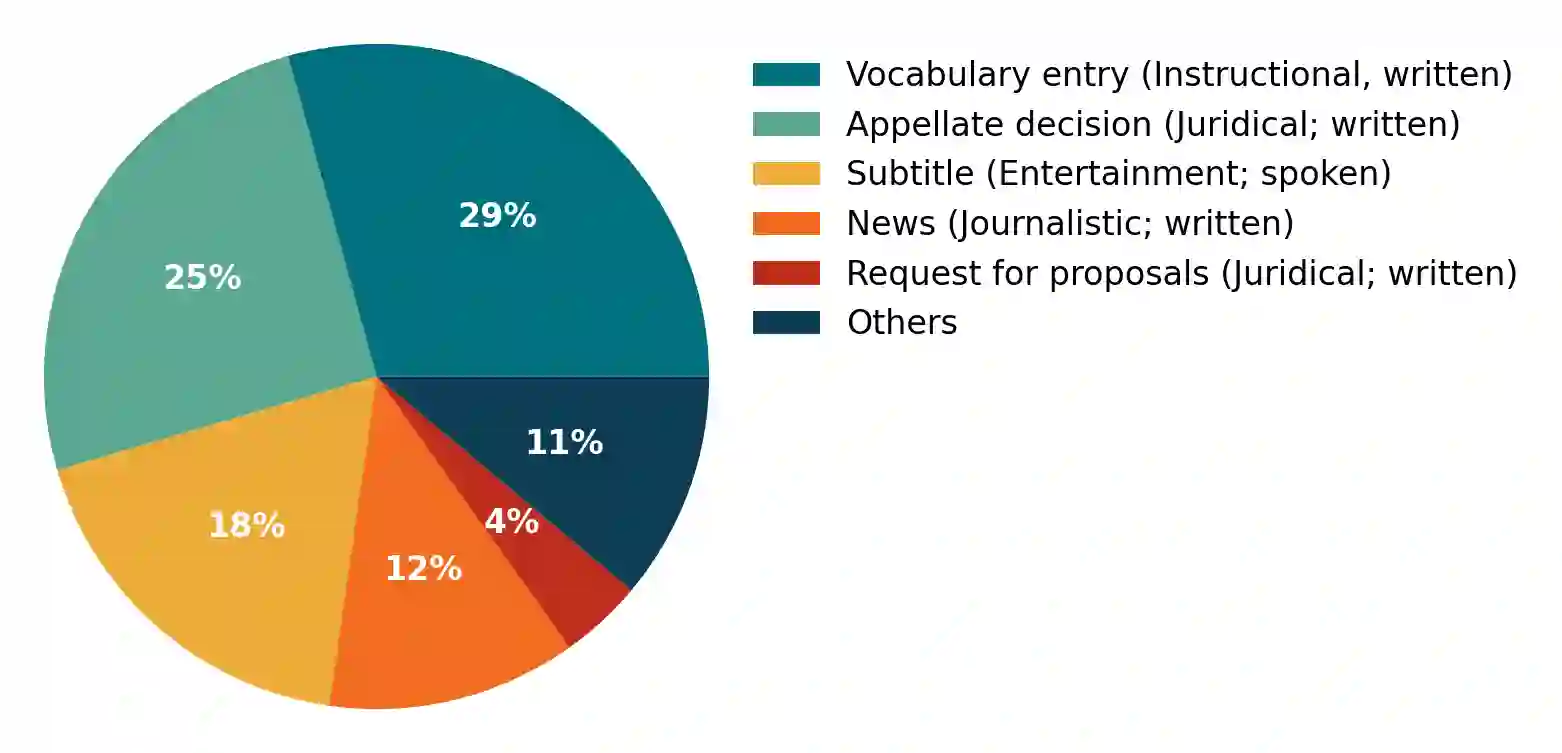
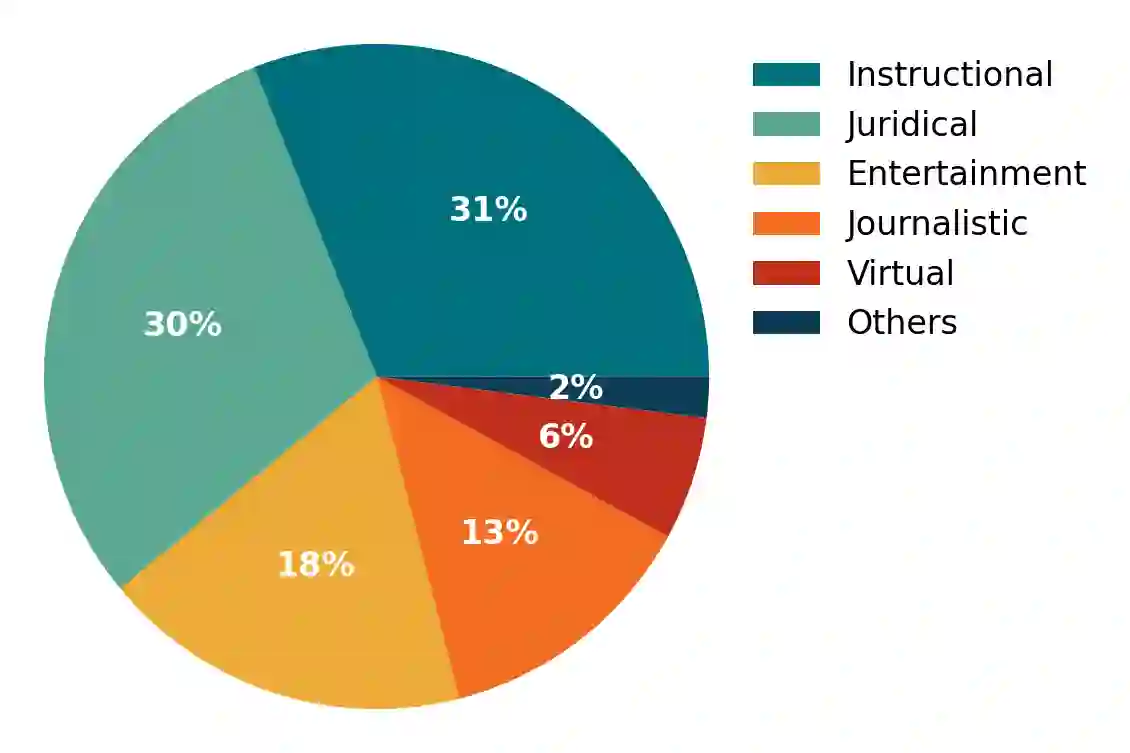
This paper presents the first publicly available version of the Carolina Corpus and discusses its future directions. Carolina is a large open corpus of Brazilian Portuguese texts under construction using web-as-corpus methodology enhanced with provenance, typology, versioning, and text integrality. The corpus aims at being used both as a reliable source for research in Linguistics and as an important resource for Computer Science research on language models, contributing towards removing Portuguese from the set of low-resource languages. Here we present the construction of the corpus methodology, comparing it with other existing methodologies, as well as the corpus current state: Carolina's first public version has $653,322,577$ tokens, distributed over $7$ broad types. Each text is annotated with several different metadata categories in its header, which we developed using TEI annotation standards. We also present ongoing derivative works and invite NLP researchers to contribute with their own.
翻译:本文介绍了Carolina语料库的首个公开版本,并探讨其未来发展方向。Carolina是一个正在建设中的大型开放巴西葡萄牙语文本语料库,采用基于网络的语料库构建方法,并增强了来源、类型、版本与文本完整性信息。该语料库旨在同时作为语言学研究的可靠资源与计算机科学语言模型研究的重要数据基础,助力葡萄牙语脱离低资源语言行列。我们在此阐述了语料库的构建方法论,将其与现有其他方法进行对比,同时展示了语料库的当前状态:Carolina首个公开版本包含653,322,577个词元,分布于7大类型。每个文本在其头部标记了多种元数据类别,这些分类基于TEI标注标准开发。我们还介绍了正在进行中的衍生研究项目,并诚邀自然语言处理研究者贡献自身工作。