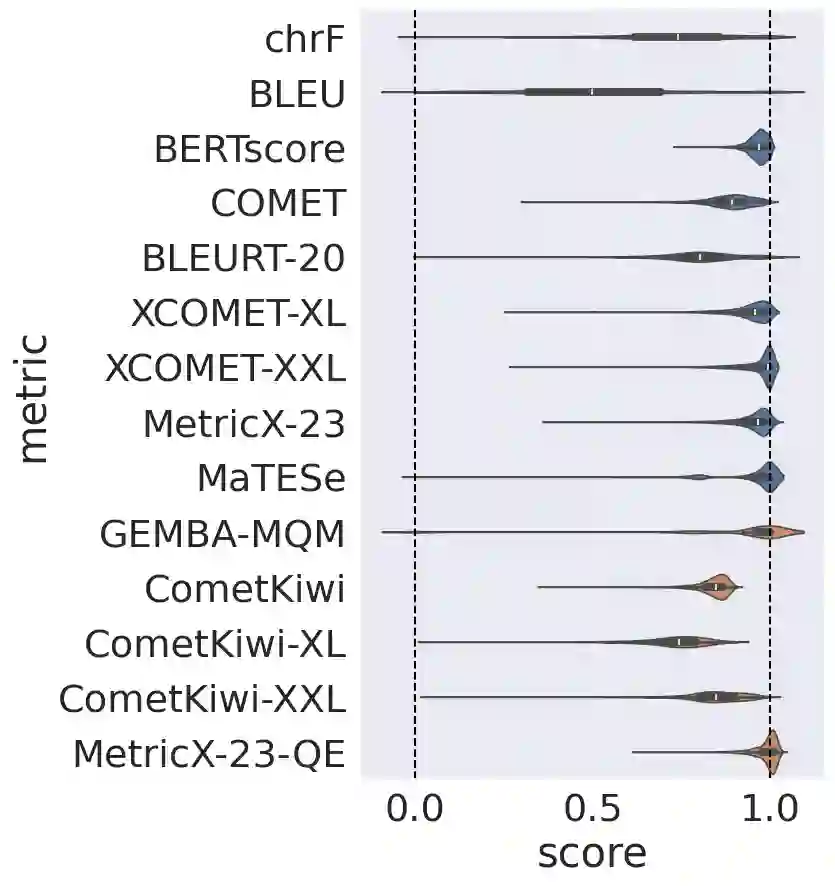
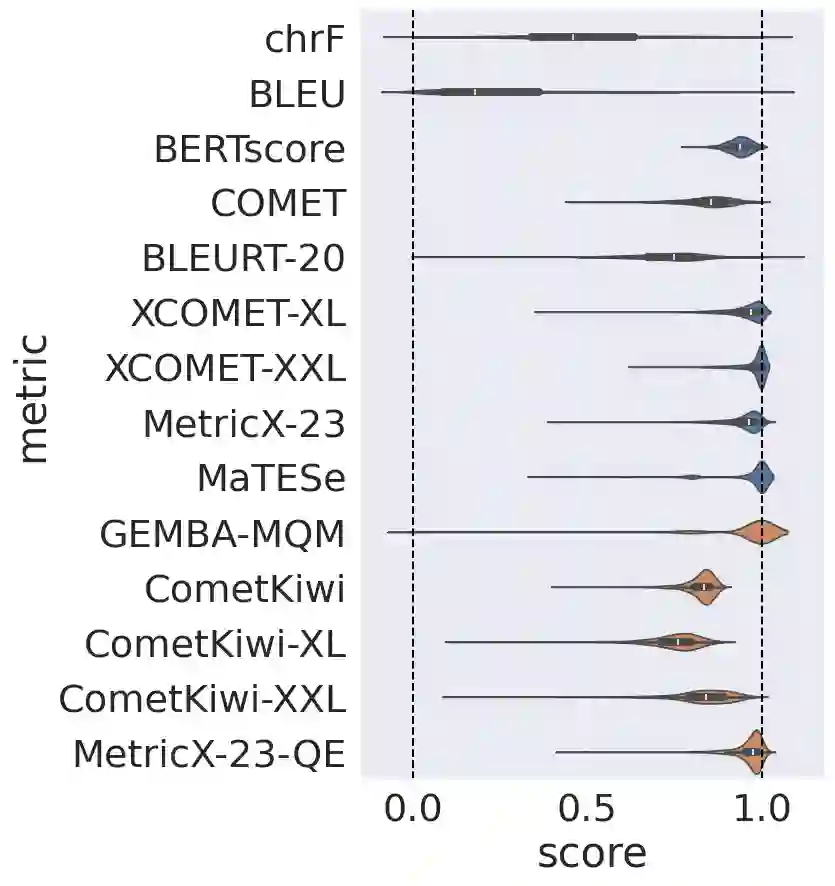
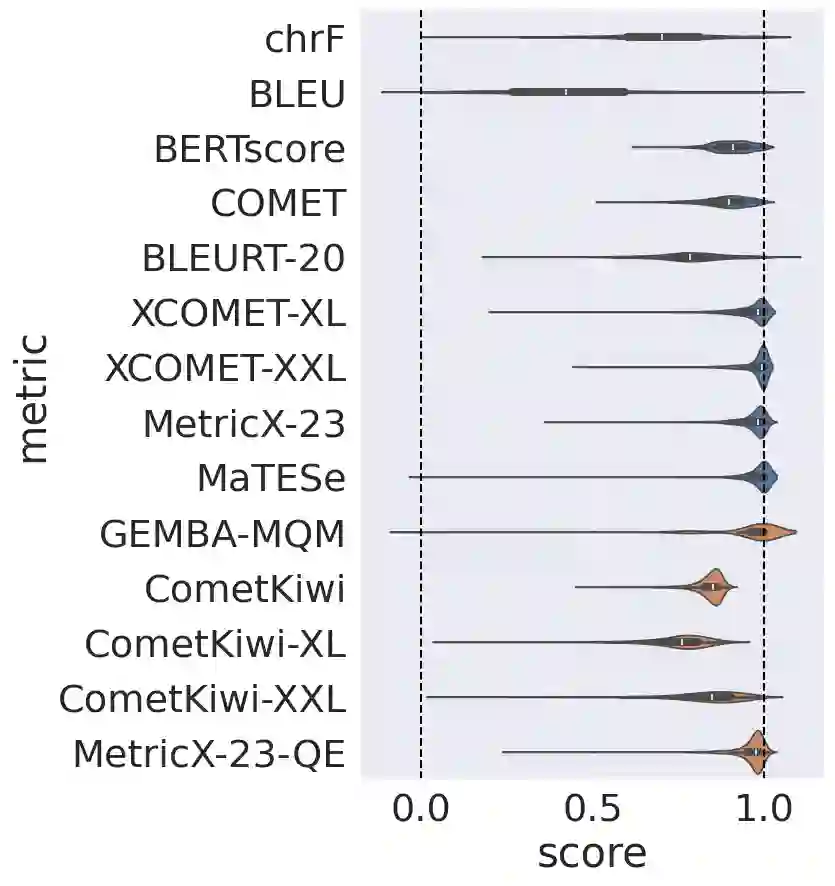
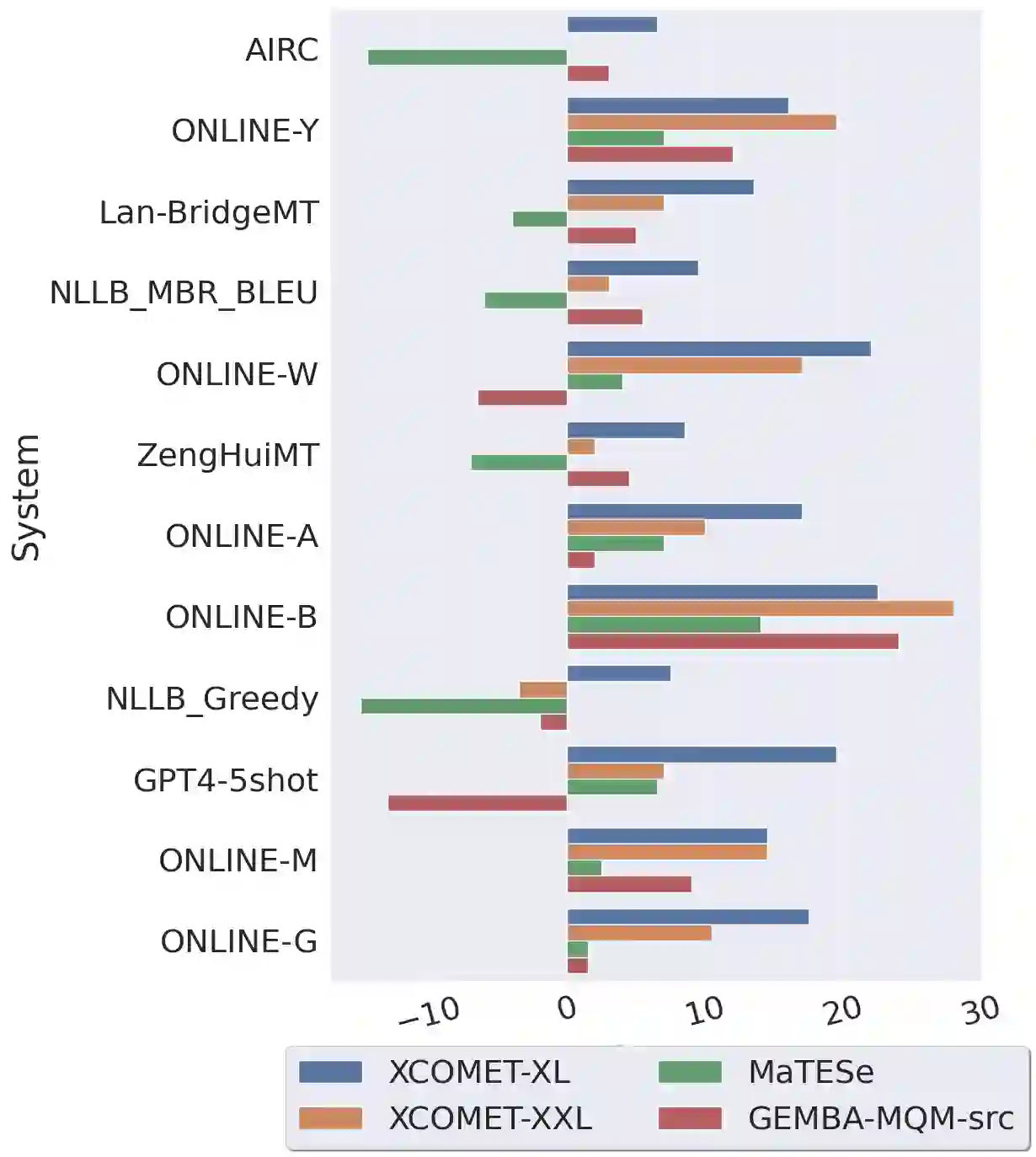
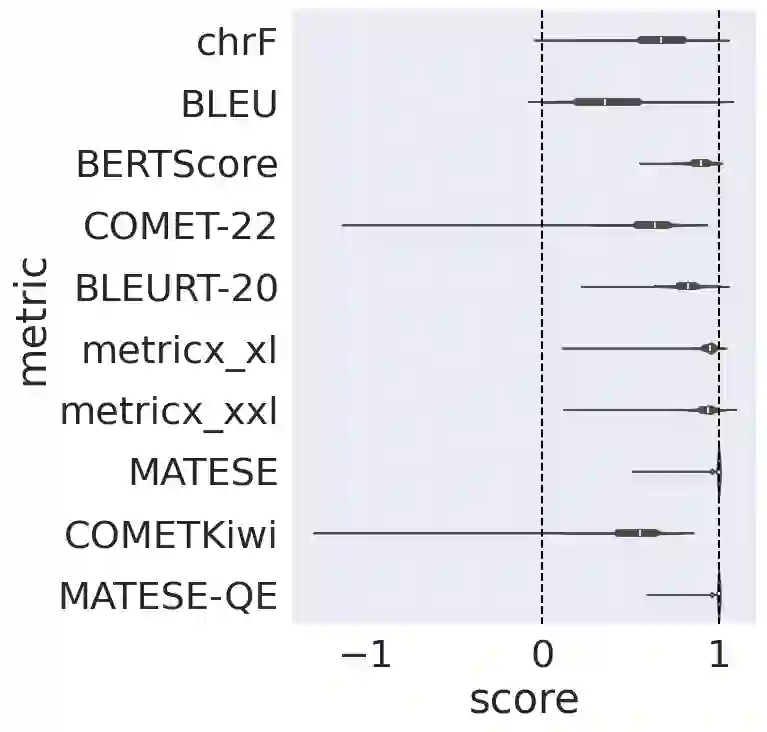
Automatic metrics for evaluating translation quality are typically validated by measuring how well they correlate with human assessments. However, correlation methods tend to capture only the ability of metrics to differentiate between good and bad source-translation pairs, overlooking their reliability in distinguishing alternative translations for the same source. In this paper, we confirm that this is indeed the case by showing that current metrics are insensitive to nuanced differences in translation quality. This effect is most pronounced when the quality is high and the variance among alternatives is low. Given this finding, we shift towards detecting high-quality correct translations, an important problem in practical decision-making scenarios where a binary check of correctness is prioritized over a nuanced evaluation of quality. Using the MQM framework as the gold standard, we systematically stress-test the ability of current metrics to identify translations with no errors as marked by humans. Our findings reveal that current metrics often over or underestimate translation quality, indicating significant room for improvement in automatic evaluation methods.
翻译:翻译质量自动评估指标通常通过衡量其与人工评估的相关性来进行验证。然而,相关性方法往往仅能捕捉指标区分优劣源语-译语对的能力,而忽视了其在区分同一源语不同译文时的可靠性。本文通过证明当前指标对翻译质量的细微差异不敏感,确认了这种情况确实存在。当译文质量较高且不同译文间的差异较小时,这种效应最为明显。基于这一发现,我们将研究重点转向检测高质量的正确译文——这在以正确性二元检查优先于质量细微评估的实际决策场景中是一个重要问题。以MQM框架作为黄金标准,我们系统性地压力测试了当前指标识别人类标注无错误译文的能力。我们的研究结果表明,当前指标经常高估或低估翻译质量,这表明自动评估方法仍有显著的改进空间。