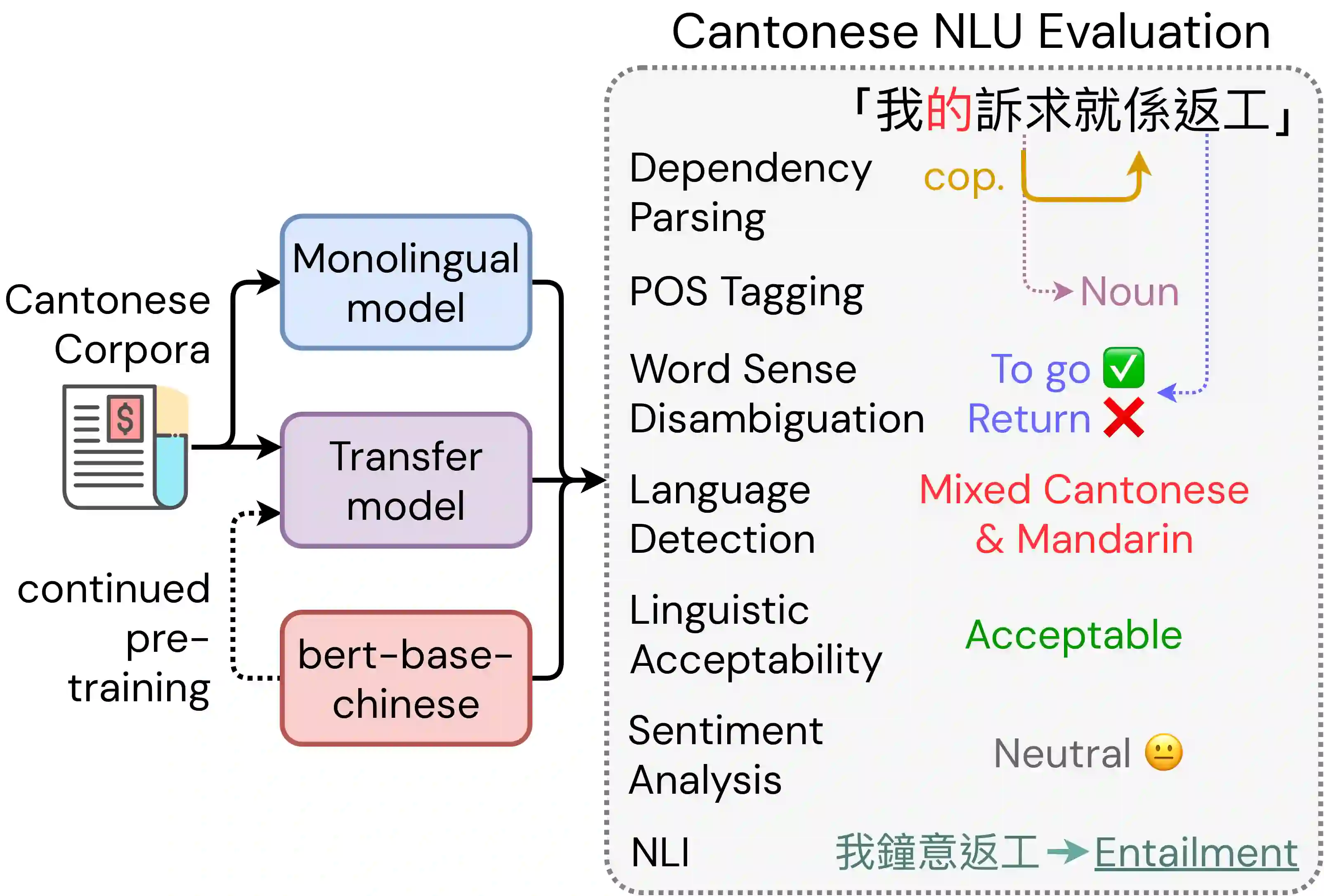
Cantonese, although spoken by millions, remains under-resourced due to policy and diglossia. To address this scarcity of evaluation frameworks for Cantonese, we introduce \textsc{\textbf{CantoNLU}}, a benchmark for Cantonese natural language understanding (NLU). This novel benchmark spans seven tasks covering syntax and semantics, including word sense disambiguation, linguistic acceptability judgment, language detection, natural language inference, sentiment analysis, part-of-speech tagging, and dependency parsing. In addition to the benchmark, we provide model baseline performance across a set of models: a Mandarin model without Cantonese training, two Cantonese-adapted models obtained by continual pre-training a Mandarin model on Cantonese text, and a monolingual Cantonese model trained from scratch. Results show that Cantonese-adapted models perform best overall, while monolingual models perform better on syntactic tasks. Mandarin models remain competitive in certain settings, indicating that direct transfer may be sufficient when Cantonese domain data is scarce. We release all datasets, code, and model weights to facilitate future research in Cantonese NLP.
翻译:粤语虽拥有数百万使用者,但由于政策与双言制的影响,其资源仍相对匮乏。为应对粤语评估框架稀缺的问题,我们引入了\textsc{\textbf{CantoNLU}}——一个面向粤语自然语言理解的基准评测。该新颖的基准涵盖七项句法与语义任务,包括词义消歧、语言可接受性判断、语言检测、自然语言推理、情感分析、词性标注和依存句法分析。除基准外,我们还提供了一系列模型的基线性能:一个未经粤语训练的普通话模型、两个通过在粤语文本上持续预训练普通话模型得到的粤语适应模型,以及一个从头开始训练的单语粤语模型。结果表明,粤语适应模型整体表现最佳,而单语模型在句法任务上表现更好。普通话模型在某些场景下仍具竞争力,表明当粤语领域数据稀缺时,直接迁移可能已足够。我们公开了所有数据集、代码和模型权重,以促进粤语自然语言处理的未来研究。