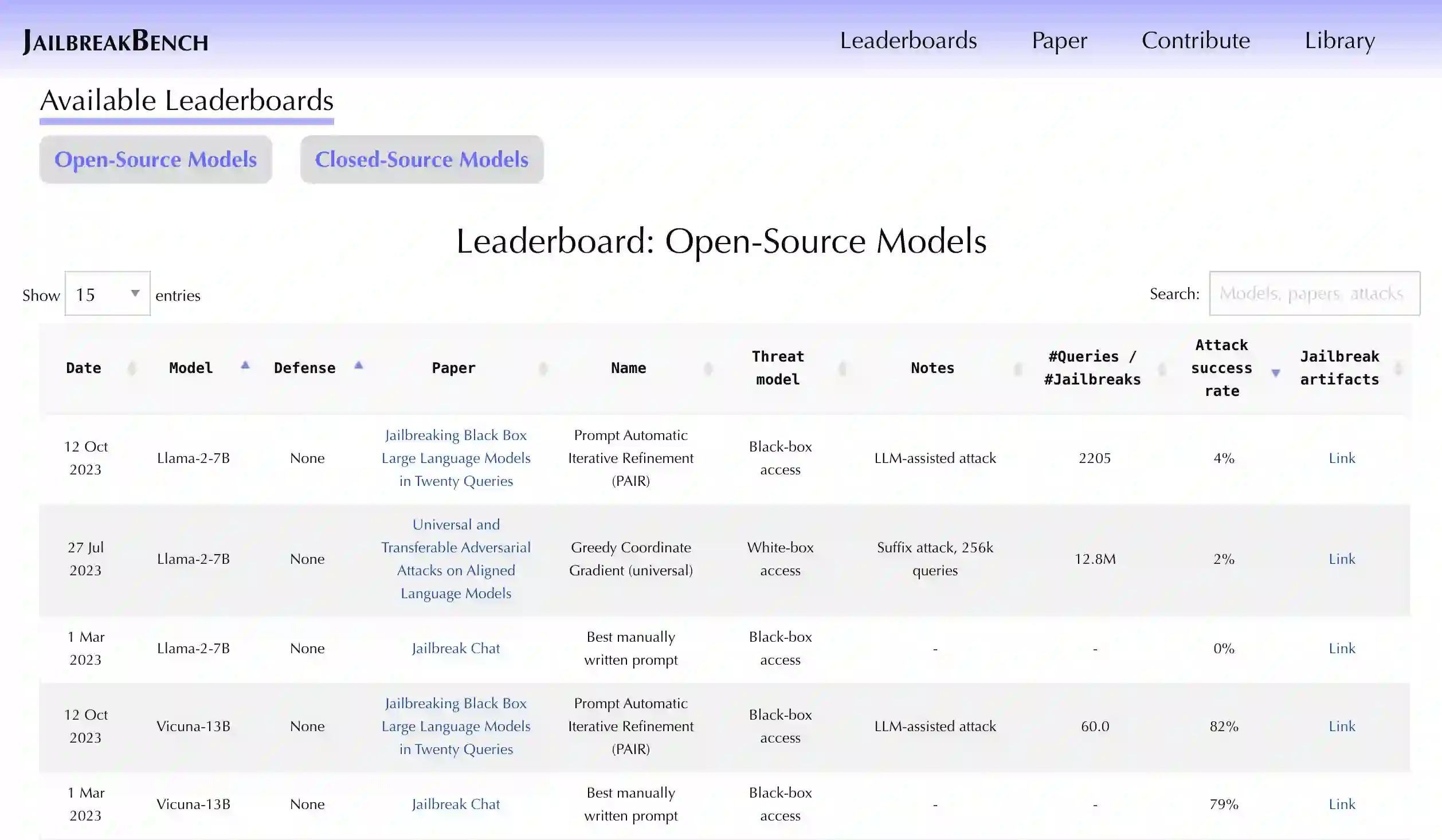
Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (2) a jailbreaking dataset comprising 100 behaviors -- both original and sourced from prior work -- which align with OpenAI's usage policies; (3) a standardized evaluation framework that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community. Over time, we will expand and adapt the benchmark to reflect technical and methodological advances in the research community.
翻译:越狱攻击会导致大语言模型生成有害、不道德或令人反对的内容。评估这些攻击面临诸多挑战,而现有的基准测试与评估技术未能充分解决这些问题。首先,越狱评估缺乏明确的实践标准;其次,现有研究以不可比的方式计算攻击成本与成功率;第三,大量研究因隐藏对抗性提示、依赖闭源代码或依托持续演进的专有应用程序接口而无法复现。为应对这些挑战,我们提出JailbreakBench这一开源基准,其包含以下组件:(1)持续更新的最先进对抗性提示库(称为越狱工程产物);(2)包含100种行为的越狱数据集——涵盖原创行为与源自先前工作的行为——这些行为均符合OpenAI的使用政策;(3)标准化评估框架,包含明确定义的威胁模型、系统提示词、对话模板与评分函数;(4)追踪各类大语言模型攻击与防御性能的排行榜。我们充分考虑了发布该基准的潜在伦理影响,并坚信其将为社区带来净正面效益。随着时间推移,我们将持续扩展并调整该基准,以反映研究领域的技术与方法论进展。