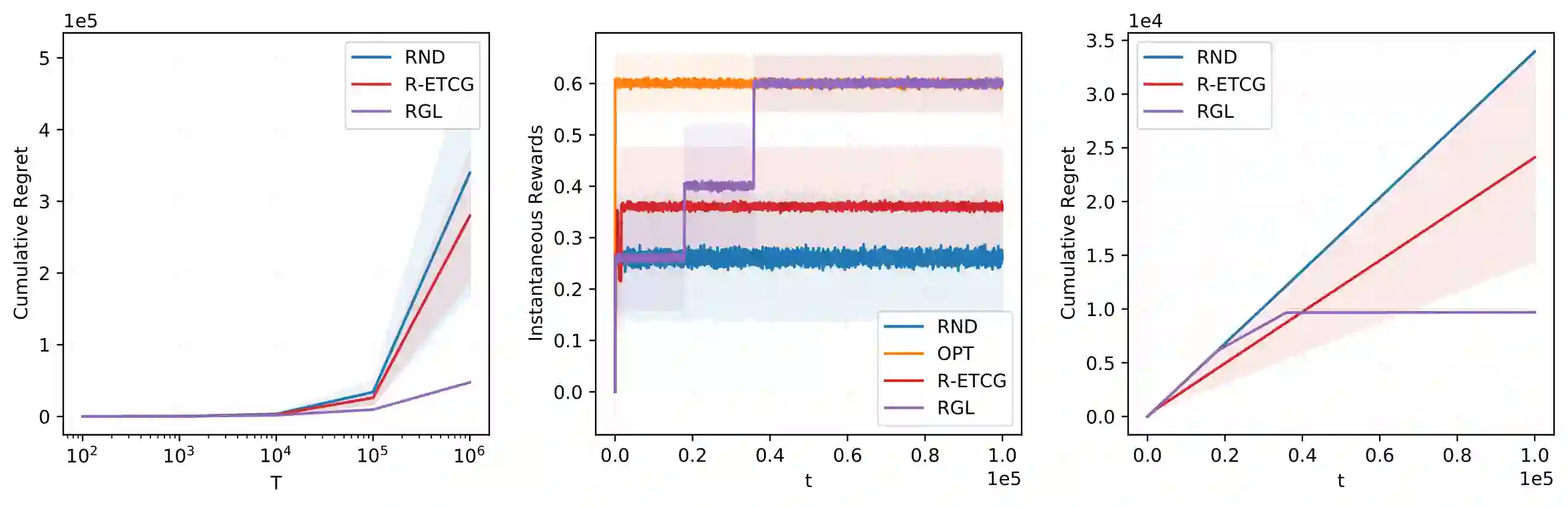
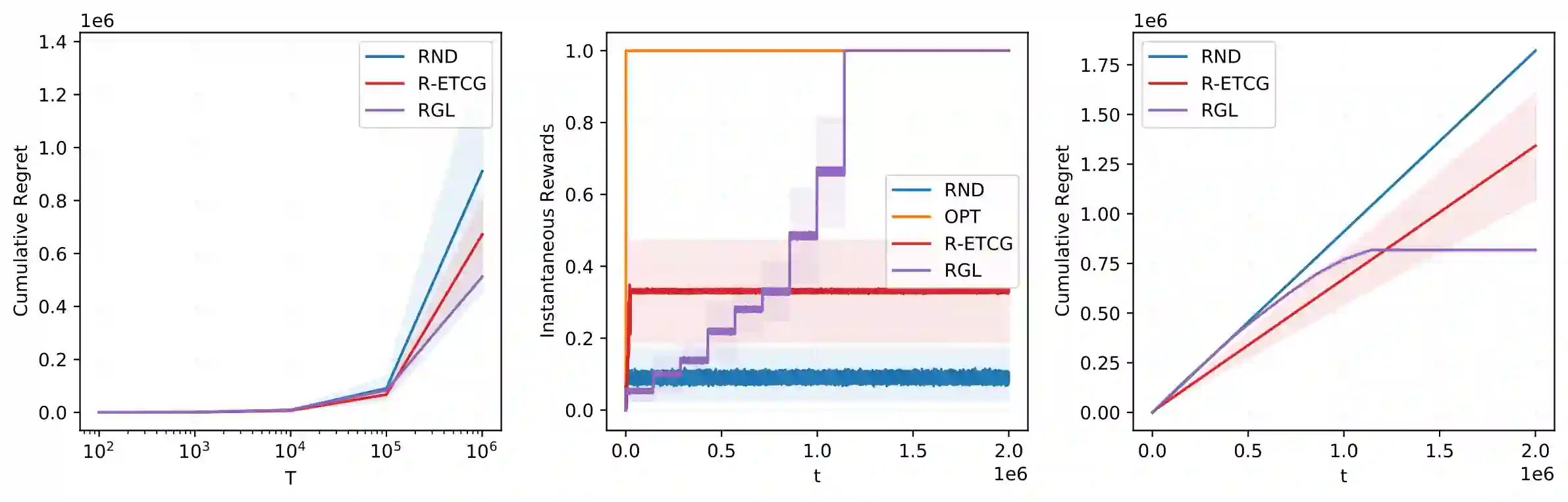
We investigate the problem of unconstrained combinatorial multi-armed bandits with full-bandit feedback and stochastic rewards for submodular maximization. Previous works investigate the same problem assuming a submodular and monotone reward function. In this work, we study a more general problem, i.e., when the reward function is not necessarily monotone, and the submodularity is assumed only in expectation. We propose Randomized Greedy Learning (RGL) algorithm and theoretically prove that it achieves a $\frac{1}{2}$-regret upper bound of $\tilde{\mathcal{O}}(n T^{\frac{2}{3}})$ for horizon $T$ and number of arms $n$. We also show in experiments that RGL empirically outperforms other full-bandit variants in submodular and non-submodular settings.
翻译:我们研究了具有全臂赌博机反馈和随机奖励的无约束组合多臂赌博机问题,旨在实现子模最大化。先前的研究假设奖励函数具有子模性和单调性,并针对同一问题进行了探讨。在本工作中,我们研究了一个更一般的问题,即奖励函数未必单调,且仅期望意义上的子模性。我们提出了随机贪心学习算法,并从理论上证明,在时间范围T和臂数n下,该算法实现了$\frac{1}{2}$的遗憾上界$\tilde{\mathcal{O}}(n T^{\frac{2}{3}})$。实验表明,在子模和非子模设定下,RGL算法在经验上优于其他全臂赌博机变体。