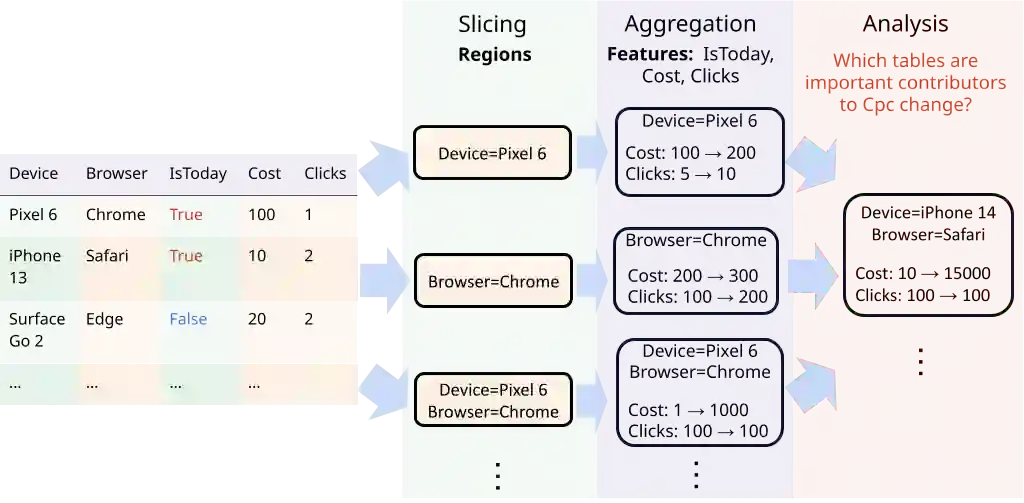
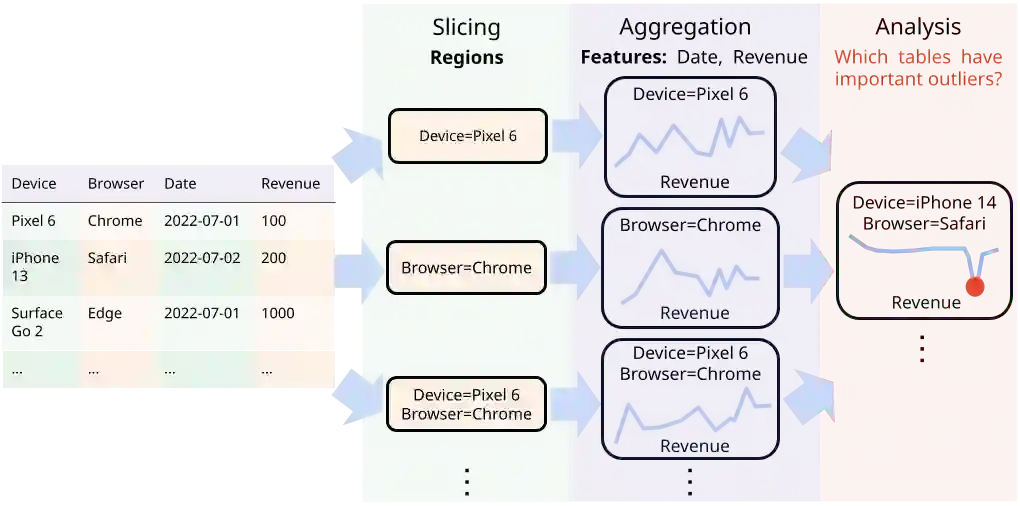
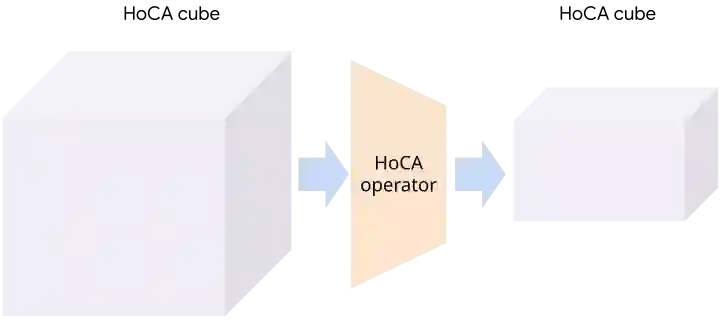
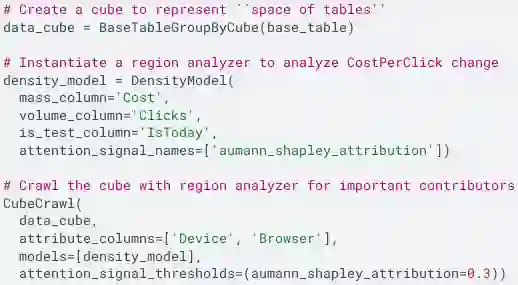
Many data insight questions can be viewed as searching in a large space of tables and finding important ones, where the notion of importance is defined in some adhoc user defined manner. This paper presents Holistic Cube Analysis (HoCA), a framework that augments the capabilities of relational queries for such problems. HoCA first augments the relational data model by defining a new data type AbstractCube, which is defined as a function from RegionFeatures space to relational tables. AbstractCube provides a logical form of data for HoCA programs, abstracting away their exact encoding. With this function-as-data modeling, HoCA operators are thus cube-to-cube transformations. We describe two basic but fundamental HoCA operators, cube crawling and cube join (with many possibilities to extend). Cube crawling explores a region space, and outputs a cube that maps regions to signal vectors. Cube join, in turn, is critical for composition, allowing one to join information from different cubes for deeper analysis. Cube crawling introduces two novel programming features, (programmable) Region Analysis Models (RAMs) and Multi-Model Crawling. Crucially, RAM has a notion of population features, which allows one to go beyond only analyzing local features at a region, and program region-population analysis that compares region and population features, capturing a large class of importance notions in data insights. HoCA poses a rich algorithmic space, and we describe several cube crawling implementations leveraging different foundations, and evaluate their performance. We have implemented and deployed HoCA at Google. Even in this early stage, our HoCA offering has attracted more than 30 teams building data-insight systems with it, with applications in system monitoring, experimentation analysis, and business intelligence, some of which have generated significant revenue uplift.
翻译:许多数据洞察问题可以视为在庞大的表格空间中搜索并找出重要表格,其重要性概念由用户以特定方式定义。本文提出整体多维数据集分析(Holistic Cube Analysis, HoCA),一种增强关系查询能力以解决此类问题的框架。HoCA 首先通过定义新数据类型——抽象多维数据集(AbstractCube)来扩展关系数据模型,该类型被定义为从区域特征空间到关系表的函数。抽象多维数据集为 HoCA 程序提供了数据的逻辑形式,抽象了其具体编码。凭借这种以函数为数据的建模方式,HoCA 运算符实为多维数据集到多维数据集的转换。我们描述了两种基础但核心的 HoCA 运算符:多维数据集爬取(cube crawling)和多维数据集连接(cube join),并指出其扩展可能性。多维数据集爬取探索区域空间,输出将区域映射到信号向量的多维数据集;而多维数据集连接则对组合至关重要,允许从不同多维数据集连接信息以进行更深层次分析。多维数据集爬取引入两种新颖编程特性:(可编程的)区域分析模型(Region Analysis Models, RAMs)与多模型爬取(Multi-Model Crawling)。关键在于,RAM 具备总体特征(population features)概念,使其能够超越仅分析区域局部特征的局限,实现区域与总体特征对比的区域-总体分析(region-population analysis),从而涵盖数据洞察中大量重要性概念。HoCA 提供了丰富的算法空间,我们描述了若干基于不同基础实现的多维数据集爬取方法,并评估其性能。我们已在 Google 内部实现并部署 HoCA。即使在早期阶段,我们的 HoCA 方案已吸引超过 30 个团队用它构建数据洞察系统,应用涵盖系统监控、实验分析与商业智能等领域,其中部分应用已带来显著的收入增长。