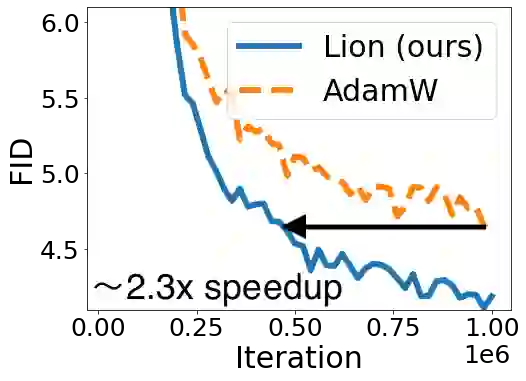
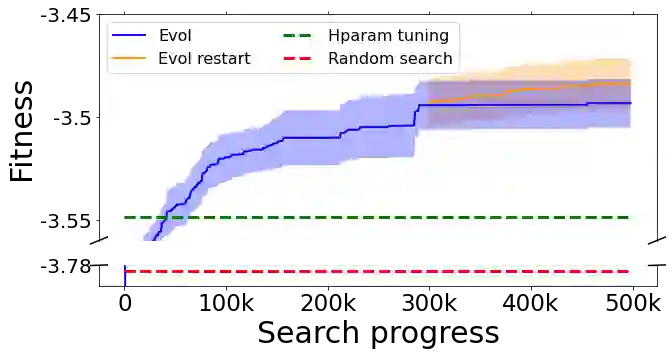
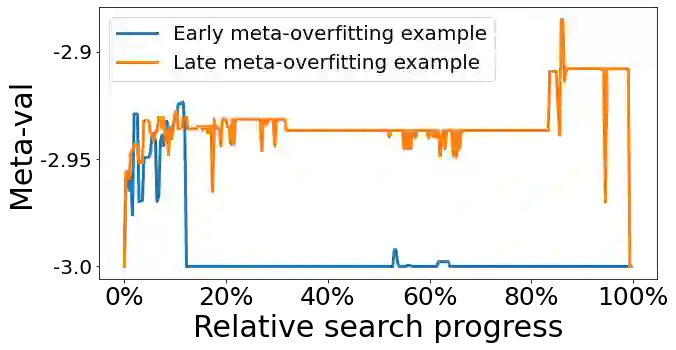
We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to explore an infinite and sparse program space. To bridge the large generalization gap between proxy and target tasks, we also introduce program selection and simplification strategies. Our method discovers a simple and effective optimization algorithm, $\textbf{Lion}$ ($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$). It is more memory-efficient than Adam as it only keeps track of the momentum. Different from adaptive optimizers, its update has the same magnitude for each parameter calculated through the sign operation. We compare Lion with widely used optimizers, such as Adam and Adafactor, for training a variety of models on different tasks. On image classification, Lion boosts the accuracy of ViT by up to 2% on ImageNet and saves up to 5x the pre-training compute on JFT. On vision-language contrastive learning, we achieve 88.3% $\textit{zero-shot}$ and 91.1% $\textit{fine-tuning}$ accuracy on ImageNet, surpassing the previous best results by 2% and 0.1%, respectively. On diffusion models, Lion outperforms Adam by achieving a better FID score and reducing the training compute by up to 2.3x. For autoregressive, masked language modeling, and fine-tuning, Lion exhibits a similar or better performance compared to Adam. Our analysis of Lion reveals that its performance gain grows with the training batch size. It also requires a smaller learning rate than Adam due to the larger norm of the update produced by the sign function. Additionally, we examine the limitations of Lion and identify scenarios where its improvements are small or not statistically significant. The implementation of Lion is publicly available.
翻译:我们提出了一种将算法发现形式化为程序搜索的方法,并将其应用于发现深度神经网络训练的优化算法。我们利用高效搜索技术探索无限且稀疏的程序空间。为了弥合代理任务与目标任务之间巨大的泛化差距,我们还引入了程序选择与简化策略。我们的方法发现了一种简单高效的优化算法——$\textbf{Lion}$($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$)。该算法比Adam更节省内存,因为仅需追踪动量。与自适应优化器不同,其通过符号操作计算的每个参数更新幅度相同。我们将Lion与广泛使用的优化器(如Adam和Adafactor)进行比较,在不同任务上训练多种模型。在图像分类任务中,Lion在ImageNet上将ViT的准确率提升高达2%,并在JFT上节省高达5倍的预训练计算量。在视觉-语言对比学习中,我们在ImageNet上达到了88.3%的$\textit{零样本}$和91.1%的$\textit{微调}$准确率,分别比此前最佳结果提升2%和0.1%。在扩散模型中,Lion通过获得更优的FID分数并将训练计算量降低高达2.3倍而优于Adam。对于自回归、掩码语言建模及微调任务,Lion表现与Adam相当或更优。我们对Lion的分析表明,其性能增益随训练批量大小增加而增长。同时,由于符号函数产生更大的更新范数,其所需学习率比Adam更小。此外,我们审视了Lion的局限性,并确定了其改进幅度较小或不具有统计显著性的场景。Lion的实现已公开发布。