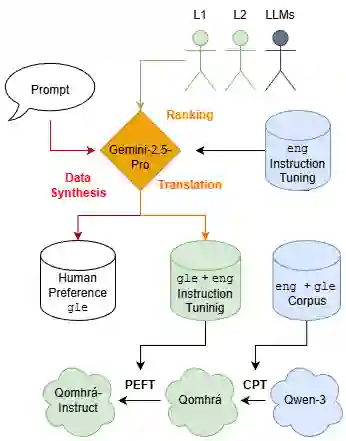
Large language model (LLM) research and development has overwhelmingly focused on the world's major languages, leading to under-representation of low-resource languages such as Irish. This paper introduces \textbf{Qomhrá}, a bilingual Irish and English LLM, developed under extremely low-resource constraints. A complete pipeline is outlined spanning bilingual continued pre-training, instruction tuning, and the synthesis of human preference data for future alignment training. We focus on the lack of scalable methods to create human preference data by proposing a novel method to synthesise such data by prompting an LLM to generate ``accepted'' and ``rejected'' responses, which we validate as aligning with L1 Irish speakers. To select an LLM for synthesis, we evaluate the top closed-weight LLMs for Irish language generation performance. Gemini-2.5-Pro is ranked highest by L1 and L2 Irish-speakers, diverging from LLM-as-a-judge ratings, indicating a misalignment between current LLMs and the Irish-language community. Subsequently, we leverage Gemini-2.5-Pro to translate a large scale English-language instruction tuning dataset to Irish and to synthesise a first-of-its-kind Irish-language human preference dataset. We comprehensively evaluate Qomhrá across several benchmarks, testing translation, gender understanding, topic identification, and world knowledge; these evaluations show gains of up to 29\% in Irish and 44\% in English compared to the existing open-source Irish LLM baseline, UCCIX. The results of our framework provide insight and guidance to developing LLMs for both Irish and other low-resource languages.
翻译:大语言模型(LLM)的研究与开发主要集中在世界主要语言上,导致如爱尔兰语等低资源语言代表性不足。本文介绍了 **Qomhrá**,一个在极低资源约束下开发的爱尔兰语与英语双语LLM。我们概述了一个完整的流程,涵盖双语持续预训练、指令微调以及为未来对齐训练合成人类偏好数据。针对缺乏可扩展方法创建人类偏好数据的问题,我们提出了一种新颖的合成方法:通过提示一个LLM生成“接受”和“拒绝”的响应,我们验证了该方法与爱尔兰语母语者的偏好一致。为选择用于合成的LLM,我们评估了顶尖闭源权重LLM在爱尔兰语生成任务上的性能。根据爱尔兰语母语者与第二语言使用者的评价,Gemini-2.5-Pro 排名最高,这与LLM-as-a-judge的评分存在差异,表明当前LLM与爱尔兰语社区之间存在偏差。随后,我们利用 Gemini-2.5-Pro 将大规模英语指令微调数据集翻译为爱尔兰语,并合成了首个爱尔兰语人类偏好数据集。我们在多个基准测试中对 Qomhrá 进行了全面评估,包括翻译、性别理解、主题识别和世界知识;这些评估显示,与现有的开源爱尔兰语LLM基线 UCCIX 相比,Qomhrá 在爱尔兰语任务上性能提升最高达29%,在英语任务上提升最高达44%。我们的框架结果为开发爱尔兰语及其他低资源语言的LLM提供了见解与指导。