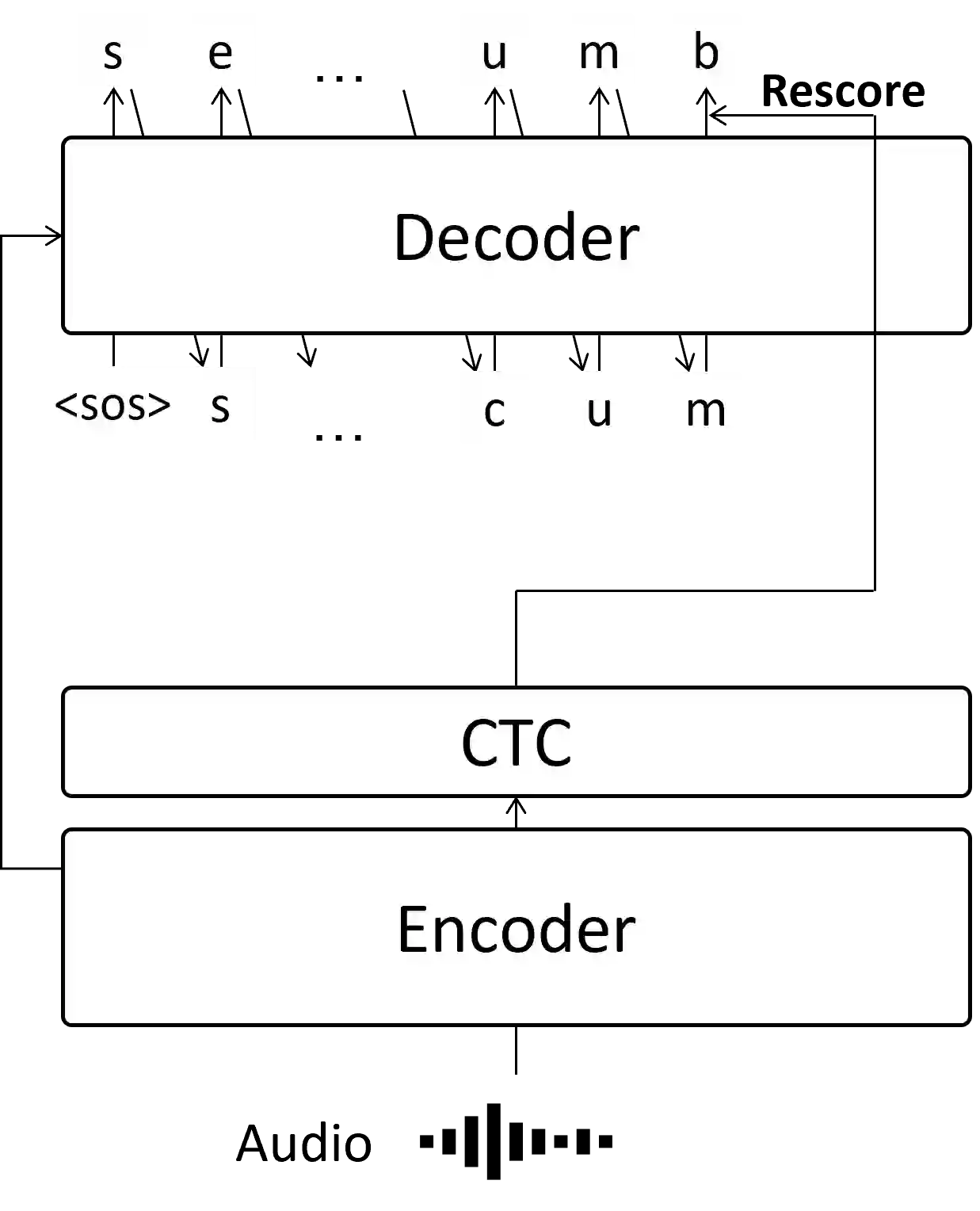
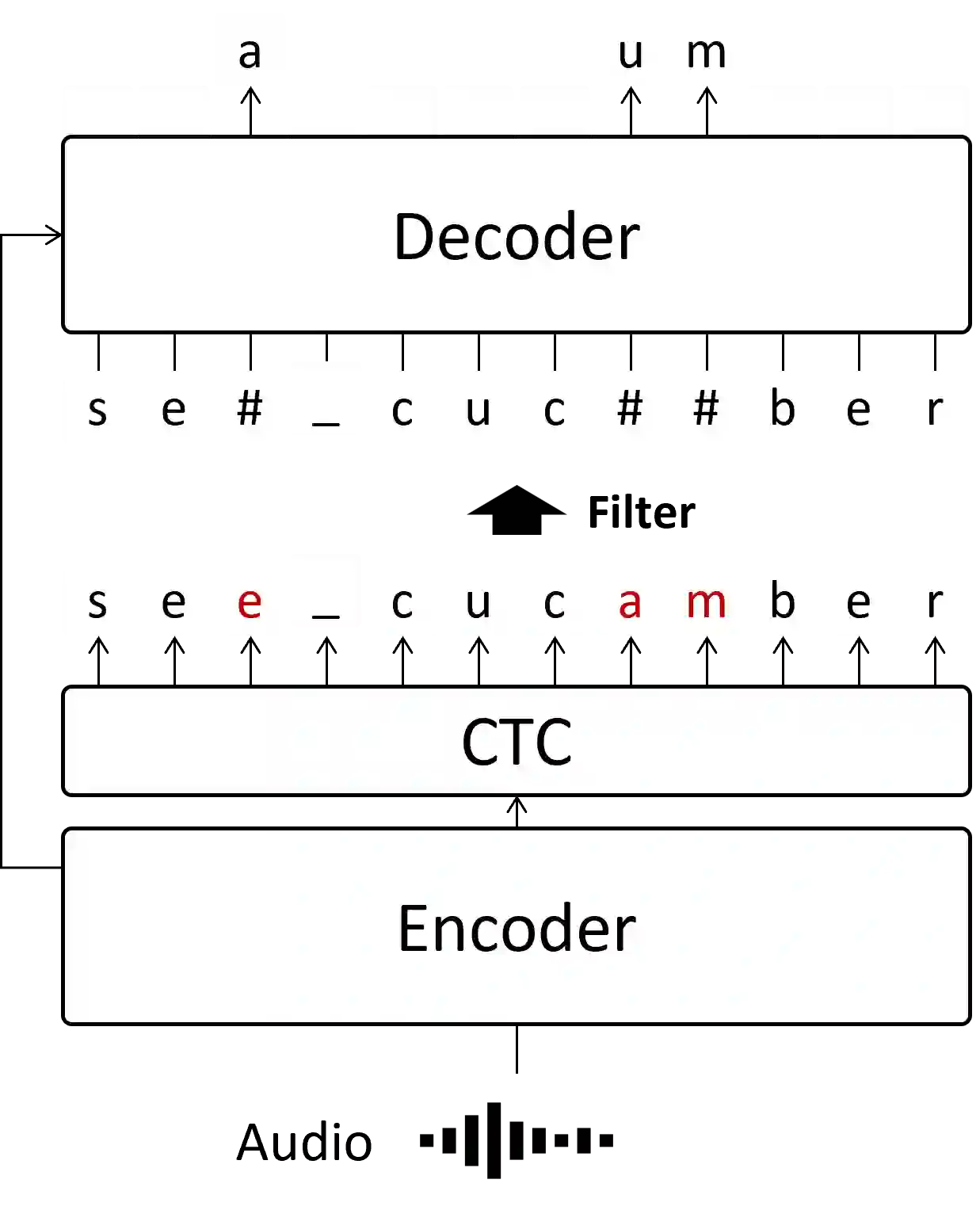
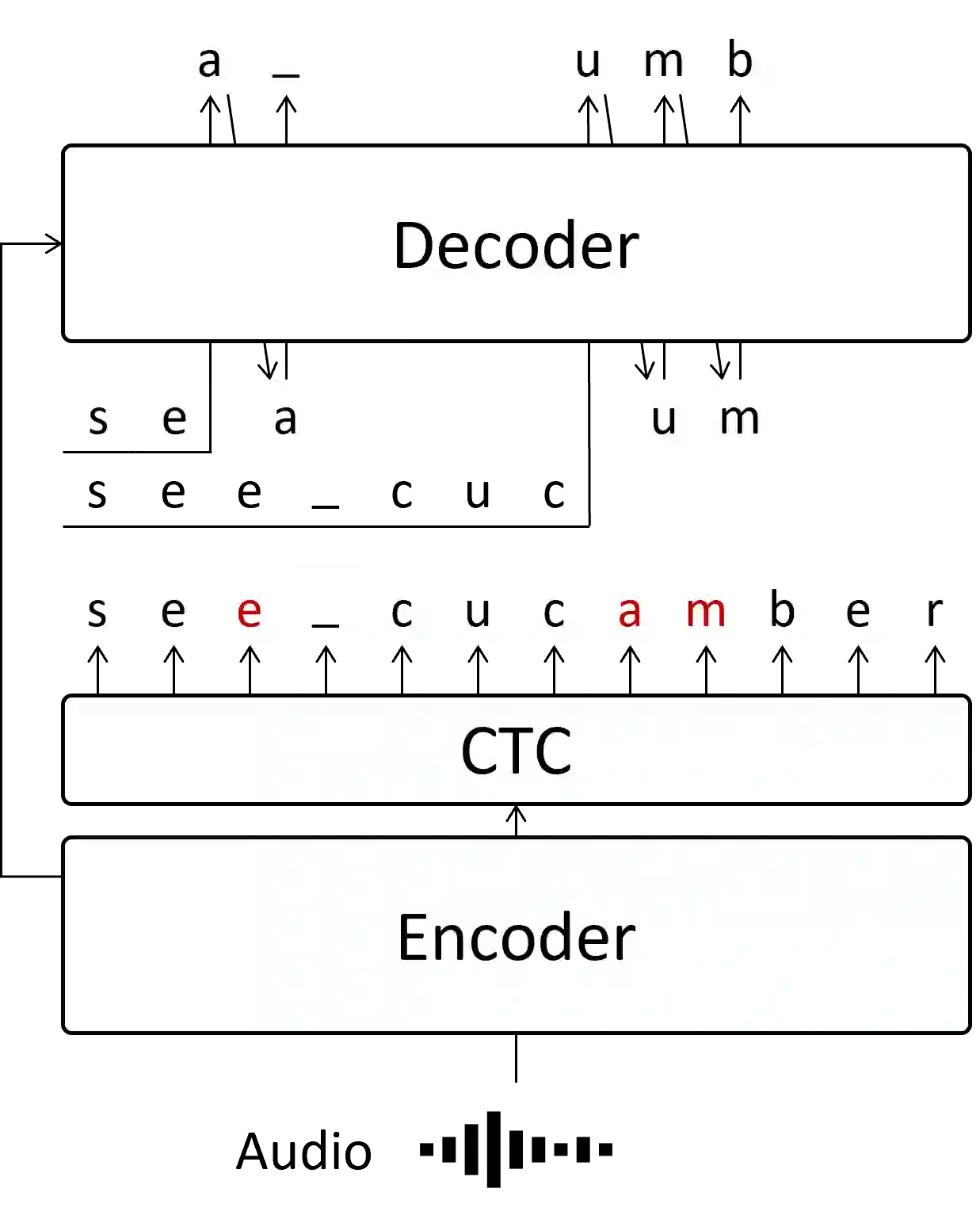
Attention-based encoder-decoder models with autoregressive (AR) decoding have proven to be the dominant approach for automatic speech recognition (ASR) due to their superior accuracy. However, they often suffer from slow inference. This is primarily attributed to the incremental calculation of the decoder. This work proposes a partially AR framework, which employs segment-level vectorized beam search for improving the inference speed of an ASR model based on the hybrid connectionist temporal classification (CTC) attention-based architecture. It first generates an initial hypothesis using greedy CTC decoding, identifying low-confidence tokens based on their output probabilities. We then utilize the decoder to perform segment-level vectorized beam search on these tokens, re-predicting in parallel with minimal decoder calculations. Experimental results show that our method is 12 to 13 times faster in inference on the LibriSpeech corpus over AR decoding whilst preserving high accuracy.
翻译:基于注意力机制的编码器-解码器模型凭借其卓越的准确率,已凭借自回归解码成为自动语音识别领域的主流方法,但其推理速度较慢,这主要归因于解码器的增量计算。本文提出一种部分自回归框架,采用段级向量化束搜索来提升基于混合连接主义时序分类与注意力机制的ASR模型的推理速度。该方法首先通过贪心CTC解码生成初始假设,并依据输出概率识别低置信度令牌,随后利用解码器对这些令牌进行段级向量化束搜索,以最少的解码计算量实现并行重新预测。实验结果表明,在LibriSpeech语料库上,本方法在保持高准确率的同时,推理速度相比自回归解码提升了12至13倍。