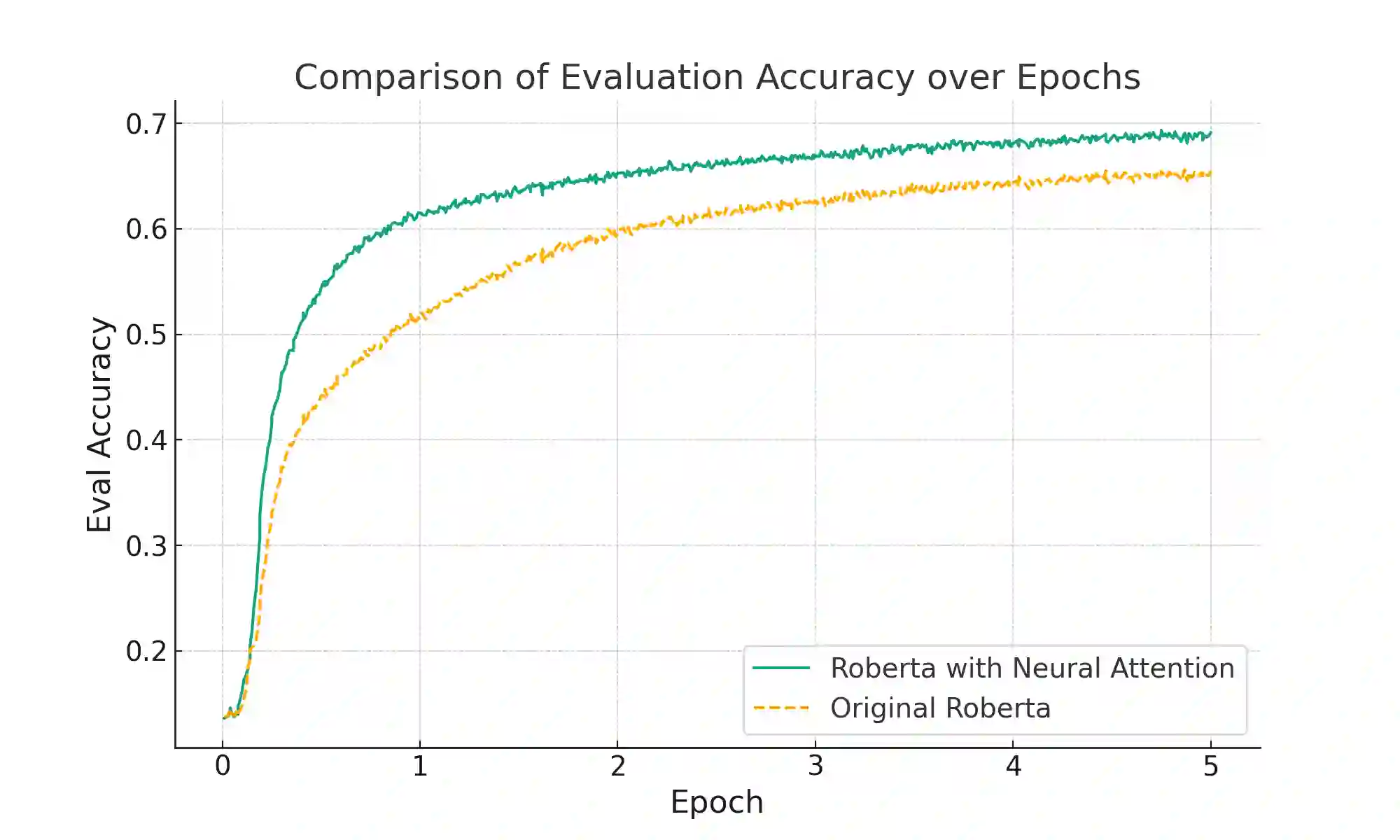
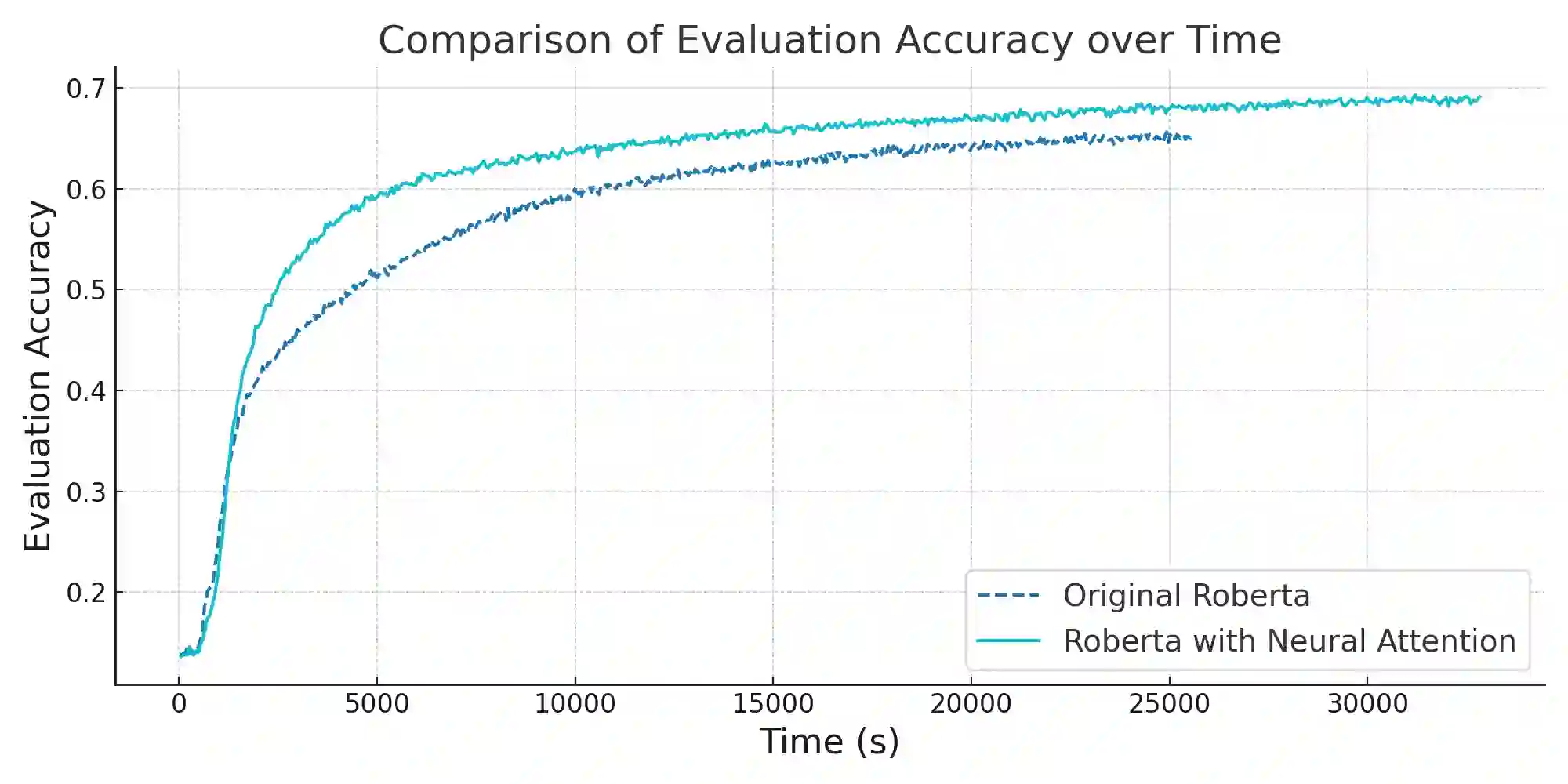
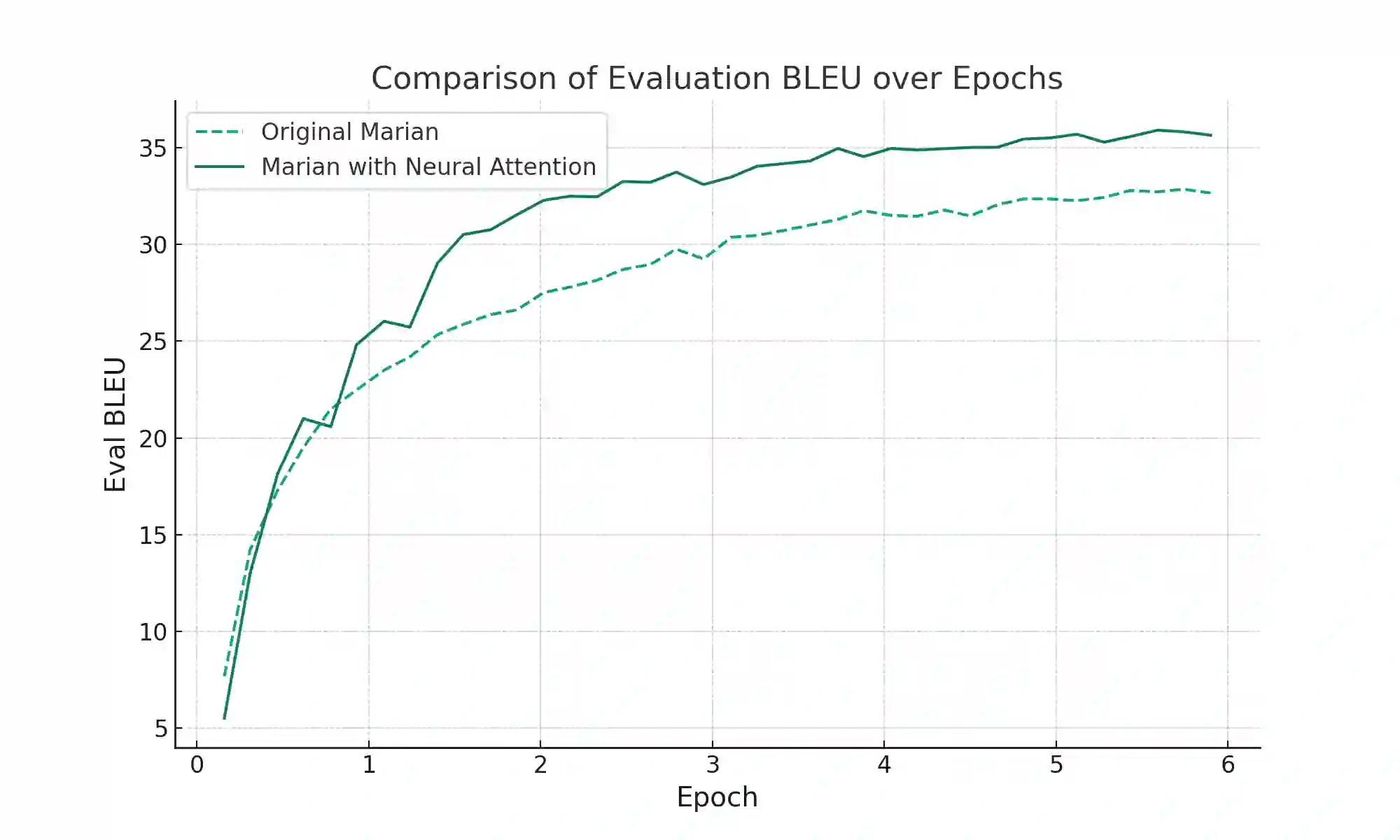
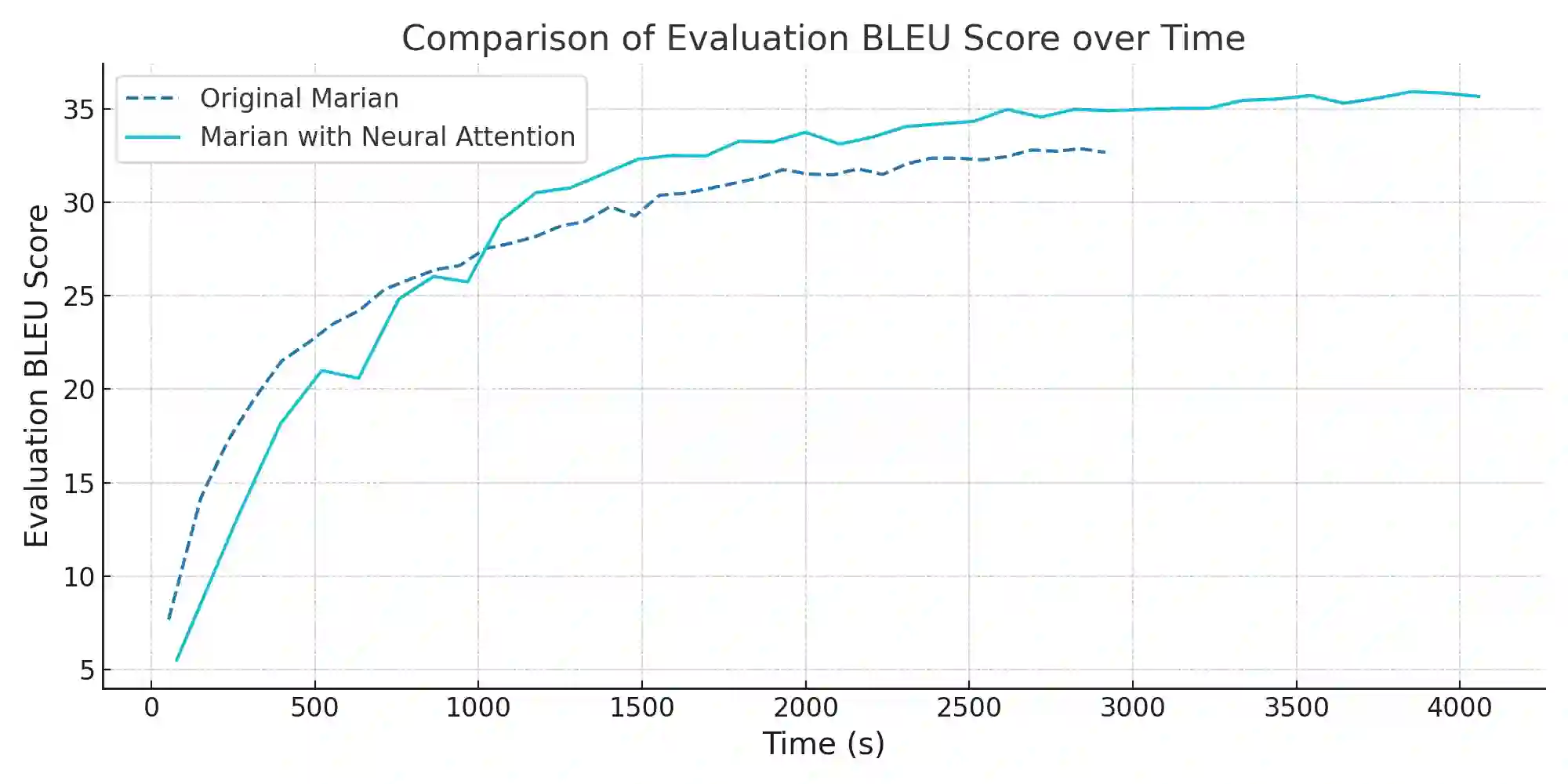
In the realm of deep learning, the self-attention mechanism has substantiated its pivotal role across a myriad of tasks, encompassing natural language processing and computer vision. Despite achieving success across diverse applications, the traditional self-attention mechanism primarily leverages linear transformations for the computation of query, key, and value (QKV), which may not invariably be the optimal choice under specific circumstances. This paper probes into a novel methodology for QKV computation-implementing a specially-designed neural network structure for the calculation. Utilizing a modified Marian model, we conducted experiments on the IWSLT 2017 German-English translation task dataset and juxtaposed our method with the conventional approach. The experimental results unveil a significant enhancement in BLEU scores with our method. Furthermore, our approach also manifested superiority when training the Roberta model with the Wikitext-103 dataset, reflecting a notable reduction in model perplexity compared to its original counterpart. These experimental outcomes not only validate the efficacy of our method but also reveal the immense potential in optimizing the self-attention mechanism through neural network-based QKV computation, paving the way for future research and practical applications. The source code and implementation details for our proposed method can be accessed at https://github.com/ocislyjrti/NeuralAttention.
翻译:在深度学习领域,自注意力机制已在自然语言处理和计算机视觉等众多任务中证实其关键作用。尽管传统自注意力机制在各种应用中取得了成功,但其主要依赖线性变换进行查询、键和值(QKV)的计算,这在特定情境下未必是最优选择。本文探究了一种新颖的QKV计算方法——采用专门设计的神经网络结构进行计算。通过修改Marian模型,我们在IWSLT 2017德英翻译任务数据集上进行了实验,并将我们的方法与常规方法进行了对比。实验结果显示,我们的方法显著提升了BLEU分数。此外,在使用Wikitext-103数据集训练Roberta模型时,我们的方法也展现出优越性,与原始模型相比,模型困惑度显著降低。这些实验结果不仅验证了我们方法的有效性,还揭示了通过基于神经网络的QKV计算优化自注意力机制的巨大潜力,为未来的研究和实际应用铺平了道路。我们提出方法的源代码和实现细节可在https://github.com/ocislyjrti/NeuralAttention查阅。