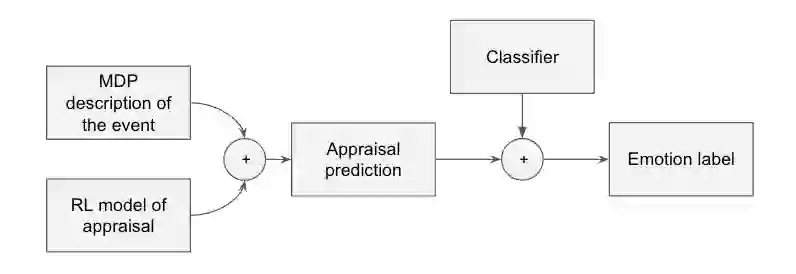
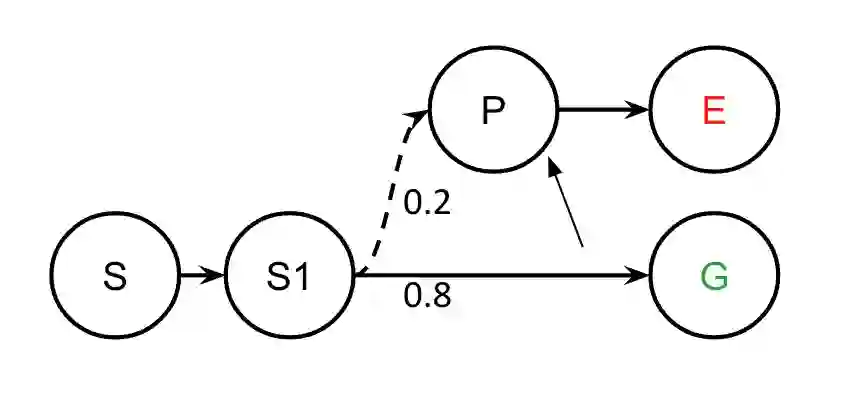
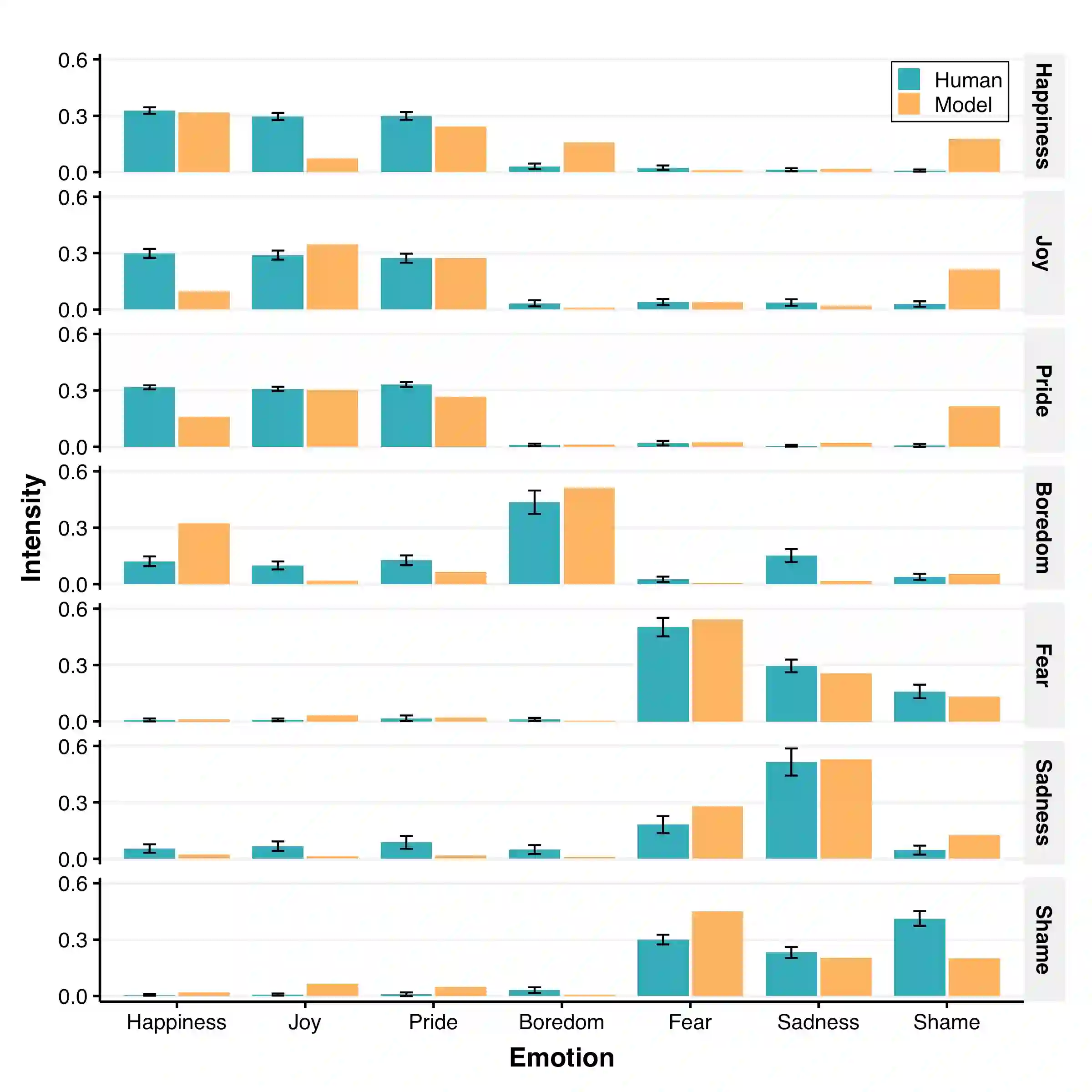
Computational models can advance affective science by shedding light onto the interplay between cognition and emotion from an information processing point of view. We propose a computational model of emotion that integrates reinforcement learning (RL) and appraisal theory, establishing a formal relationship between reward processing, goal-directed task learning, cognitive appraisal and emotional experiences. The model achieves this by formalizing evaluative checks from the component process model (CPM) in terms of temporal difference learning updates. We formalized novelty, goal relevance, goal conduciveness, and power. The formalization is task independent and can be applied to any task that can be represented as a Markov decision problem (MDP) and solved using RL. We investigated to what extent CPM-RL enables simulation of emotional responses cased by interactive task events. We evaluate the model by predicting a range of human emotions based on a series of vignette studies, highlighting its potential in improving our understanding of the role of reward processing in affective experiences.
翻译:计算模型能够通过信息处理视角揭示认知与情感的相互作用,从而推动情感科学的发展。我们提出了一种融合强化学习与评价理论的情感计算模型,建立了奖赏处理、目标导向任务学习、认知评价与情感体验之间的形式化关系。该模型利用时序差分学习更新将成分过程模型的评价检验进行形式化,具体实现了新颖性、目标相关性、目标促进性及掌控力等评价维度。这种形式化方法独立于具体任务,可应用于任何能表示为马尔可夫决策过程并采用强化学习求解的任务。我们探究了CPM-RL模型在多大程度上能够模拟交互式任务事件引发的情感响应,并通过系列情境研究预测人类情感类别来评估模型效果,突显其在增进对奖赏处理在情感体验中作用的理解方面的潜力。