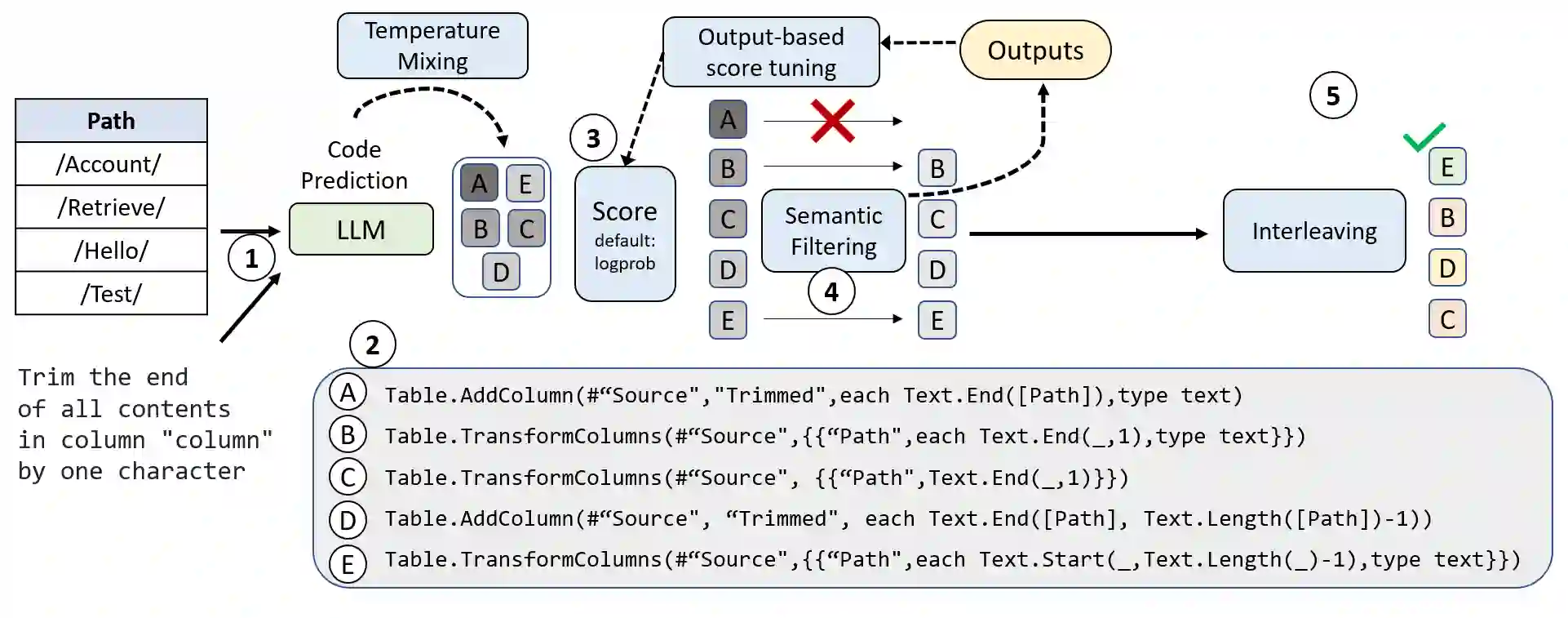
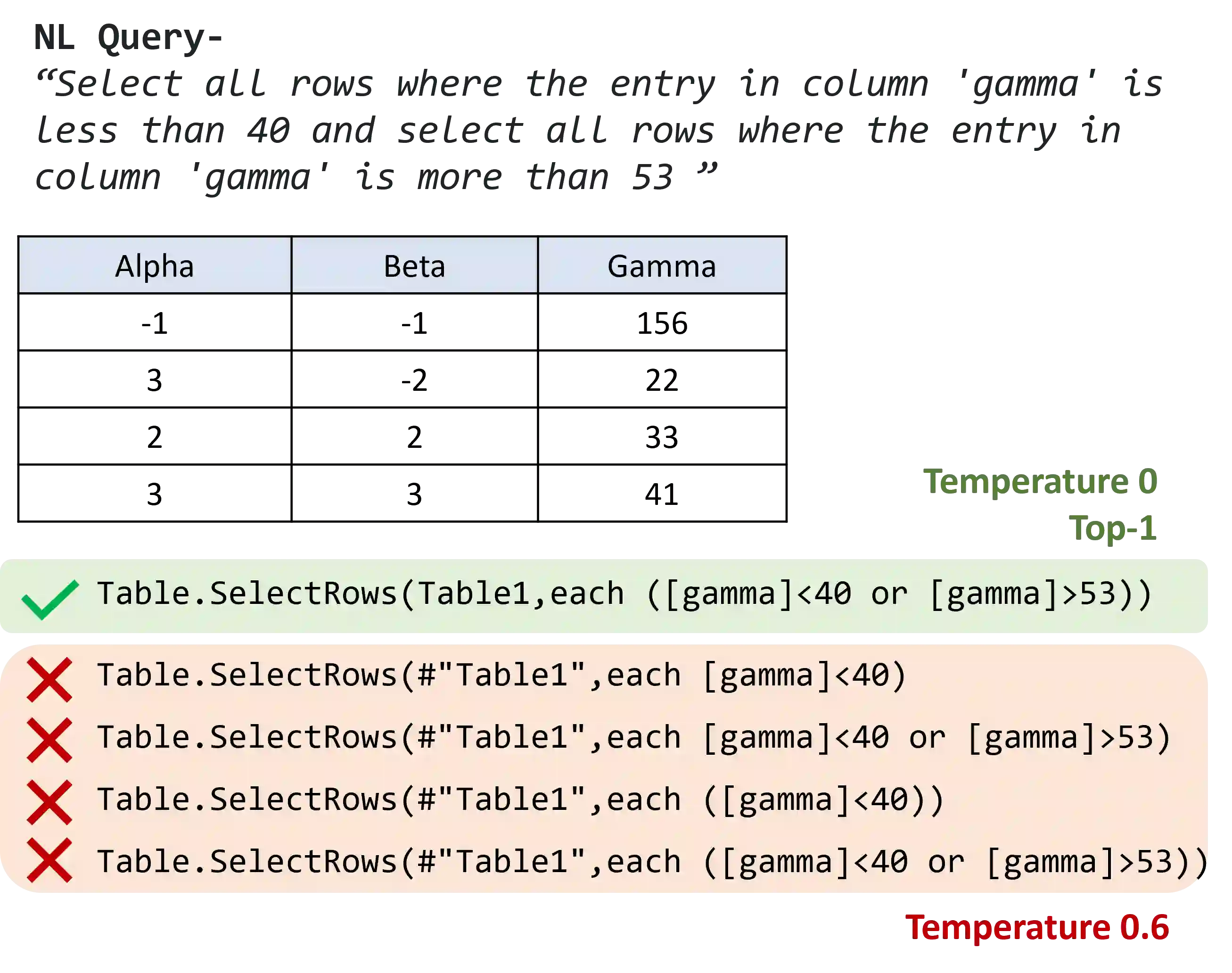
Creating programs to correctly manipulate data is a difficult task, as the underlying programming languages and APIs can be challenging to learn for many users who are not skilled programmers. Large language models (LLMs) demonstrate remarkable potential for generating code from natural language, but in the data manipulation domain, apart from the natural language (NL) description of the intended task, we also have the dataset on which the task is to be performed, or the "data context". Existing approaches have utilized data context in a limited way by simply adding relevant information from the input data into the prompts sent to the LLM. In this work, we utilize the available input data to execute the candidate programs generated by the LLMs and gather their outputs. We introduce semantic reranking, a technique to rerank the programs generated by LLMs based on three signals coming the program outputs: (a) semantic filtering and well-formedness based score tuning: do programs even generate well-formed outputs, (b) semantic interleaving: how do the outputs from different candidates compare to each other, and (c) output-based score tuning: how do the outputs compare to outputs predicted for the same task. We provide theoretical justification for semantic interleaving. We also introduce temperature mixing, where we combine samples generated by LLMs using both high and low temperatures. We extensively evaluate our approach in three domains, namely databases (SQL), data science (Pandas) and business intelligence (Excel's Power Query M) on a variety of new and existing benchmarks. We observe substantial gains across domains, with improvements of up to 45% in top-1 accuracy and 34% in top-3 accuracy.
翻译:创建能够正确操作数据的程序是一项艰巨的任务,因为底层编程语言和API对于许多非专业程序员用户而言学习难度较大。大型语言模型(LLM)展现出从自然语言生成代码的显著潜力,但在数据操作领域,除任务意图的自然语言描述外,我们还需处理待执行任务的数据集,即"数据上下文"。现有方法仅通过将输入数据中的相关信息简单附加到LLM提示中,以有限方式利用数据上下文。本研究利用可用输入数据执行LLM生成的候选程序,并收集其输出结果。我们提出语义重排序技术,基于程序输出产生的三种信号对LLM生成的程序进行重新排序:(a)语义过滤与良构性评分调整——程序是否能生成规范输出;(b)语义交错——不同候选程序的输出结果相互比较情况;(c)基于输出的评分调整——输出结果与同一任务预测输出的比较。我们为语义交错提供了理论依据,并提出温度混合策略,结合使用高低温条件生成的LLM样本。我们在数据库(SQL)、数据科学(Pandas)和商业智能(Excel的Power Query M)三个领域,基于多种新旧基准进行了全面评估。观察到各领域均有显著提升,其中Top-1准确率提升高达45%,Top-3准确率提升达34%。