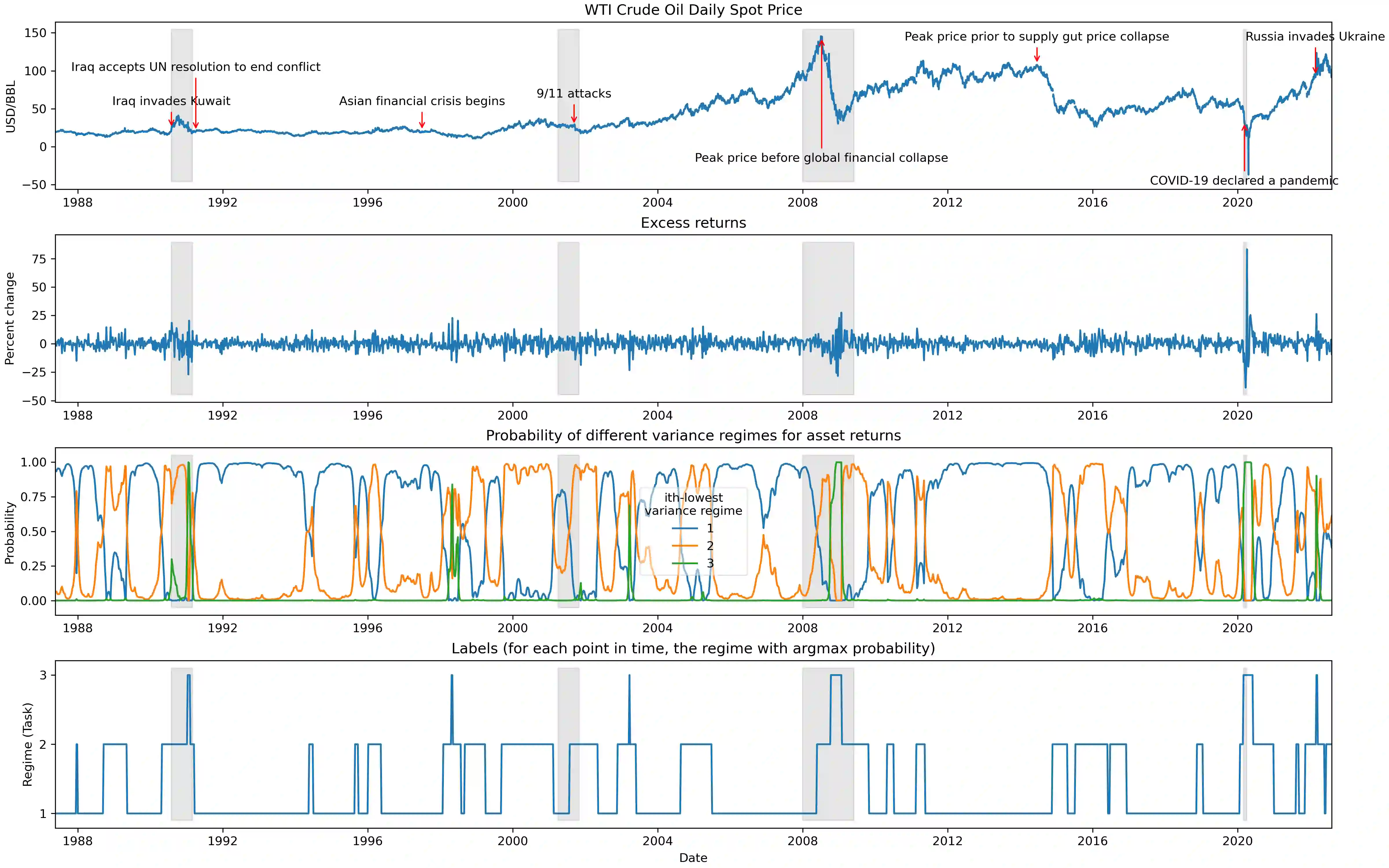
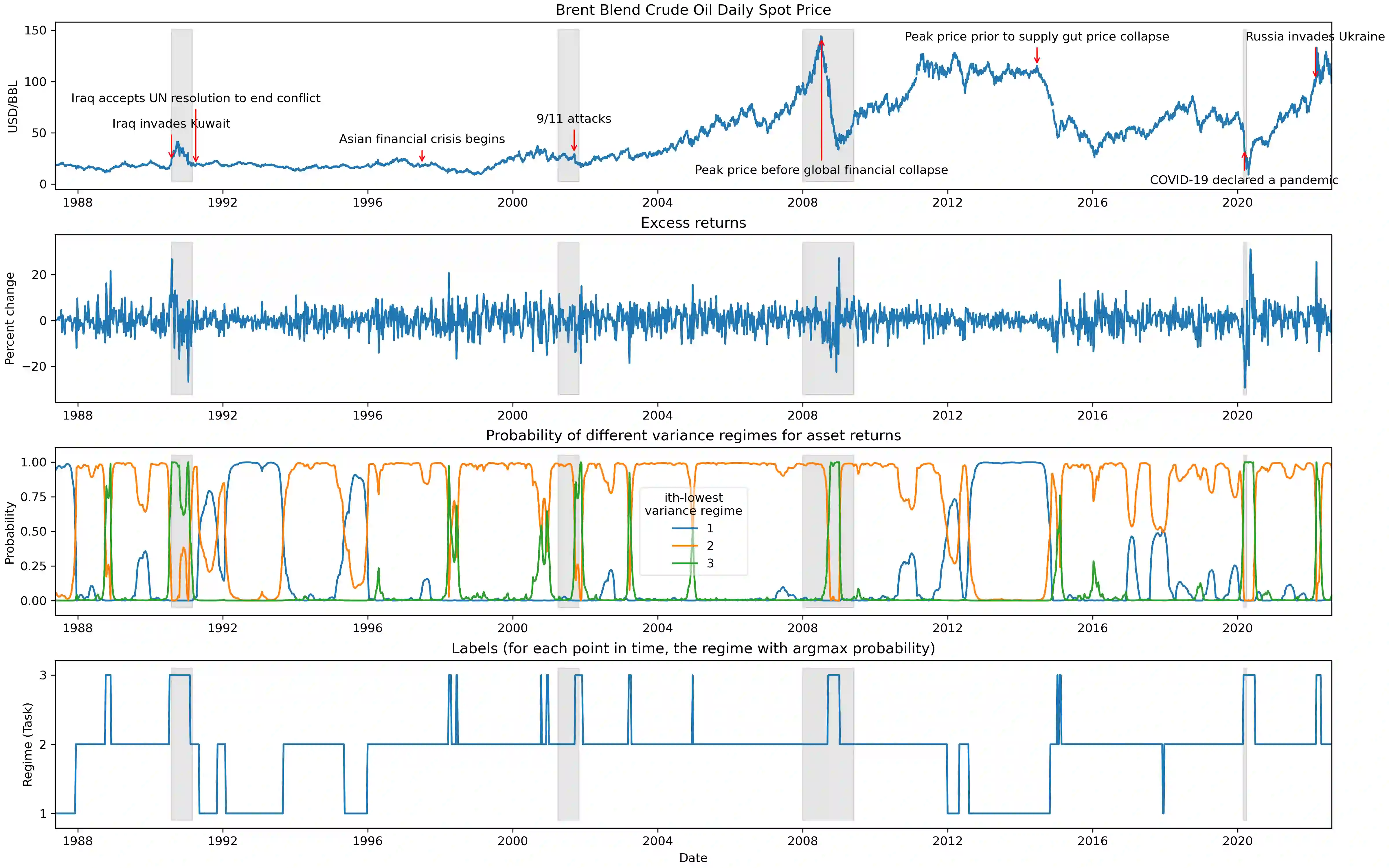
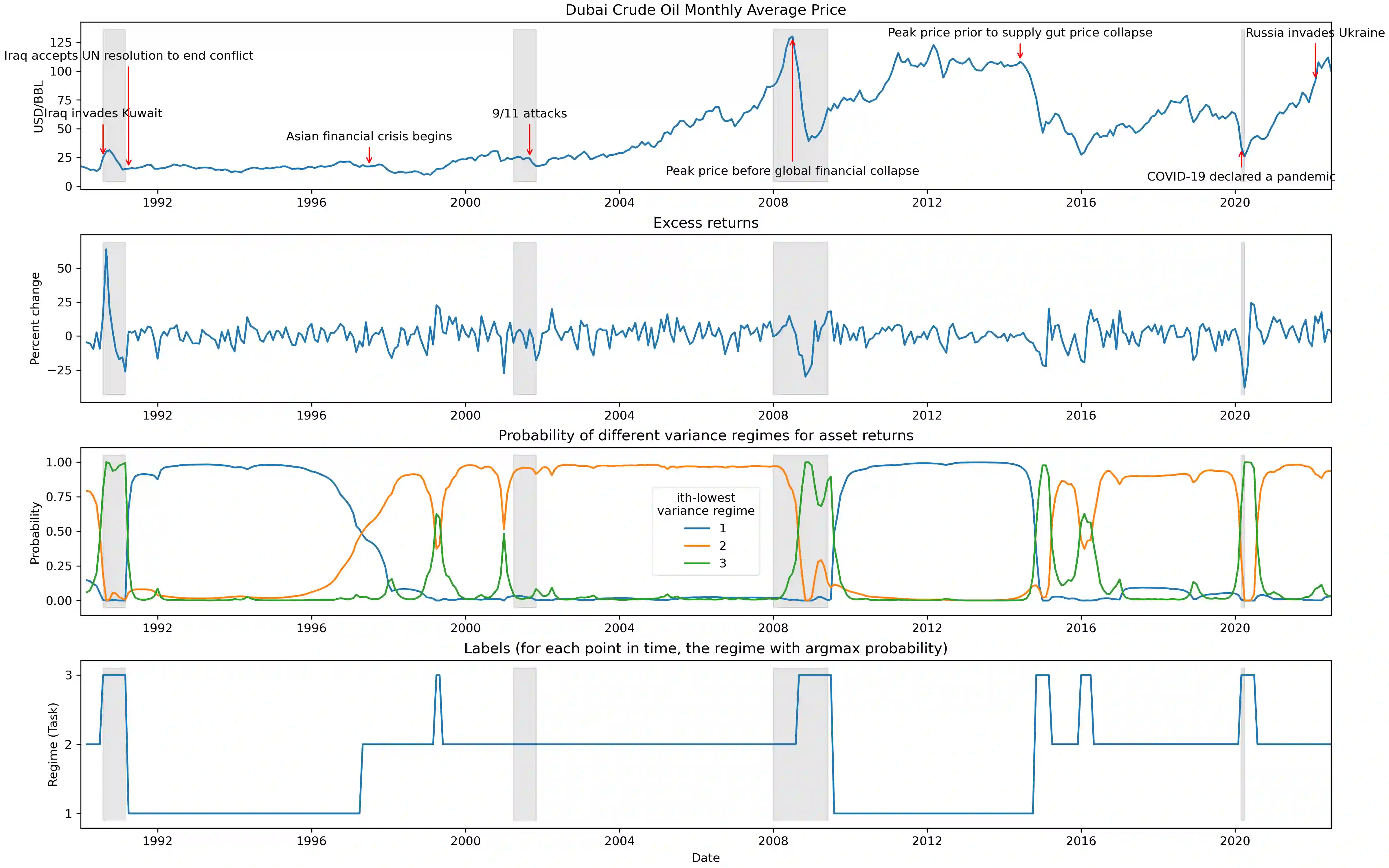
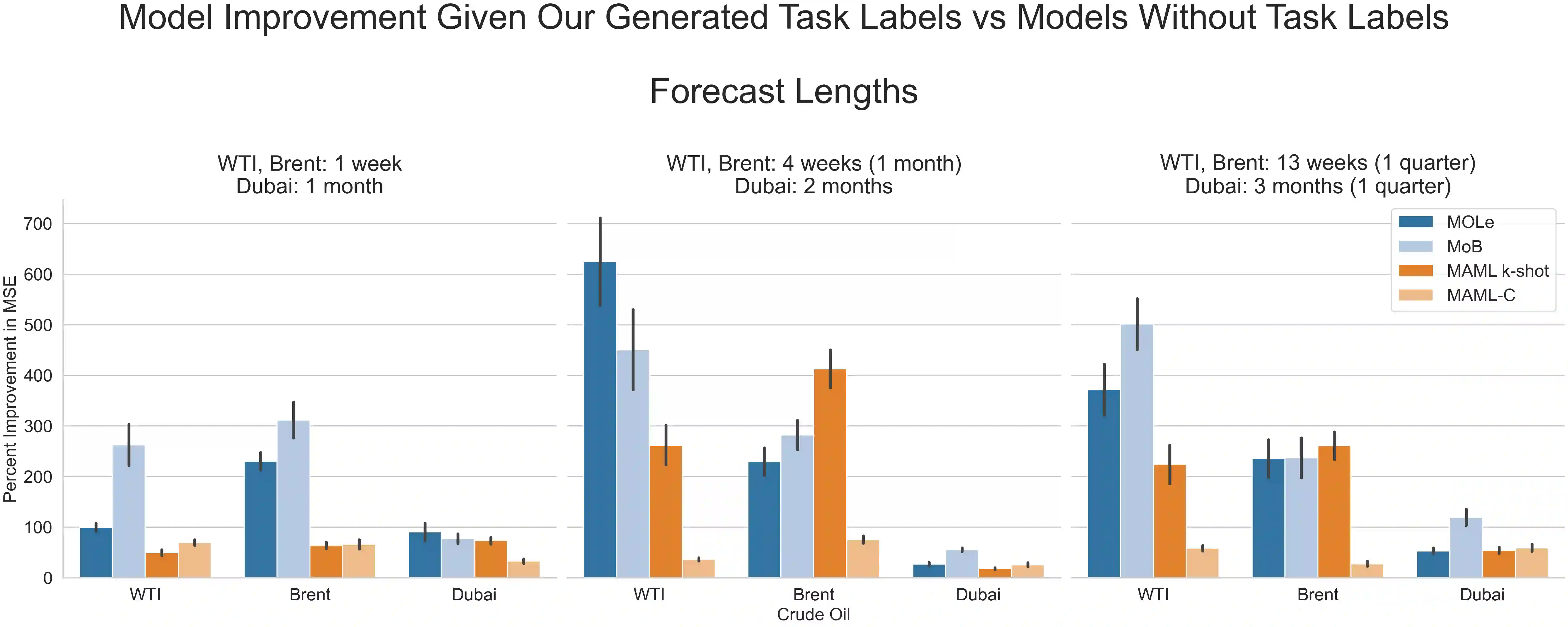
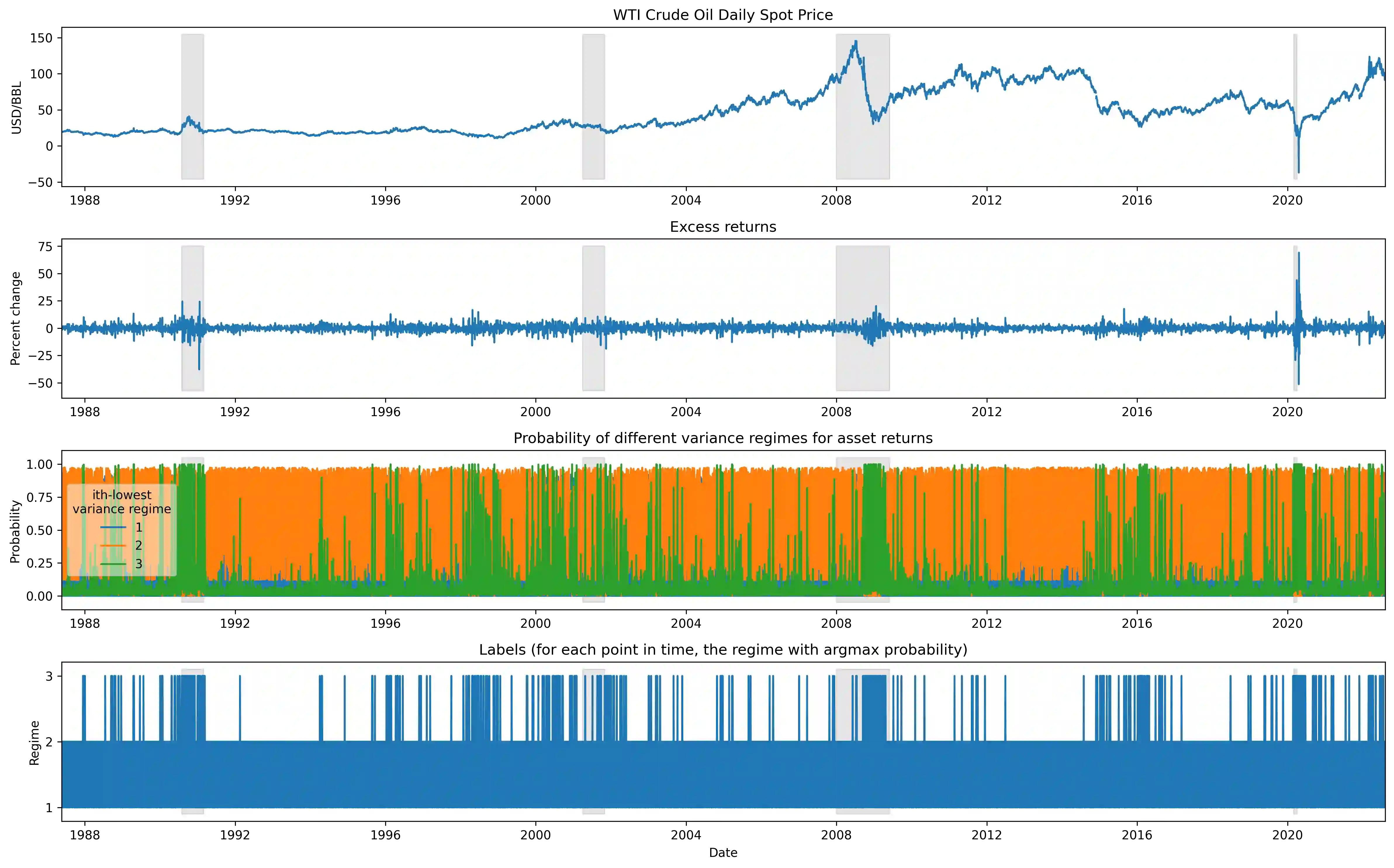
The scarcity of task-labeled time-series benchmarks in the financial domain hinders progress in continual learning. Addressing this deficit would foster innovation in this area. Therefore, we present COB, Crude Oil Benchmark datasets. COB includes 30 years of asset prices that exhibit significant distribution shifts and optimally generates corresponding task (i.e., regime) labels based on these distribution shifts for the three most important crude oils in the world. Our contributions include creating real-world benchmark datasets by transforming asset price data into volatility proxies, fitting models using expectation-maximization (EM), generating contextual task labels that align with real-world events, and providing these labels as well as the general algorithm to the public. We show that the inclusion of these task labels universally improves performance on four continual learning algorithms, some state-of-the-art, over multiple forecasting horizons. We hope these benchmarks accelerate research in handling distribution shifts in real-world data, especially due to the global importance of the assets considered. We've made the (1) raw price data, (2) task labels generated by our approach, (3) and code for our algorithm available at https://oilpricebenchmarks.github.io.
翻译:金融领域中任务标注时间序列基准数据的稀缺,阻碍了持续学习领域的进展。弥补这一缺陷将推动该领域的创新发展。为此,我们提出原油基准数据集COB。该数据集包含30年资产价格数据,呈现显著分布漂移特征,并基于这些分布漂移为全球最重要的三种原油优化生成对应的任务(即状态)标签。我们的贡献包括:将资产价格数据转换为波动率代理指标以构建真实世界基准数据集;使用期望最大化(EM)算法拟合模型;生成与真实世界事件对应的上下文任务标签;以及向公众提供这些标签及通用算法。研究表明,在多种预测时间跨度下,将任务标签引入四种持续学习算法(包括最新方法)可普遍提升性能。我们期望该基准能加速处理真实世界数据分布漂移的研究——尤其是考虑到所选资产的全球重要性。原始价格数据、基于本方法生成的任务标签及算法代码均可在https://oilpricebenchmarks.github.io 获取。