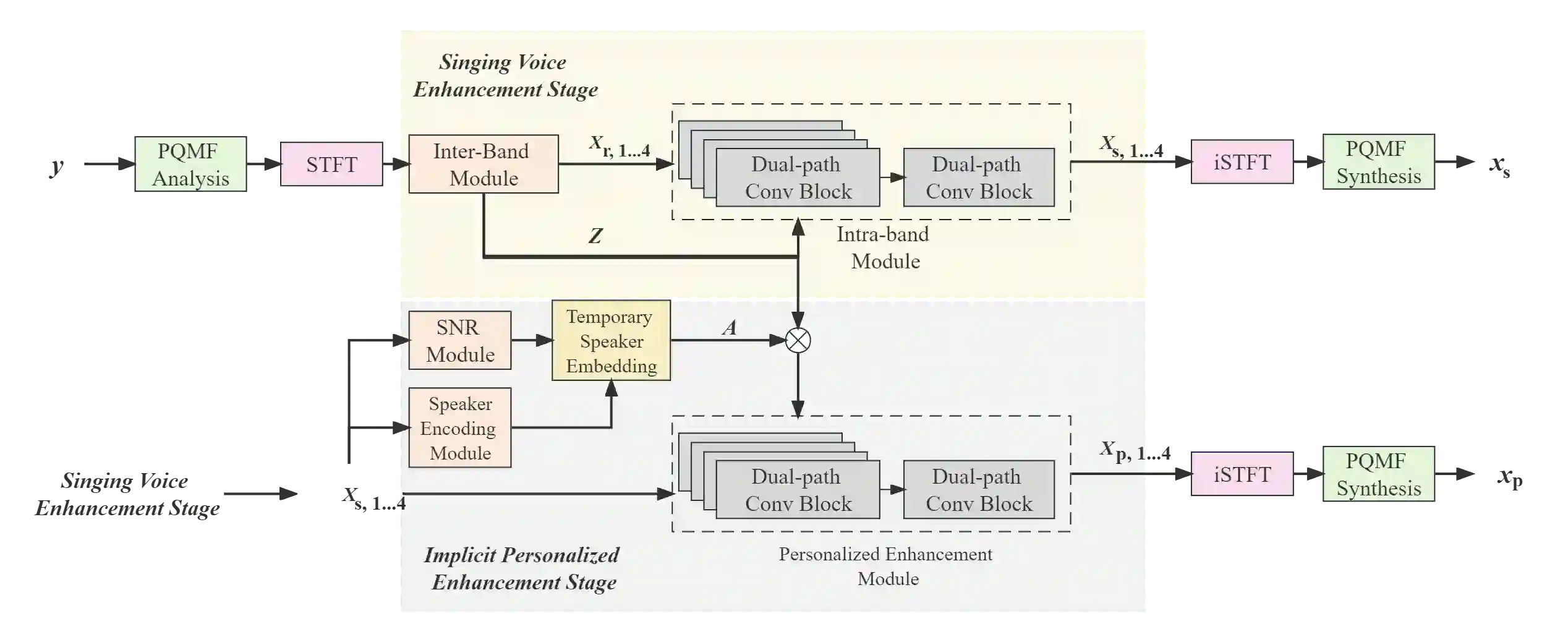
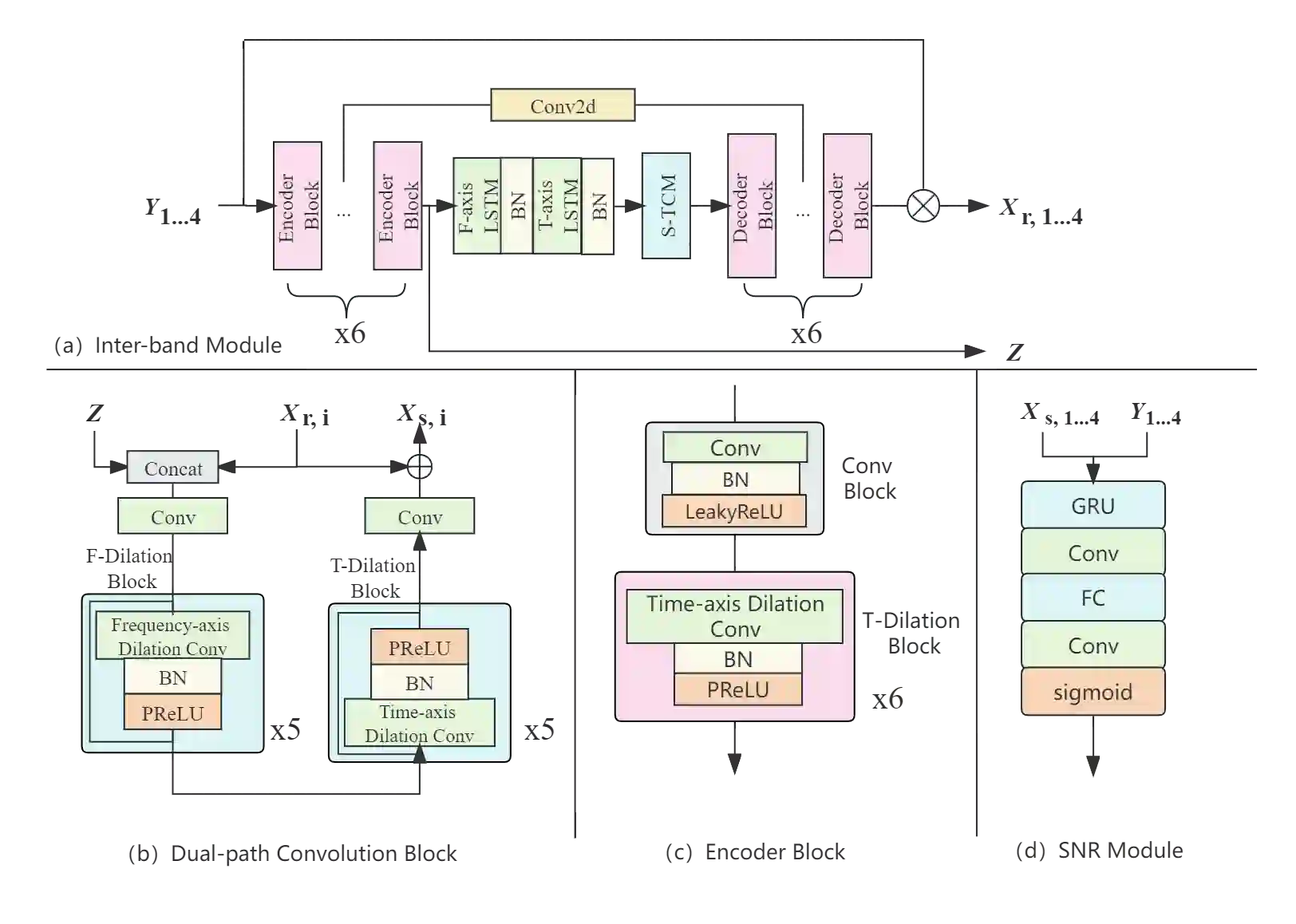
A typical neural speech enhancement (SE) approach mainly handles speech and noise mixtures, which is not optimal for singing voice enhancement scenarios. Music source separation (MSS) models treat vocals and various accompaniment components equally, which may reduce performance compared to the model that only considers vocal enhancement. In this paper, we propose a novel multi-band temporal-frequency neural network (MBTFNet) for singing voice enhancement, which particularly removes background music, noise and even backing vocals from singing recordings. MBTFNet combines inter and intra-band modeling for better processing of full-band signals. Dual-path modeling are introduced to expand the receptive field of the model. We propose an implicit personalized enhancement (IPE) stage based on signal-to-noise ratio (SNR) estimation, which further improves the performance of MBTFNet. Experiments show that our proposed model significantly outperforms several state-of-the-art SE and MSS models.
翻译:典型的神经语音增强方法主要处理语音与噪声的混合信号,这在歌声增强场景中并非最优。音乐源分离模型将人声与各类伴奏成分同等处理,相较于仅专注于人声增强的模型,其性能可能下降。本文提出一种新颖的多频带时频神经网络(MBTFNet)用于歌声增强,该网络能够从歌唱录音中特别移除背景音乐、噪声乃至伴唱人声。MBTFNet通过融合频带间与频带内建模技术,实现对全频带信号的更优处理。引入双路径建模以扩展模型的感受野。我们基于信噪比估计提出隐式个性化增强阶段,进一步提升了MBTFNet的性能。实验表明,我们的模型在多项指标上显著优于当前先进的语音增强与音乐源分离模型。