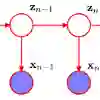
The Hidden Markov Model (HMM) is one of the most widely used statistical models for sequential data analysis. One of the key reasons for this versatility is the ability of HMM to deal with missing data. However, standard HMM learning algorithms rely crucially on the assumption that the positions of the missing observations \emph{within the observation sequence} are known. In the natural sciences, where this assumption is often violated, special variants of HMM, commonly known as Silent-state HMMs (SHMMs), are used. Despite their widespread use, these algorithms strongly rely on specific structural assumptions of the underlying chain, such as acyclicity, thus limiting the applicability of these methods. Moreover, even in the acyclic case, it has been shown that these methods can lead to poor reconstruction. In this paper we consider the general problem of learning an HMM from data with unknown missing observation locations. We provide reconstruction algorithms that do not require any assumptions about the structure of the underlying chain, and can also be used with limited prior knowledge, unlike SHMM. We evaluate and compare the algorithms in a variety of scenarios, measuring their reconstruction precision, and robustness under model miss-specification. Notably, we show that under proper specifications one can reconstruct the process dynamics as well as if the missing observations positions were known.
翻译:隐马尔可夫模型是序贯数据分析中最广泛使用的统计模型之一。这种通用性的关键原因在于HMM能够处理缺失数据。然而,标准的HMM学习算法严重依赖于缺失观测在观测序列中的位置已知这一假设。在自然科学领域,这一假设常被违反,因此通常使用HMM的特殊变体——静默状态HMM。尽管这些算法应用广泛,但它们严重依赖于底层链的特定结构假设(如无环性),从而限制了这些方法的适用性。此外,即使在无环情况下,已有研究表明这些方法可能导致较差的模型重构效果。本文考虑从缺失观测位置未知的数据中学习HMM的一般性问题。我们提出的重构算法既不需要对底层链结构作任何假设,也能在有限先验知识条件下使用(此点与SHMM不同)。我们在多种场景下评估并比较了这些算法的重构精度及模型设定错误下的鲁棒性。值得注意的是,我们证明在合理设定下,算法能够重构过程动态,其效果与已知缺失观测位置时相当。